
The proliferation of data acquisition and systematic processing has facilitated the rise of machine learning methods that require ample data for training and operation. While one might naively assume that having a large amount of data is sufficient for a high-performing algorithm, the data we have is often not well-suited, and preprocessing is typically necessary before using them: this is the preprocessing step.
Indeed, acquisition errors due to human or technical mistakes can corrupt our dataset and introduce bias during training. Among these errors, we can mention incomplete information, missing or incorrect values, or even noisy artifacts related to data acquisition.
Therefore, it is often essential to establish a data preprocessing strategy – also known as Data Preprocessing – starting from our raw data to obtain usable data that will lead to a more efficient model. We will explore the most important steps of this preprocessing, their significance, and their implementation in Python for some of them.
Data Cleaning: The different stages
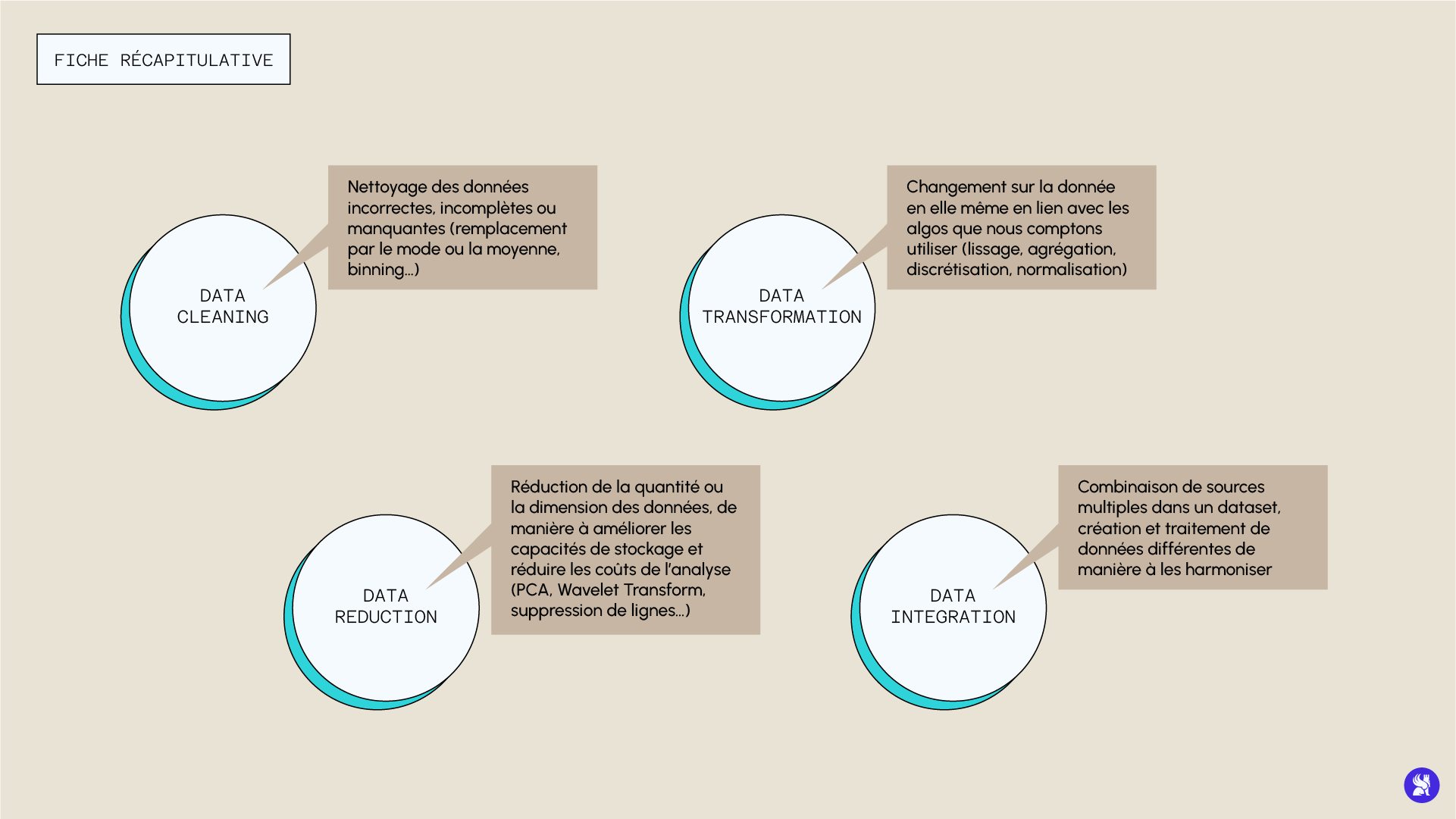
The first step involves cleaning incorrect, incomplete, or missing data. There are several ways to address these issues, which we will review.
If there is missing data in the dataset, you can choose to ignore it if the database is sufficiently large and if many data points are missing in the same row.
Alternatively, you can decide to fill in these missing data in different ways: you can replace them with the mean, median, or, for categorical variables, with the most frequent mode.
Pandas provides us with methods that allow us to perform these treatments as follows:
Data can sometimes suffer from acquisition noise, in which case they may not be correctly processed by a computer. One way to address this issue is to perform data binning (after sorting the data). The data is divided into groups of the same size, and each group is treated independently.
Within the same group, all data points can be replaced by their mean, median, or extreme values.
Another way to handle noisy data is to use regression or clustering, which automatically creates data groups that can help us detect outliers and remove them from the database.
Data Transformation: What for?
This preprocessing step involves changes made to the data structure itself. These transformations are related to the mathematical definitions of algorithms and how they process data in order to optimize performance. Among these techniques, we can mention:
– Data smoothing if the data is noisy.
– Data aggregation from various different sources.
– Discretization of continuous variables (using interval splitting) to reduce the number of categories for a descriptor.
– Normalization and standardization of data, which scale numerical data to a smaller range (e.g., between -1 and 1) and can also center the mean and reduce variance.
Here’s an example of how to perform normalization, which is often necessary in this data transformation part:
Data Reduction: Was ist das?
While it may seem intuitive that a large amount of data improves the performance of a model, having an excessively large dataset can sometimes make the analysis more complex.
Therefore, it can be interesting to reduce the quantity or dimension of the data to improve storage capabilities and reduce analysis costs without sacrificing performance (and sometimes even gaining performance in certain cases). There are several data reduction techniques.
For example, we can choose to keep a certain number of variables we prefer and drop others. The selection of relevant variables can be done through analysis of the variable’s p-value or through decision tree techniques that provide an estimation of the importance of different descriptors.
Another widely used technique for data reduction is dimensionality reduction. This method reduces the dimension of the data through well-defined encoding mechanisms.
There are two types of dimensionality reduction: with or without loss. If you can reconstruct the exact data from the reduced data, it’s called lossless reduction. Otherwise, the reduction is lossy. Two preferred methods for this type of data reduction are wavelet transformation or Principal Component Analysis (PCA).
Data Integration: Ein wichtiger Schritt in der Vorverarbeitung
This step in the preprocessing strategy involves combining multiple sources into a single dataset. It is carried out in a data management framework for creating usable databases (such as creating image databases, cross-sectional abdominal scans, MRI or X-rays for diagnostic support).
However, some issues may arise, such as the incompatibility of certain formats or data redundancy.
The preliminary data processing step is one of the most crucial in data processing and analysis.
There is no perfect method to apply to every model creation, but we have discussed best practices to implement in a data preprocessing strategy.
The methods presented here are explored in more depth in our various training programs, where fundamental mathematical concepts and best practices for data preprocessing based on context and situation are explained.
To discover our curriculum in detail and learn all the best practices of data preprocessing, find out more by clicking below:








