
Une « epoch » ou « époque » de Machine Learning désigne un passage complet du jeu de données d'entraînement par l'algorithme. Découvrez tout ce que vous devez savoir sur cette notion essentielle de l'apprentissage automatique.
Dans le domaine de l’intelligence artificielle, le Machine Learning consiste à laisser un modèle apprendre et s’entraîner à partir de données grâce à un algorithme. Cette méthode s’inspire de la façon dont le cerveau humain apprend, et repose d’ailleurs sur des réseaux de neurones artificiels.
Toutefois, alors qu’un humain a besoin de plusieurs années pour apprendre, grâce à des techniques comme l’entraînement parallèle, un modèle peut s’entraîner pendant l’équivalent de plusieurs décennies en seulement quelques heures.
D’ailleurs, chaque fois que le dataset d’entraînement passe par l’algorithme, on dit qu’il a complété une « époque » ou « epoch » en anglais. Il s’agit d’un hyperparamètre, déterminant le processus d’entraînement du modèle de Machine Learning.
Qu'est-ce qu'une Epoch ?
Un cycle complet du jeu de données d’entraînement est considéré comme une « époque » dans le domaine du Machine Learning. Elle reflète le nombre de passages de l’algorithme au cours de la phase d’entraînement.
On peut définir une epoch comme le nombre de passages d’un dataset d’entraînement par un algorithme. Un passage équivaut à un aller-retour.
Le nombre d’epochs peut atteindre plusieurs milliers, car la procédure se répète indéfiniment jusqu’à ce que le taux d’erreurs du modèle soit suffisamment réduit.
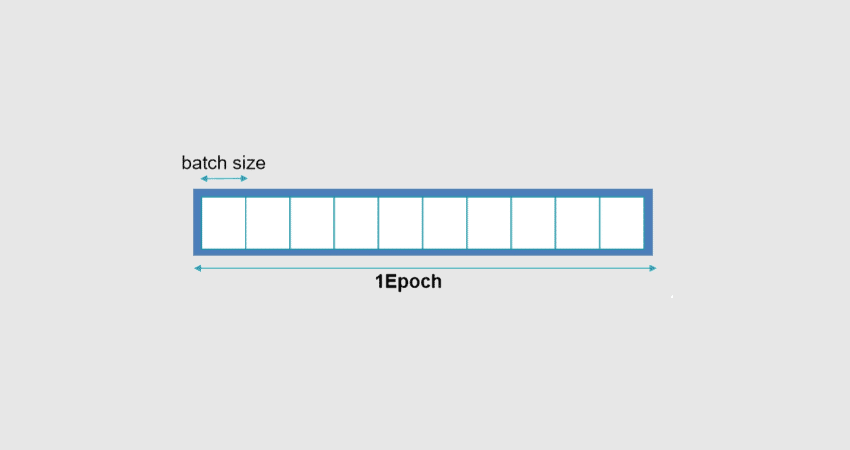
Une époque est composée d’une agrégation de « batches » ou « lots » de données et d’itérations. Les jeux de données sont généralement décomposés en batches, tout particulièrement lorsque le volume de données est massif.

Qu'est-ce qu'une itération ?
Dans le domaine du Machine Learning, une itération indique le nombre de fois que les paramètres d’un algorithme sont modifiés. Les implications spécifiques dépendent du contexte.
En général, une itération d’entraînement d’un réseau de neurones inclut le « batch processing » ou traitement de lot du dataset, le calcul de la fonction de coût, la modification et la rétropropagation de tous les facteurs de poids.
L’itération et l’époque sont souvent confondues à tort. En réalité, une itération implique le traitement d’un batch tandis qu’une époque désigne le traitement de toutes les données du dataset.
Par exemple, si une itération traite 10 images d’un ensemble de 1000 images avec une taille de batch de 10, il faudra 100 itérations pour terminer une époque.
Qu'est-ce qu'un batch ?
Les données d’entraînement sont décomposées en plusieurs petits « lots » ou « batches » en anglais. Le but est d’éviter les problèmes liés à un manque d’espace de stockage.
Les batches peuvent être facilement utilisés pour nourrir le modèle de Machine Learning afin de l’entraîner. Ce processus de décomposition du dataset est appelé « batch ».
Une epoch peut être composée d’un batch ou davantage. Le nombre d’échantillons d’entraînement utilisés lors d’une itération est la « taille de lot » ou « batch size ». On distingue trois possibilités.
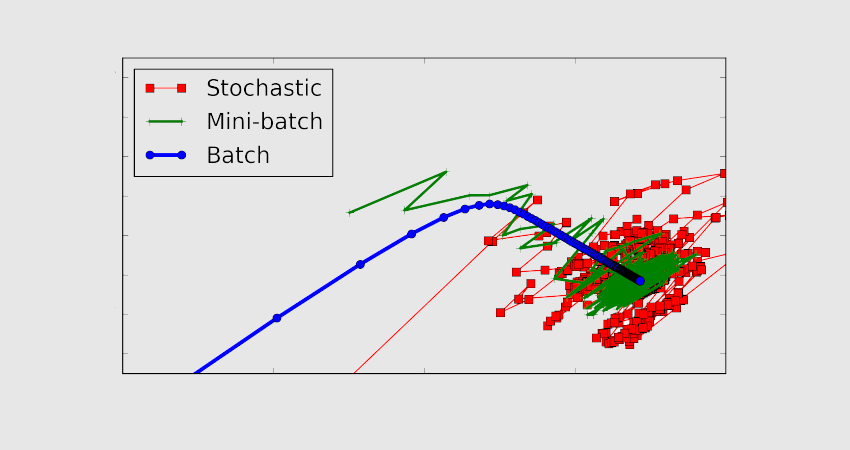
Dans le cas du « Batch Mode », les valeurs d’itération et d’époque sont égales puisque la taille du batch est égale au dataset complet. Une itération équivaut donc à une époque.
En « mini-batch mode », la taille du dataset complet est inférieure à la taille de batch. Par conséquent un seul batch est plus large que le jeu de données d’entraînement.
Enfin, en mode stochastique, la taille du batch est unique. Par conséquent, le gradient et les paramètres du réseau de neurones sont changés à chaque échantillon.
Qu'est-ce que l'algorithme du gradient stochastique ?
L’algorithme du gradient stochastique ou stochastic gradient descent (SGD) est un algorithme d’optimisation. Il est utilisé par les réseaux de neurones dans le domaine du Deep Learning, afin d’entraîner les algorithmes de Machine Learning.
Le rôle de cet algorithme est d’identifier un ensemble de paramètres internes de modèle dépassant les autres mesures de performances comme l’erreur quadratique ou la perte de logarithme.
L’optimisation peut être décrite comme un processus de recherche impliquant l’apprentissage. L’algorithme d’optimisation est appelé descente graduelle, et repose sur le calcul d’un gradient d’erreur ou pente d’erreur devant être descendue en direction du niveau d’erreur minimum.
Cet algorithme permet d’exécuter le processus de recherche à de multiples reprises. Le but est d’améliorer les paramètres du modèle à chaque étape. Il s’agit donc d’un algorithme itératif.
À chaque étape, les prédictions sont effectuées en utilisant des échantillons spécifiques en utilisant l’ensemble de paramètres internes. Les prédictions sont ensuite comparées avec les résultats attendus, pour calculer le taux d’erreur. Les paramètres internes sont ensuite mis à jour.
Les différents algorithmes utilisent différentes procédures de mise à jour. Dans le cas des réseaux de neurones artificiels, l’algorithme utilise la méthode de rétro-propagation.
Taille de batch vs epoch : quelle différence ?
La taille de batch est le nombre d’échantillons traités avant que le modèle change. Le nombre d’epochs est la quantité d’itérations complètes du jeu de données d’entraînement.
Un batch doit avoir une taille minimale de un, et une taille maximale inférieure ou égale au nombre d’échantillons du dataset d’entraînement.
Pour le nombre d’époques, il est possible de choisir une valeur entière entre un et l’infini. Le traitement peut être exécuté indéfiniment et même être arrêté par des critères autres qu’un nombre prédéterminé d’époques. Par exemple, le critère peut être le taux d’erreurs du modèle.
La taille du batch et le nombre d’époques sont des hyperparamètres de l’algorithme d’apprentissage, et doivent être indiqués à l’algorithme. Ces paramètres doivent être configurés en testant de nombreuses valeurs pour déterminer laquelle est optimale.
Comment choisir le nombre d'epochs ?
Après chaque itération du réseau de neurones, les poids sont modifiés. La courbe évolue de l’underfitting à l’overfitting, en passant par l’ajustement idéal. Le nombre d’époques est un hyperparamètre devant être décidé avant le début de l’entraînement.
Un nombre d’époques plus important ne permet pas forcément de meilleurs résultats. De manière générale, le nombre de 11 époques est idéal pour l’entraînement sur la plupart des datasets.
L’optimisation de l’apprentissage est basée sur le processus itératif de descente graduelle. C’est la raison pour laquelle une seule époque ne suffit pas pour modifier les poids de façon optimale. Au contraire, une époque de trop peut causer l’overfitting du modèle…
Pourquoi est-ce essentiel en Machine Learning ?
L’epoch est l’une des notions cruciales du Machine Learning. Elle aide à identifier le modèle représentant les données de la manière la plus fidèle possible.
Le réseau de neurones doit être entraîné en se basant sur le nombre d’époques et la taille du batch indiqués à l’algorithme. Cet hyperparamètre détermine donc tout le déroulement du processus.
Quoi qu’il en soit, il n’existe pas de recette secrète ou de formule magique pour définir la valeur idéale de chaque paramètre. Les Data Analysts n’ont d’autre choix que de tester une large variété de valeurs avant de choisir la plus adaptée à la résolution du problème spécifique.
L’une des méthodes permettant de déterminer le nombre d’époques approprié consiste à surveiller les performances d’apprentissage en comparant ce nombre avec le taux d’erreurs du modèle. La courbe d’apprentissage est très utile pour vérifier si un modèle est overfitting, underfitting, ou entraîné adéquatement.


Comment suivre une formation Machine Learning ?
En résumé, l’epoch est un terme utilisé pour décrire la fréquence à laquelle les données d’entraînements passent par l’algorithme. C’est l’un des concepts essentiels du Machine Learning.
Afin d’acquérir une expertise dans ce domaine, vous pouvez choisir DataScientest. Nos formations Data Scientist, Data Analyst et Machine Learning Engineer comportent toutes un module dédié au Machine Learning.
Vous découvrirez l’apprentissage supervisé et non-supervisé, les techniques de classification, régression, clustering avec scikit-learn, ou encore le Text Mining, les séries temporelles et la réduction de dimension.
À travers les autres modules de ces cursus, vous pouvez obtenir toutes les compétences requises pour devenir professionnel en Data Science. Vous pourrez exercer les métiers de Data Analyst, Data Scientist ou Machine Learning Engineer selon le parcours choisi.
Toutes nos formations s’effectuent intégralement à distance via internet, et peuvent être complétées en Formation Continue ou en BootCamp. Notre approche innovante de Blended Learning combine apprentissage à distance sur une plateforme coachée et Masterclass.
À la fin du parcours, les apprenants reçoivent un certificat des Mines ParisTech PSL Executive Education et valident le bloc 3 de la certification RNCP 36129 « Chef de projet en intelligence artificielle » reconnu par l’Etat. Vous pourrez aussi passer les examens pour obtenir les certifications Microsoft Certified Power Platform Fundamentals ou AWS Cloud Practitioner.
Enfin, pour le financement, notre organisme reconnu par l’Etat est éligible au Compte Personnel de Formation. N’attendez plus et découvrez DataScientest !
Vous savez tout sur l’epoch dans le domaine du Machine Learning. Pour plus d’informations sur le même sujet, découvrez notre dossier complet sur le Machine Learning et notre dossier sur les réseaux de neurones.






