
Hierarchical Clustering Algorithm(AHC): Clustering is a specific discipline within Machine Learning with the goal of dividing your data into homogeneous groups with common characteristics. This is a highly valued field, especially in marketing, where the aim is often to segment customer databases to identify specific behaviors.
In a previous article, we introduced a clustering algorithm known as K-means.
In this article, we will delve into the workings of the Agglomerative Hierarchical Clustering Algorithm(AHC). The Agglomerative Hierarchical Clustering Algorithm(AHC) is a well-known unsupervised algorithm in the field of clustering.
Its applications are diverse, including customer segmentation, data analysis, image segmentation, and semi-supervised learning, among others.
Hierarchical Clustering Algorithm(AHC) - The Principle
Given points and an integer k, the algorithm aims to divide the points into k groups, called clusters, that are homogeneous and compact. Let’s look at the example below:


On this 2D dataset, it’s clear that we can divide it into 3 groups. How do we go about it concretely?
The initial idea is to consider that each point in your dataset is a centroid. This means that each point corresponds to a unique label (0, 1, 2, 3, 4…).
Then, we group each centroid with its nearest neighbor centroid. The latter takes on the label of the centroid that “absorbed” it.
Next, we calculate the new centroids, which will be the centers of gravity of the newly created clusters.
We repeat this process until we obtain a single cluster or a predefined number of clusters.
In our example, the optimal number of clusters is 3, and the final result is shown on the right-hand side.
To better understand the mechanism of the Hierarchical Clustering Algorithm(AHC), we can illustrate it with a simple diagram:

At the beginning, each letter is considered as a cluster, and then they are gradually grouped together based on their proximity to eventually form only one group: abcdef.
Hierarchical Clustering Algorithm(AHC): Distance criteria
You will understand that in the Hierarchical Clustering Algorithm(AHC), three key points are:
1. What metric is used to evaluate the distance between centroids?
2. How many clusters should be chosen?
3. On what criterion do we decide to group centroids together?
In hierarchical agglomerative clustering, the distance typically used is the Euclidean distance, where p = (p1, …, pn) and q = (q1, …, qn).

It allows us to evaluate the distance between centroids. At each step of merging two centroids, a new cluster is formed, and a new centroid is calculated, which is simply the center of gravity of the data points within that cluster, as explained earlier.
This is where the concept of intra-cluster inertia comes into play. It’s simply the sum of the Euclidean distances between each point associated with the cluster and the newly calculated center of gravity. Naturally, when you merge clusters, you increase the intra-cluster inertia. The challenge is to minimize this increase. Thus, if you have the choice of merging a cluster with 4 or 5 other different clusters, you would choose the one that minimizes the increase in intra-cluster inertia.
This method is the principle of Ward’s criterion, which is often used for Hierarchical Agglomerative Clustering. There are other criteria, but Ward’s criterion is the default when implementing hierarchical agglomerative clustering in Python with Scikit Learn.
In the previous example, it was easy to find the ideal number of clusters by visually inspecting the data. However, datasets often have more than two dimensions, making it difficult to visualize the data and quickly identify the optimal number of clusters. You can decide the number of clusters beforehand when using the Hierarchical Clustering Algorithm(AHC). Suppose in the previous example we hadn’t visualized the data beforehand and decided to test with different numbers of clusters. Here are the results obtained:

The partitioning is incorrect because the optimal number of clusters is 3. A well-known method for finding the optimal number of clusters is to use a dendrogram like this one:

It allows you to visualize the successive groupings until you get a single cluster. It is often relevant to choose the partition corresponding to the largest jump between two consecutive clusters.
The number of clusters then corresponds to the number of vertical lines crossed by the horizontal cut of the dendrogram. In our example above, the horizontal cut corresponds to the two red lines. There are 3 vertical lines crossed by the cut. We can deduce that the optimal number of clusters is 3.
Let's get practical with Python and Hierarchical Clustering Algorithm (AHC)
The training of a Hierarchical Clustering Algorithm(AHC) is facilitated with the Scikit-Learn library. A dataset like the one used in the example can be easily created using Scikit-Learn’s make_blobs functionality.
Once our dataset is generated, we can proceed with the implementation of AHC. We will use the Scikit-Learn library.
Here’s how to implement it in code:
The n_clusters attribute allows you to specify the number of clusters desired for the classification. By default, the distance used is the Euclidean distance. Also, the “linkage criterion” called linkage is set to the Ward criterion by default.
Hierarchical Clustering Algorithm(AHC): The limits
As we have seen, the algorithm requires defining the number of partitions beforehand. This demands a precise idea, and even though we have seen a method to optimize for some datasets, it is not foolproof. For instance, datasets with elliptical shapes may pose a problem.
In the example below, it’s evident that there are two groups resembling two ellipses. The figure on the right shows the result after using AHC, and it’s clear that it didn’t manage to identify our two ellipses.
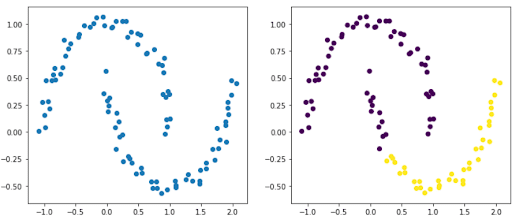
Also, hierarchical agglomerative clustering can quickly become very time and resource-consuming. One way to circumvent this problem is by providing a connectivity matrix. This is a sparse matrix indicating which pairs of observations are neighbors.
Using a clustering algorithm like Hierarchical Agglomerative Clustering is not always straightforward depending on the data you have. You often need to preprocess the data. At DataScientest, we teach you how to master the main clustering algorithms and interpret them on various datasets. Don’t hesitate to explore our training offers to learn how to master clustering algorithms and many other areas of Machine Learning.








