
Le transfert de style ou Neural Style Transfer (NST) représente un ensemble de modèles et de méthodes permettant, avec des images ou des vidéos, de transférer le style visuel d’une image vers une autre. Nous allons dans cet article nous intéresser plus particulièrement à un modèle précis qui s’appelle CycleGAN.
De nos jours, les algorithmes les plus performants dans le domaine du NST sont les algorithmes de Deep Learning adaptés utilisant des couches de convolutions. Artistiquement, le NST sert le plus souvent à créer des œuvres artificielles à partir d’une photographie et du style d’un peintre. Il existe actuellement plusieurs applications (mobiles et web) permettant d’effectuer du transfert de style, par exemple DeepArt et le blog de Reiinakano. On peut ainsi transformer un personnage de Star Wars (Dark Revan) en un tableau inspiré de l’œuvre Clouds over Bor de Paul Klee :

Le modèle CycleGAN, qu’est-ce que c’est ?
Comme son nom l’indique, CycleGAN est un type de modèle génératif (crée par Jun-Yan Zhu et al. pour le laboratoire de recherche BAIR de l’UC Berkeley), un GAN (Generative Adversarial Network) servant à effectuer du transfert de style sur une image. En pratique, la grande majorité des GAN que l’on utilise pour transformer une image du style d’un domaine X en image du style d’un domaine cible Y est entraînée en utilisant un jeu de données jumelées dont chaque exemple d’image de X possède un exemple directement associé dans un autre style Y. Là où CycleGAN se démarque est justement dans son non-besoin d’avoir des pairs d’images lors de l’entraînement. En effet, lorsque l’on entraîne un tel modèle, on obtient de très bonne performance sans jamais utiliser des images jumelées, ce qui facilite grandement l’entraînement pour des jeux de données particuliers où aucune correspondance n’a été faite. On peut alors imiter le style d’un peintre pour différentes images en utilisant une base de donnée de ses tableaux par exemple ! Tout d’abord, présentons l’architecture d’un GAN. Si vous avez déjà lu l’un de nos articles traitant sur des GAN, vous savez qu’un GAN est un modèle se décomposant en deux gros sous-modèles, un générateur et un discriminateur :
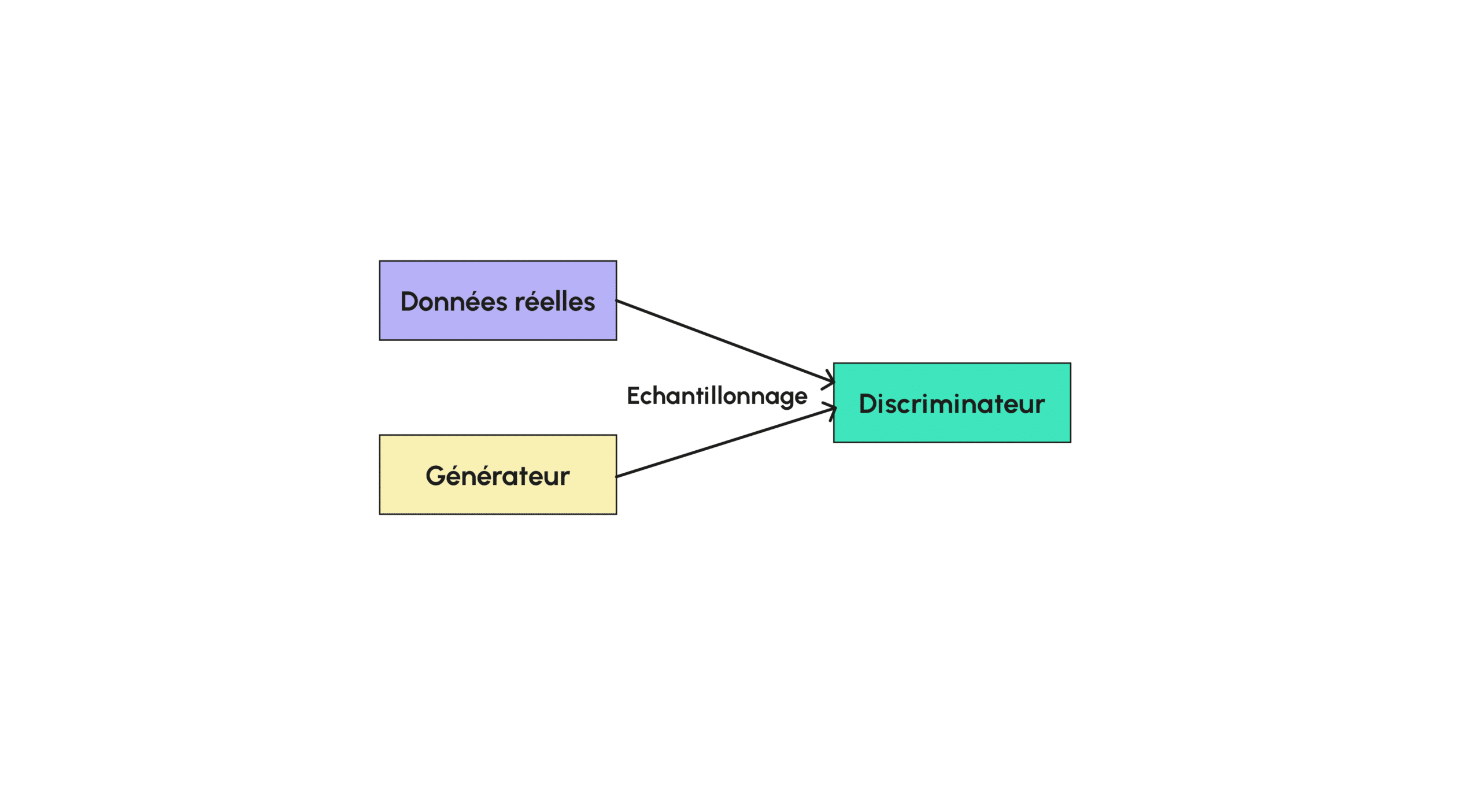
Le générateur est le modèle qui permet de générer des images à partir généralement d’un bruit aléatoire, le discriminateur (qui prend une valeur entre 0 et 1) quant à lui sert à classer une image donnée afin de savoir si elle est artificielle ou non. Ainsi, lors de l’entraînement, on entraîne à la fois le générateur et le discriminateur afin que le discriminateur soit de plus en plus fort pour différencier une image réelle d’une image générée et pour que le générateur, soit de plus en plus fort pour tromper le discriminateur. Pendant l’entraînement, le générateur n’a pas accès aux données réelles directement, seul le générateur les utilise afin de les comparer à des données simulées. La fonction de perte pour le discriminateur sera les erreurs qu’il commet en classant les données et celle du générateur sera la réussite du discriminateur à le différencier des vraies images. Certains modèles utilise la même fonction de perte qui est minimisée par le discriminateur et maximisée par le générateur.
La structure du CycleGAN est pensée pour que le générateur G translate la distribution d’un style X vers un autre style Y afin que le discriminateur ne puisse pas distinguer le style transformé Y=G(X) du style original Y. Il existe un problème qui arrive assez souvent en appliquant cette stratégie telle qu’elle : le générateur va translater toutes les images de la même façon ne pouvant générer alors qu’un seul exemple b ce qui n’est pas la tâche recherchée.
Ainsi pour pallier ce problème, la structure du CycleGAN va rajouter une contrainte en définissant un autre générateur F dont le rôle sera d’être la transformée inverse de G dans le sens où FGX≈X. On aura ainsi une garantie que la transformation de X ne sera pas réduite à un seul exemple. On ajoute donc lors de l’entraînement une nouvelle fonction de perte caractérisant la perte cyclique consistante (cycle consistency loss) encourageant les transformations à vérifier les propriétés FGX≈X et que G(FY)≈Y. On ajoute en plus du discriminateur pour G (que l’on appelle DY car on veut discriminer Y de Y) un discriminateur pour F (que l’on appelle DX). On retrouve dans ce papier un schéma résumant les différentes relations décrites précédemment.
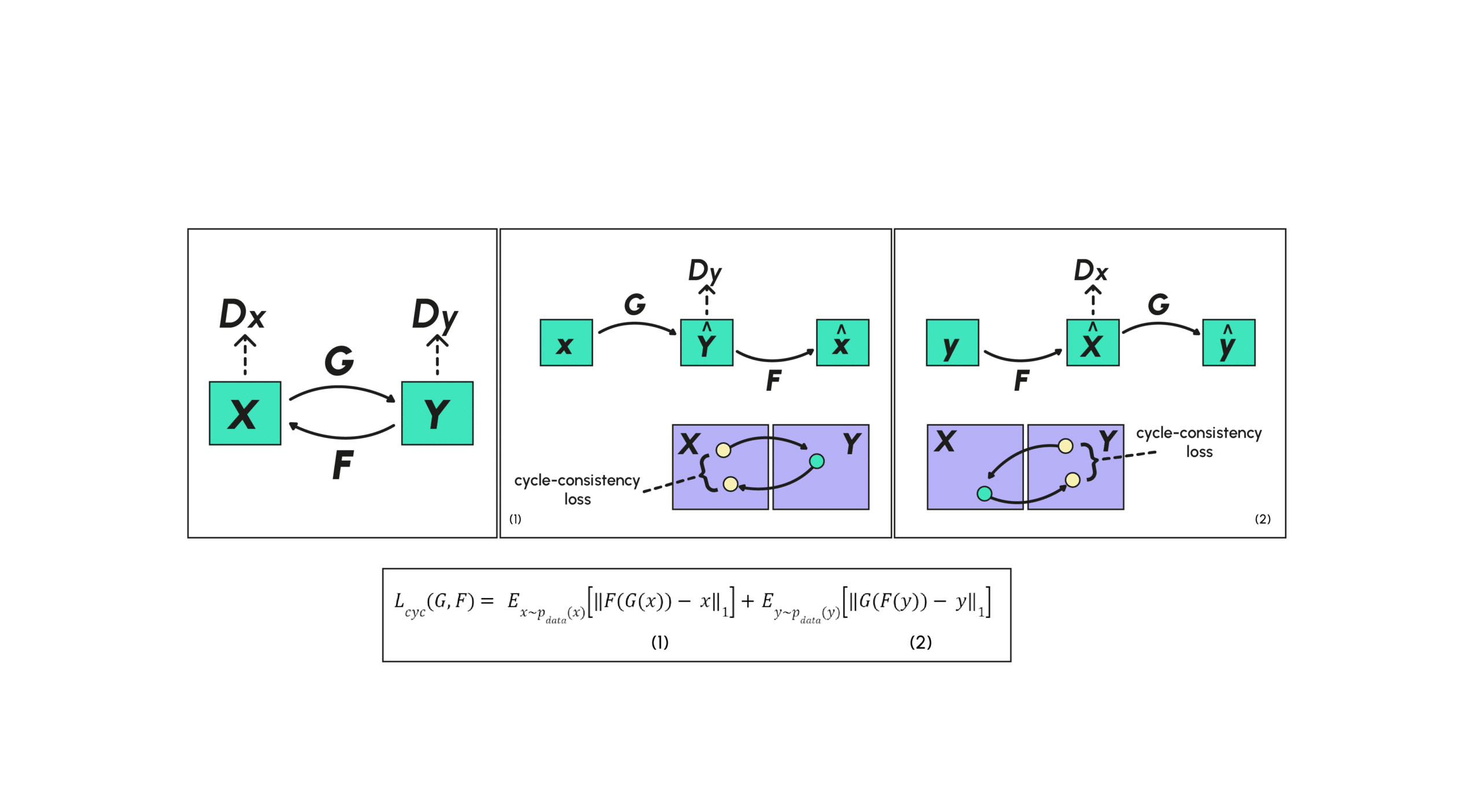
La cycle-consistency loss est alors séparée en deux morceaux distincts, le premier (1) correspondant à la perte entre les éléments de X et leurs reconstructions et le deuxième (2) correspondant à la perte entre les éléments de Y et leurs reconstructions.
Ici dans ce modèle les générateurs et discriminateurs vont optimiser la même fonction de perte générale, celle-ci est constituée de deux sous-fonctions de perte associées aux générateurs (adversial loss) :


et de la fonction de perte de consistance cyclique :

donnant la fonction de perte globale :

qui sera maximisée par les discriminateurs (pour que ceux-ci distinguent bien génération de réel) et minimisée par les générateurs afin que ceux-ci créent des exemples de plus en plus indiscernables des données réelles.
L’architecture de CycleGAN dans le détail
Les deux générateurs et les deux discriminateurs sont parfaitement identiques dans l’architecture, c’est-à-dire qu’ils sont constitués des mêmes couches et sont de mêmes dimensions. Les générateurs utilisent principalement des couches de convolution et des blocks résiduels (residual blocks).
En ce qui concerne les couches de convolutions, elles ont déjà été abordées et expliquées en détail dans un autre article de notre blog que vous pourrez retrouver ici. Les blocks résiduels sont quant à eux des couches très simples en Deep Learning, souvent utilisées en transfert de style, elles permettent à l’image de ne pas trop s’éloigner de celle d’origine en la rappelant au réseau au fur et à mesure. Plus formellement, une telle couche est de la forme :
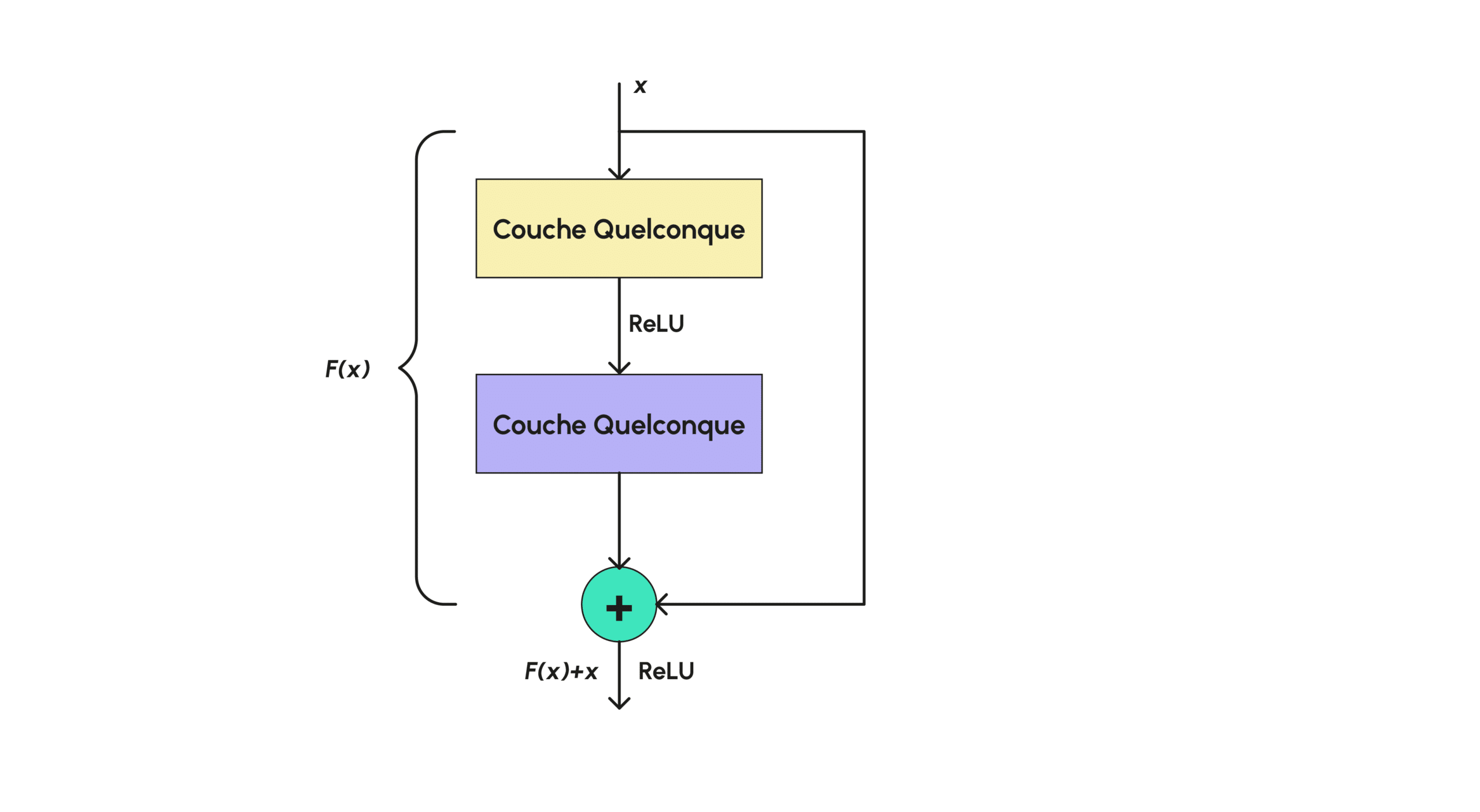
Ainsi comme le montre le graphique (d), le block résiduel consiste juste en une couche normale dont on ajoute à la fin la valeur initiale en entrée, cela permet donc littéralement de ne pas trop modifier l’image de départ.
On applique aussi un ReLU dans certains cas permettant d’annuler la sortie de la couche si jamais F(x) s’avère être trop élevée négativement (là où une image en couleur aura des valeurs positives). Pour les discriminateurs le modèle utilise des 70 x 70 PatchGANs c’est-à-dire que le discriminateur va être constitué de plusieurs petits GANs, des PatchGANs de taille initiale 70 x 70 qui vont s’appliquer un peu partout à l’image et peuvent se chevaucher dans la partie de l’image considérée, déterminant si telle partie de l’image est réelle ou non. La réponse finale est alors calculée comme la moyenne des réponses renvoyées pour chaque patch. Chaque PatchGAN va avoir une architecture similaire constituée uniquement de couches de convolutions classiques. Enfin l’entraînement est fait avec un batch size de 1 et un optimisateur classique : Adam.

On présente ici quelques résultats obtenus avec des images de test à travers le modèle défini précédemment, à gauche on a les images originales fournies en entrée et à droite les images transfigurées. On voit par exemple que le modèle entraîné avec des images de chevaux et de zèbres peut passer librement d’un style d’animal à l’autre.
De la même façon, lorsqu’il est entraîné avec des tableaux d’artistes, il peut passer d’une photographie à un tableau au style de Van Gogh. On obtient aussi de très bons résultats pour la reconstruction d’images. En effet, en plus de la reconstruction quasi-identique de celle-ci, on peut aussi remarquer que la qualité de l’image reconstruite est améliorée (avec une meilleure profondeur de champ) par rapport à celle de base :

Nous avons vu dans cet article ce qu’était le transfert de style et plus particulièrement l’architecture du modèle CycleGAN, inspiré des GANs, permettant de transférer des styles de façon efficace. CycleGAN est l’un des meilleurs algorithmes permettant de faire du transfert de style. Nous avons de plus vu que cet algorithme, à l’opposé de la quasi-totalité des algorithmes permettant de faire du transfert de style, n’a pas besoin de données appariées qui sont compliquées à obtenir en pratique et permet donc d’entraîner différentes bases de données jusqu’alors inutilisable tel que celles des tableaux de peintres célèbres comme Van Gogh. Enfin nous avons vu qu’en plus d’avoir un transfert de style efficace, ce modèle disposait aussi d’une reconstruction d’image fidèle donnant en sortie une image avec une profondeur de champ mieux réalisée démontrant la stabilité de l’algorithme. Cet algorithme n’est toutefois pas tout-puissant car il a des lacunes lorsqu’il faut modifier les propriétés géométriques des images comme lorsque l’on souhaite transformer un chat en chien, il est donc adapté uniquement au changement des textures.
Si vous voulez en apprendre plus sur la transfiguration d’objets, le Deep Learning et l’intelligence artificielle appliquée aux images : découvrez notre formation de Data Scientist.









