
For humans, visual comprehension is often easier than textual comprehension, as our brains are able to process visual information faster and more efficiently. That's why we've seen the emergence of graphical databases using the Cypher language instead of traditional SQL.
Visual databases offer a much faster and more intuitive way of modeling and querying data. Invented largely by Andrés Taylor, an employee working on Neo4j, the language was designed with the power and capability of SQL in mind, while allowing users to see the results of their queries visually.
Cypher is a graphical language that’s very easy to learn, due to its similarity to other languages and its intuitiveness. For a company, it’s important to choose the right tool that’s both easy to use and powerful enough to meet the needs of evolving applications. That’s why Neo4j is used by major companies such as Michelin, NASA, Crédit Agricole and Volvo. Discover the power of this language in this article.
How does Cypher work?
Cypher has been designed specifically to work with graph databases. The vocabulary and syntax used are optimized to help users understand how their query works and how the results are generated.
Like SQL, entities and relationships are also present in Cypher, but in a different form: entities are represented by nodes, while relationships are in the form of edges. By displaying these elements in graphical form, users can visualize the relationships and connections between the elements of a complex system. This makes the language very intuitive for users to understand the structure of graph data and formulate Cypher queries more effectively.

What are the differences between Cypher and SQL?
SQL has been around for a long time, and it’s a powerful language, but there are some things that are better done with Cypher. Let’s take a look at the difference between SQL queries and Cypher. Cypher’s syntax resembles that of a classic SQL query language, but differs in a few respects. Let’s take the example of a query that will only return results for people born after 1998.
SQL query :
SELECT person.name
FROM person
WHERE person.birthdate > 1998;
Cypher request:
MATCH (person:Person)
WHERE person.birthdate > 1998
RETURN person.name;
As you can see, Cypher queries always start with the keyword “MATCH” instead of “SELECT” for SQL, followed by a “WHERE” clause to filter the results and finally “RETURN” to specify the data to be returned.
The difference between the two database languages can be seen in the relationships between entities.
In Cypher, a relationship is an edge connecting two nodes in a graph. Relationships are represented by dashes ( – ) between nodes. Each relationship can have a direction, represented by an arrow ( -> or <- ). This indicates the direction in which the relationship can be traversed. For example, the relationship “LOVES” can be represented by:
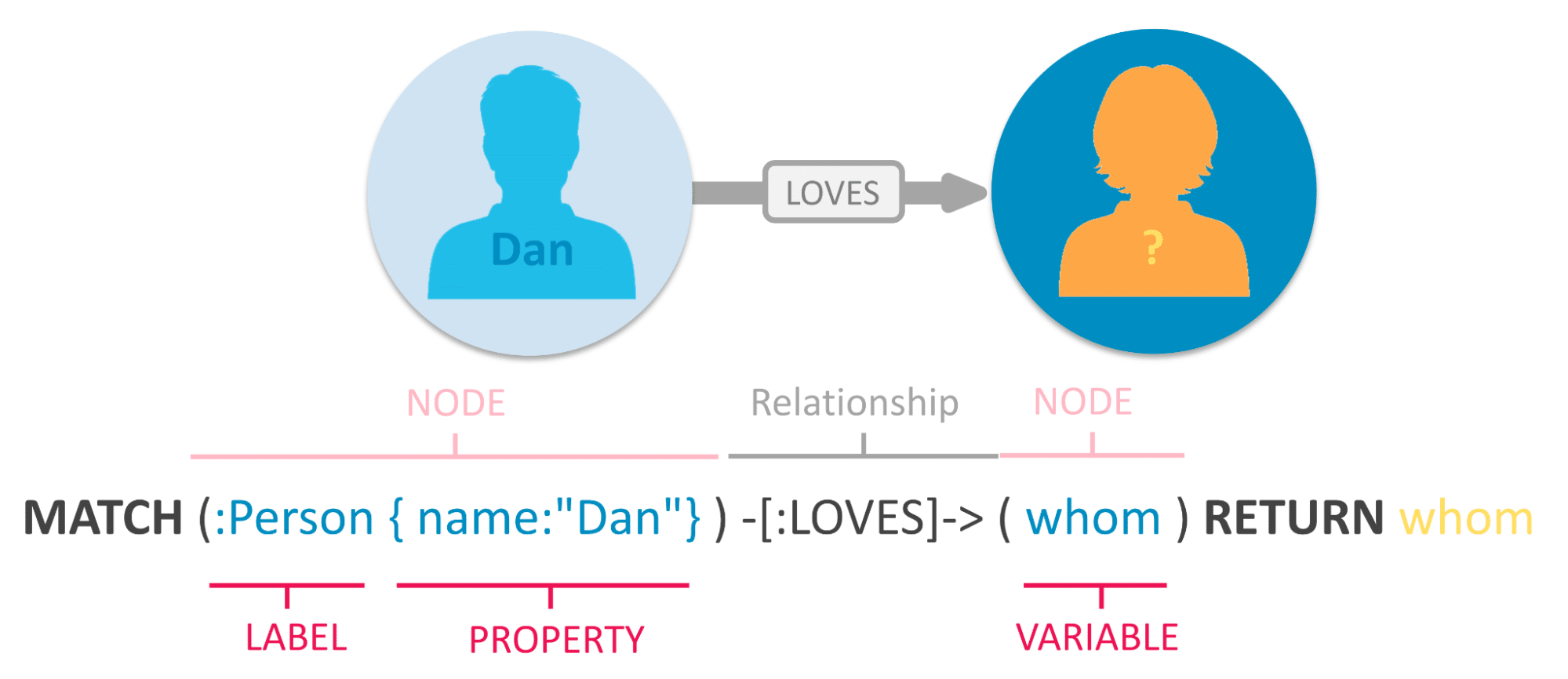
We can see that there is a “LOVES” relationship starting from node 1 and pointing to node 2. It is also possible to add properties to relationships or nodes to store additional information. Properties are represented by braces and can be added after the relationship. In this example, we’re looking for people who are liked by a person named “Dan”.
Cypher’s relations make it easy and intuitive to query the database. Let’s write a few queries to populate a database. Unlike SQL, we don’t need to define the schema beforehand. It’s our data insertion queries that will define the architecture of our database. First, let’s create a few nodes representing people in our database:
CREATE (:Person {name: 'Daniel', age: 40})
CREATE (:Person {name: 'Julia', age: 25})
CREATE (:Person {name: Bob'', age: 35})
Once we’ve added these nodes to our database representing a person with a name and age, we can create relationships between them. Unlike SQL, we can link our nodes very easily. For example, if we want Daniel to be in love with Julia and to be friends with Bob, we can do this with Cypher using the following queries:
MATCH (daniel:Person {name: 'Daniel'}), (julia:Person {name: 'Julia'})
CREATE (daniel)-[:LOVES]->(julia)
MATCH (daniel:Person {name: 'Daniel'}), (bob:Person {name: 'Bob'})
CREATE (daniel)-[:FRIEND]->(bob)
In contrast, with SQL, you’d first have to create three entities (Person, Friendship and Love) and then add the values to the tables to connect them.
Once the data has been added, we can see that it’s easier to make queries with Cypher than with SQL. If we want to see Daniel’s friends, we can do so with the following commands for both languages:
SQL query :
SELECT p.name
FROM Person p
JOIN Friendship f ON p.id = f.id
WHERE f.name = ‘Daniel’;
Cypher request:
MATCH (daniel:Person {name: 'Daniel'})-[:FRIEND]->(friend)
RETURN friend.name
We can see that Cypher queries are much shorter than SQL statements and much simpler to understand, which reduces the risk of errors.
In conclusion
Cypher is a powerful language that enables developers to make complex queries on graph-oriented databases. Its clear, concise syntax also makes it an excellent choice for users unfamiliar with graph databases who wish to learn how to interact with them. Neo4j and Cypher are included in the Database module of DataScientest’s Data Engineer training program, along with SQL, MongoDB, Elasticsearch and Cassandra.








