
Statistical bias can be defined as anything that leads to a systematic difference between the true parameters of a population and the statistics used to estimate these parameters. There is a long list of types of statistical bias.
We’ve decided to present these four types to you, because they’re the ones we see most affecting the daily lives of data scientists and analysts.
We’ll describe them and give you a concrete example.
1) Selection bias
Selection bias occurs when, as the name suggests, the data selection is skewed. This generally means that you are working with a specific subset of your group, rather than a random subset.
For example, if you want to launch a new product, before spending time and money, you need to know if your audience is interested in it.
So, you conduct a survey that you send to your existing customers. While this is certainly an important part of your audience, it does not represent the entirety of your audience. You have just introduced a selection bias that can cost you dearly!
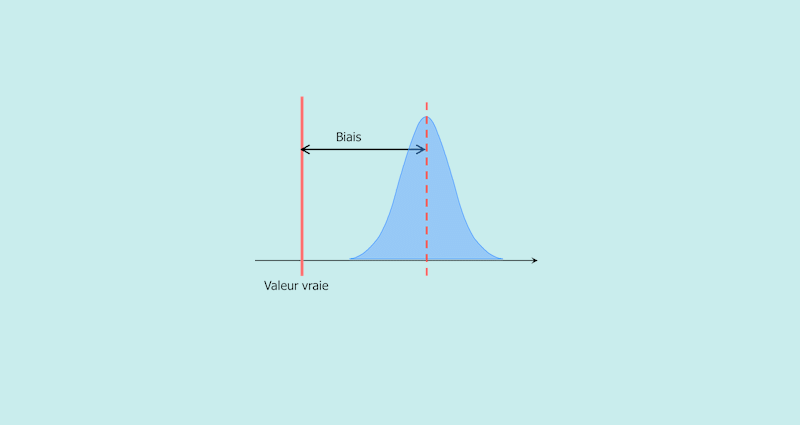
2) Recall bias
Recall bias is another common error in survey situations, especially in feedback scenarios. It occurs when participants cannot remember past events, memories, or details accurately.
Human memory is inherently selective, which is a normal phenomenon but can make research more challenging.
The human brain tends to recall good memories more readily than bad ones. For instance, if you conduct a survey after a conference, it’s preferable to send the questionnaire promptly if you want it to be more accurate.
This is because memories can fade or become distorted over time, and people are more likely to remember the positive aspects of an event while forgetting or downplaying the negative ones.
Therefore, collecting feedback as soon as possible after an event can help reduce recall bias and provide more accurate responses.
3)Recall bias
Recall bias is another common error in survey situations, especially in feedback scenarios. It occurs when participants cannot remember past events, memories, or details accurately.
Human memory is inherently selective, which is a normal phenomenon but can make research more challenging.
The human brain tends to recall good memories more readily than bad ones. For instance, if you conduct a survey after a conference, it’s preferable to send the questionnaire promptly if you want it to be more accurate.
This is because memories can fade or become distorted over time, and people are more likely to remember the positive aspects of an event while forgetting or downplaying the negative ones.
Therefore, collecting feedback as soon as possible after an event can help reduce recall bias and provide more accurate responses.

4) Omitted variable bias
Indeed, this is a bias known as “omission bias” in statistics and modeling. This bias occurs when relevant variables are not included in a model, which can lead to incorrect predictions or conclusions. In the context of Machine Learning, it means that if you do not consider important features for a model, it can become ineffective or provide inaccurate results.
Your concrete example illustrates this concept well. When buying a car, if you only consider the price without taking into account other factors such as mileage, year of manufacture, overall condition, etc., you could make a choice based on an omission bias.
In this example, omitting the high mileage has a significant impact on the actual value of the car.
It is essential to carefully choose the variables to include in a Machine Learning model to ensure that it adequately captures relevant information and produces reliable results.
We have provided you with a non-exhaustive list of the main statistical biases that are commonly encountered in Data Science and in our daily lives.
It is important to emphasize that biased statistics are bad statistics. It is always essential to strive to minimize biases as much as possible. One very effective technique to avoid biases is randomization, for instance. Ensuring that the study sample is drawn randomly can help mitigate biases.








