
Spark Streaming is an innovative solution for real-time data processing. It is a component of the Apache Spark framework that offers exceptional performance, scalability and reliability.
This distributed real-time processing system has been designed to meet the most complex real-time data processing requirements. It enables complex analysis and transformation tasks to be performed on data from a variety of sources (such as social networks, connected devices or sensors).
Thanks to its advanced features, such as management of very large data flows, integration of various data sources and support for fault tolerance, Spark Streaming has established itself as the benchmark choice for companies looking to process real-time data efficiently.
The areas of application for such technology are extremely varied. Examples include fraud detection, financial market monitoring, personalised recommendations for online purchases, and of course social network analysis.
How does data streaming work?
Data streaming is a real-time process that involves processing data that is generated continuously and analysing it in real time.
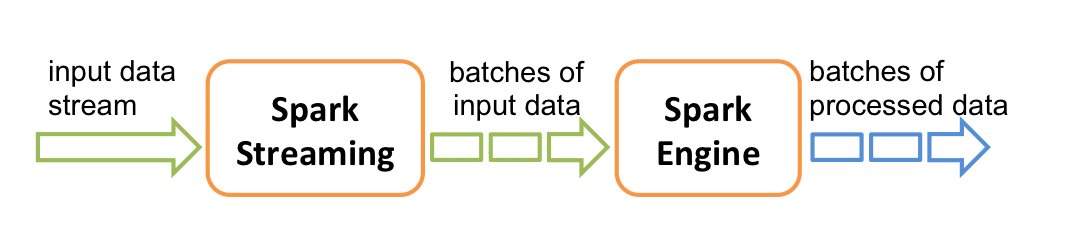
Spark Streaming uses a ‘micro-batch’ architecture, which means that data is divided into small batches and processed sequentially.
Each batch is treated as an RDD (Resilient Distributed Dataset) in Spark, allowing it to benefit from Spark’s parallel processing power. As a reminder, an RDD is the database unit in Apache Spark, which is an immutable collection of data shared in parallel across multiple nodes in a cluster.
What are DStreams?
Spark Streaming provides a high-level abstraction called a Discretized Stream, or DStream, which represents a continuous stream of data.
They can be thought of as continuous RDDs, where each RDD represents data generated within a defined interval.
DStreams can be created from input streams from sources such as Kafka, Twitter or Flume, or by applying high-level operations on other DStreams, and can be used to perform various operations such as filtering, aggregating, joining, etc., to produce the resulting data in real time.

Let's take an example:
Imagine you work for a public transport company that wants to monitor passengers getting on and off buses in real time. To do this, the buses are equipped with sensors that send continuous information to the company’s servers.
Spark Streaming will allow us to use a DStream to process this data in real time, where each DStream will represent the data sent by the bus sensors in predefined time intervals. We will use operations on these DStreams to perform our real-time analyses.
Using aggregations, we can obtain the total number of passengers on the buses at any one time. We’ll also be able to use filters to identify buses that have reached their maximum capacity, so that we can send out passenger safety alerts.
In short, thanks to Spark Streaming we can carry out real-time analyses on the data sent by the sensors, and use the results to improve the safety and efficiency of the public transport system.
What about fault tolerance and replication?
Spark Streaming guarantees fault tolerance using data replication and job recovery techniques.
Data replication involves duplicating data across multiple nodes to ensure that it is available in the event of a node failure. This measure also ensures the robustness of the system by guaranteeing that the data will not be lost.
Job resumption, on the other hand, is a mechanism that enables jobs to be restarted on other nodes in the event of a failure, so as to guarantee continuity of data processing even in the event of a problem.

Conclusion
Spark Streaming can therefore be used to address Big Data issues in real time. The fact that it supports a variety of data sources, and that it allows you to use a single framework for a wide range of needs, is nonetheless a significant advantage.








