
I - Introduction
Si vous vous êtes tenu informé des innovations dans le domaine du Deep Learning en 2019, vous avez sans doute entendu parler de StyleGAN le réseau antagoniste génératif développé par des chercheurs de chez Nvidia en fin 2018. Cet algorithme s’est fait connaître du grand public en février 2019, alors qu’il venait de passer en open source, lorsque l’ingénieur Phil Wang l’a utilisé pour créer le site internet. Ce site internet génère un visage humain aléatoire à chaque nouvelle connexion (l’actualisation du site suffit pour générer de nouveaux visages) qui, évidemment, n’existe pas et résulte du générateur StyleGAN :

Comme vous pouvez le constater, StyleGAN produit des images de haute qualité rendant les visages générés quasi indiscernables de véritables visages. C’est d’autant plus impressionnant lorsque l’on sait que l’invention des GAN est très récente (2014) démontrant que l’évolution des architectures de génération est très rapide. On peut alors se demander comment fonctionnent ces modèles de Deep Learning pour produire des résultats aussi convaincants ?
II - Architecture d’un GAN
Et bien comme son nom l’indique, StyleGAN est avant tout un GAN (Generative Adversiarial Network) et un GAN est un modèle se décomposant en deux gros sous-modèles : un générateur et un discriminateur :
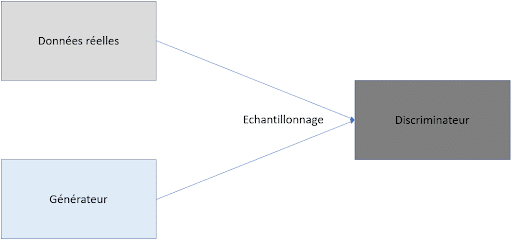
Le générateur est le modèle qui permet de générer des images à partir généralement d’un bruit aléatoire, le discriminateur quant à lui sert à classer une image donnée afin de savoir si elle est générée ou non.
Ainsi, lors de l’entraînement, on entraîne à la fois le générateur et le discriminateur afin que le discriminateur soit de plus en plus fort pour différencier image réelle et image générée et pour que le générateur, soit de plus en plus fort pour tromper le discriminateur. Les données réelles ne sont vues pendant l’entraînement que par le discriminateur pour qui autant d’exemples réels et générés lui seront fournis. La fonction de perte pour le discriminateur sera les erreurs qu’il commet en classant les données et celle du générateur sera la réussite du discriminateur à le différencier des vraies images. Certains modèles utilisent la même fonction de perte qui est minimisée par le discriminateur et maximisée par le générateur.
III - Architecture StyleGAN
StyleGAN reprend exactement la même architecture précédente et va même jusqu’à utiliser des fonctions de perte classiques des GAN ainsi qu’un modèle de discriminateur tout à fait classique. Là d’où provient son originalité se situe entièrement dans l’architecture du générateur :
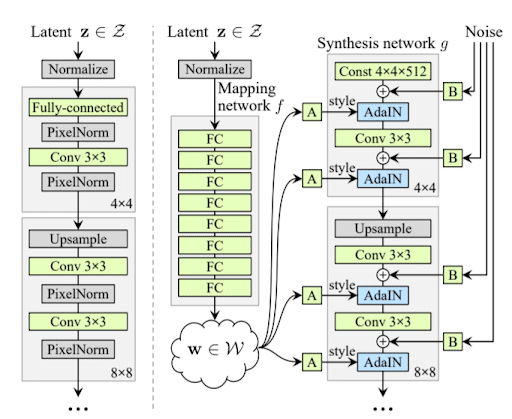
Comme on peut le constater, StyleGAN n’utilise pas l’architecture traditionnelle d’un générateur basé sur une succession de couches de convolutions et de couches de normalisation. À la place, StyleGAN utilise un générateur « basé sur le style » (d’où le nom style GAN), c’est-à-dire que l’architecture de son générateur est empruntée de la littérature en Deep Learning portant sur les problèmes de transfert de style. Le transfert de style fait référence à la tâche consistant à transférer le style d’une image (ou d’un artiste) comme Picasso à d’autres images/tableaux.
La première partie du générateur consiste alors à mapper le bruit aléatoire en entrée dans un espace latent W(c’est le mapping network). Une fois cette première étape effectuée, on passe le vecteur latent résultant W dans le réseau de synthèse (à plusieurs endroits d’où les multiples flèches) constitué de couches de convolutions et de couches spéciales AdaIN (adaptative instance) souvent utilisées en transfert de style. Enfin, la dernière particularité de cette architecture par rapport à celle traditionnelle est l’addition de bruit gaussien à chaque étape.
Convolution : La convolution est ici classique et s’effectue avec un noyau 3×3. Découvrez notre article complet sur le sujet pour plus de détail sur le fonctionnement des Convolutional Neural Network
AdaIN : Cette couche est beaucoup plus particulière et correspond à l’opération suivante :

On normalise d’abord l’entrée xi avant de lui transférer les vecteurs de styles (moyenne et variance) ys et yb. Les styles sont calculés à partir de transformations affines de W apprises et ils sont appliqués au bruit gaussien ajouté lui aussi réduit selon des facteurs appris. Ainsi, à la différence d’un GAN classique ou le bruit donné en entrée du générateur sert de source à la création d’une image, ici dans le StyleGAN ce bruit sert à donner le style à d’autres bruits gaussiens que l’on ajoute au fur et à mesure.
Le reste du réseau suit l’architecture des Progressive Growing GAN qui permet de travailler avec des résolutions d’images de plus en plus grandes.
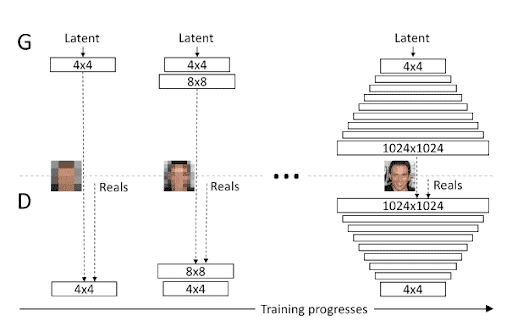
Différentes bases de données ont été utilisées pour entraîner ce modèle, mais la principale base de données utilisée est CelebA-HQ qui est une base de données de visages en haute définition (1024×1024).
IV - Version ultérieures de StyleGAN
Nous avons vu comment fonctionnait le StyleGAN de base, mais entre fin 2018 et maintenant, les chercheurs de Nvidia n’ont pas arrêté d’améliorer leur logiciel ! En effet, le 3 décembre 2019 ils ont publié leur second article présentant StyleGAN2 qui est une version améliorée de StyleGAN dans laquelle ils ont changé quelques couches du générateur et ont régularisé celui-ci (améliorant ainsi les performances). Enfin, en juin 2021, l’équipe de Nvidia a publié à ce jour son dernier papier sur StyleGAN introduisant StyleGAN3, fonctionnant tout aussi bien que StyleGAN2 mais dont toute la différence fondamentale réside dans la représentation interne des images des réseaux donnant la possibilité de translater et pivoter les images efficacement. Ci-dessous en vidéo un exemple d’application de ces transformations à des images de plages :
V - Conclusion
Nous avons vu dans cet article ce qu’était un GAN et plus particulièrement quel était l’architecture du StyleGAN et d’où venait sa spécificité vis-à-vis des autres GAN. StyleGAN, en s’inspirant du domaine du transfert de style, représente l’état de l’art pour générer des images de visages réalistes et est disponible pour tous dans Tensorflow sous la licence Creative Commons. Enfin, grâce à ses améliorations StyleGAN2 et StyleGAN3, le modèle est d’autant plus performant pour gérer des rotations et des translations lui permettant de mieux se généraliser et de posséder des images latentes (entre le bruit et l’image finale) plus explicables. En rejoignant le cursus expert de Deep Learning, vous serez capable d’utiliser ce modèle avec Tensorflow afin de l’adapter à différentes tâches de génération.








