Data collection is the first step in creating a Machine Learning model. It is therefore essential to choose a database model that offers the features your application needs most.
Relational and NoSQL databases are the two most widely used system families. They differ in structure, data storage and accessibility. In this article, we'll look at each of their specific features of different Database Types.
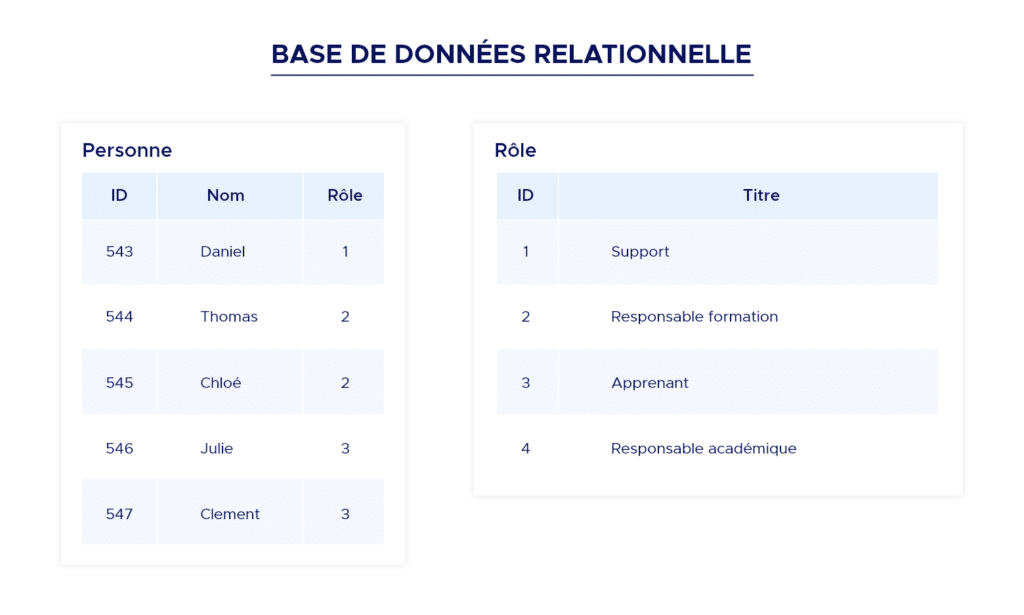
Database Types - Relational databases:
They are the oldest type of general-purpose database still widely used today. Relational databases organize data using tables. Tables are structures that impose a schema on the records they contain.
Each column in a table has a name and a data type. Each row represents a piece of data in the table, containing values for each column.
The SQL language was created to access data stored in this format and to guarantee ACID properties. They are often suited to regular, predictable data. As they are schema-based, it can be more difficult to modify the data structure once it is in the system.
Overall, relational databases are a solid choice for many applications, as applications often generate well-ordered, structured data.
Database Types - NoSQL database
The next types we’re going to look at belong to the NoSQL database family: high-performance alternatives for data that doesn’t fit the relational model.
They excel in ease of use, scalability, resilience and availability.
Document-oriented database
A good choice for rapid development, as you can change the properties of the data you wish to save at any time without modifying existing structures or data.
Each document is autonomous and has its own organization system. If you haven’t yet determined your data structure, this template could be a good starting point.
Be careful, however, as flexibility means that you are responsible for maintaining consistency, which can be extremely difficult.
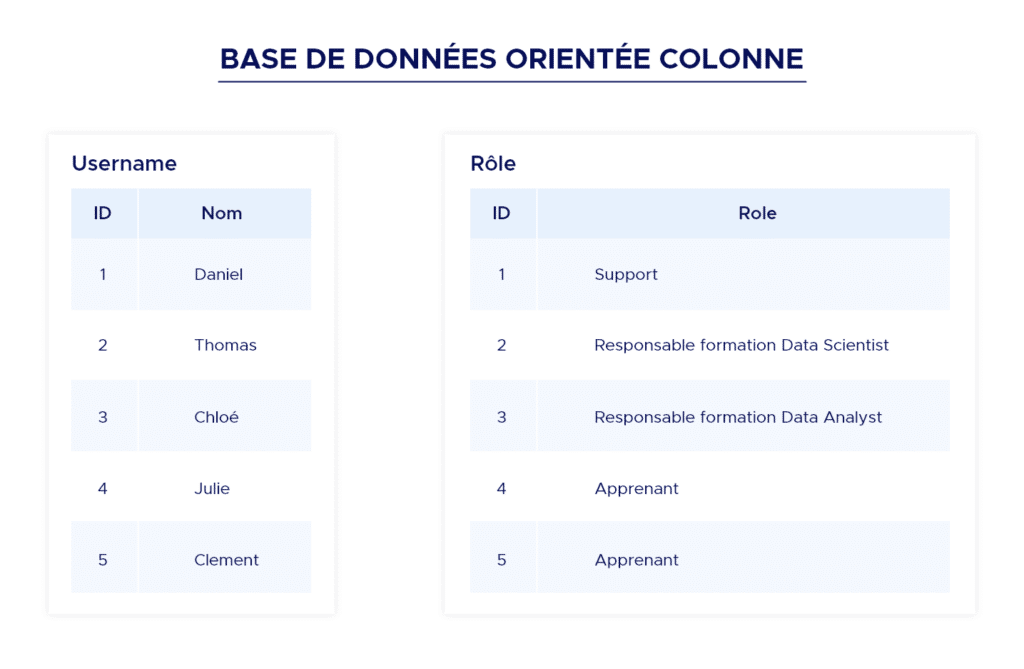
Column-oriented database
Useful for applications requiring high performance for online operations and scalability. As all the data and metadata in an entry can be accessed with a single line identifier, no computationally expensive joins are needed to find and extract information.
However, they don’t work well in all cases. If you have highly relational data requiring joins, this is not the right model to use.
Graph-oriented database
They are particularly useful when working with data with very large connections.
For example, finding the connection between two users of a social network in a relational database is likely to require multiple table joins and therefore be quite resource-intensive. This same query would be simple in a graphical database, which directly establishes correspondences between connections.
The aim of graphical databases is to make working with this type of data intuitive and powerful.
Choosing the right database involves not only choosing the right typology, but also understanding the CAP theorem.
In the next article, we’ll take a look at the CAP theorem, so that you’re fully equipped to start your Data project.
What if your Data project started with a Data Science training course designed by experts and certified by the Sorbonne?