Hoy echamos un vistazo a Isolation Forest, un algoritmo de Machine Learning diseñado para resolver problemas de clasificación binarios como la detección de fraudes o el diagnóstico de enfermedades. Esta técnica, presentada en la 8.ª Conferencia Internacional del IEEE en 2008, es la primera técnica de clasificación dedicada a la detección de anomalías basada en el aislamiento.
El problema de la paradoja de la precisión
Cuando nos enfrentamos a un problema de clasificación de clases en Machine Learning, a veces ocurre que el conjunto de datos está desequilibrado. Más concretamente, existe una proporción mucho mayor de una clase que de otra dentro de la muestra de entrenamiento. Este problema es una característica frecuente de los problemas de clasificación binarios. A primera vista, se podría pensar en aplicar un algoritmo de clasificación clásico, como los árboles de decisión, los K-NN o SVM presentados en nuestro blog. Sin embargo, en realidad, estos algoritmos son incapaces de manejar estos conjuntos de datos atípicos en los que hay un gran número de disparidades entre clases. Tienden a maximizar por medio de su función de pérdida de cantidades como accuracy, pero sin tener en cuenta la distribución de los datos.
En la práctica, esto puede verse en modelos que, cuando se entrenan en un conjunto de datos dominado por una clase, reportarán durante la fase de evaluación un alto índice de predicciones correctas, conocido como “accuracy”, pero no serán relevantes en la práctica.
Veamos un ejemplo para ilustrar esta paradoja. En el caso de un problema de detección de fraudes bancarios: un banco intenta determinar entre un gran número de transacciones cuáles son fraudulentas, basándose en una serie de variables explicativas. Estas transacciones fraudulentas representan alrededor del 11 % de las transacciones de nuestro conjunto de datos. La clasificación mediante un modelo sencillo como SVM utilizando Scikit-Learn da, por ejemplo, la siguiente puntuación:
Puntuación sobre el conjunto de prueba 0,8985
Sin embargo, si echamos un vistazo a la matriz de confusión, rápidamente nos damos cuenta de que el comportamiento del algoritmo es bastante ingenuo:
| Clase prevista | 0 | 1 |
|---|---|---|
| Clase real | ||
| 0 | 1772 | 9 |
| 1 | 194 | 25 |
De 219 transacciones fraudulentas, solo 25 fueron identificadas como fraudulentas por nuestro modelo. Esto demuestra que el poder predictivo del modelo no es tan potente como podría sugerir la precisión. Se trata de una métrica demasiado sesgada por un desequilibrio de clases, un fenómeno conocido como la paradoja de la precisión.
Un modelo con una puntuación de precisión más alta puede tener un poder de predicción menor que un modelo con una precisión más baja.
¿Qué es el Isolation Forest?
¿Cómo afrontar este problema que arruina los esfuerzos de varios algoritmos clásicos bien entrenados? Existen varias soluciones, como por ejemplo los métodos de remuestreo, como el submuestreo o el sobremuestreo, que seleccionan aleatoriamente datos para equilibrar la proporción de clases. Sin embargo, cuando estos métodos no son suficientemente eficaces, es habitual replantearse el problema y considerar la detección de anomalías como un problema de clasificación no supervisada. Aquí es donde entra en juego el tan esperado Bosque de Aislamiento.
En Isolation Forest, encontramos Isolation porque es una técnica de detección de anomalías que identifica directamente las anomalías (comúnmente conocidas como «outliers«), a diferencia de las técnicas habituales que discriminan los puntos con respecto a un perfil general “normalizado”.
El principio de este algoritmo es muy sencillo:
- Se selecciona una variable (feature) de forma aleatoria.
- A continuación, el conjunto de datos se divide aleatoriamente en función de esta variable para obtener dos subconjuntos de datos.
- Las dos etapas anteriores se repiten hasta aislar un dato.
- Los pasos anteriores se repiten recursivamente.
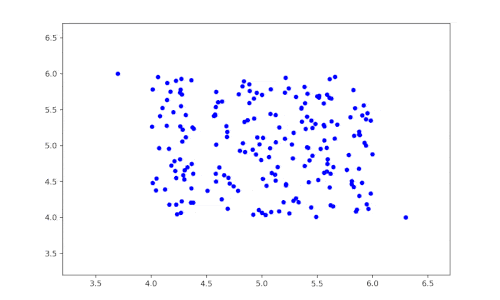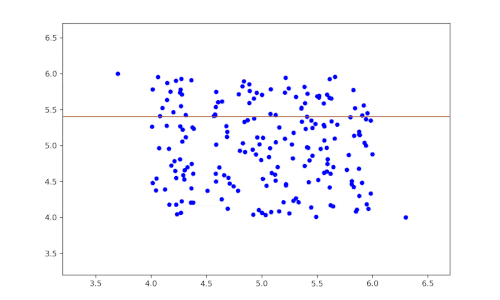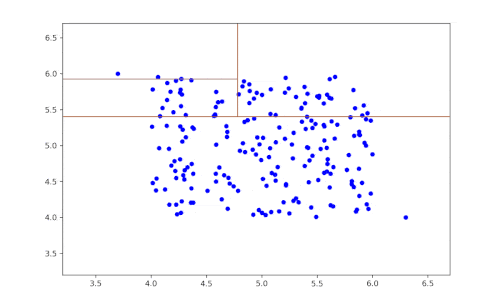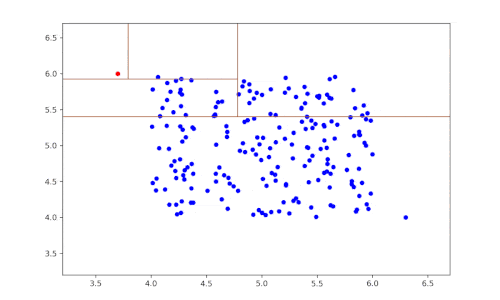
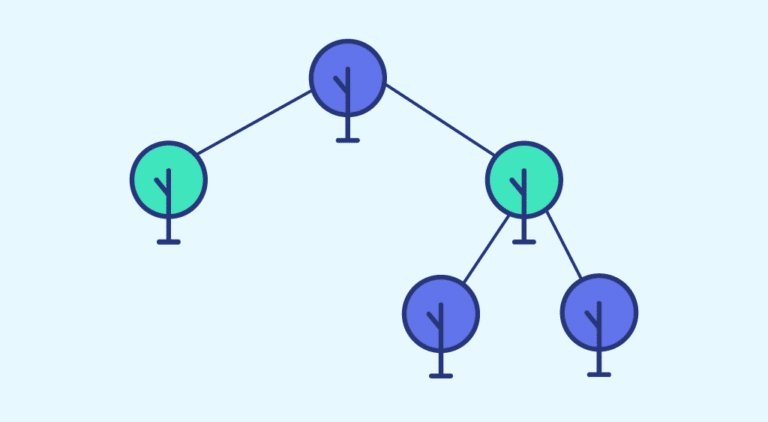
Al igual que los algoritmos de ensamblado como Random Forest, creamos un bosque (de ahí el nombre de Isolation Forest) formado por decenas o cientos de árboles cuyos resultados combinamos para obtener un resultado mejor.
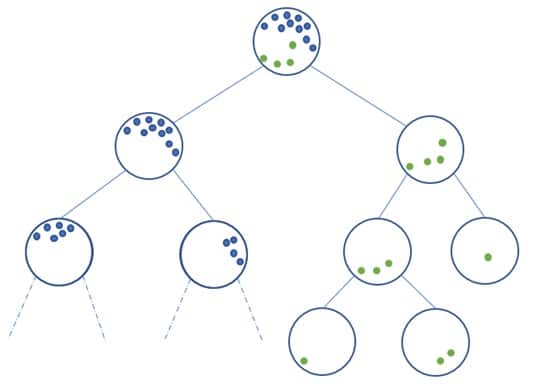
Entonces, ¿cómo se obtiene el resultado en un árbol? En otras palabras, ¿cómo se define si un punto es una anomalía o no? La construcción del algoritmo da lugar a una estructura de árbol, cuyos nudos son los conjuntos particionados durante las etapas del algoritmo y cuyas hojas son los puntos aislados. Intuitivamente, las anomalías tenderán a ser las hojas más cercanas a la raíz del árbol.
En función de la distancia a la raíz, se asigna una puntuación de anomalía a cada hoja de un árbol, y esta puntuación de anomalía se promedia sobre todos los árboles que se han construido de forma recursiva, para obtener un resultado final. En función de la situación, pueden ajustarse parámetros como el número de árboles o la proporción de anomalías que hay que considerar para obtener un resultado más sólido.
El Isolation Forest es muy apreciado por su capacidad para detectar anomalías de forma no supervisada, y a la vez obtener resultados satisfactorios en numerosos ámbitos. Entre sus aplicaciones figuran el fraude bancario, el diagnóstico médico y el análisis de fallos estructurales.
Si quieres saber más, echa un vistazo a nuestros cursos de Data Scientist, Data Analyst y Data Engineer.
