


What do these three people have in common? None of them exist in real life, and each of these photos was generated by this website. But how can this website succeed in generating such photorealistic and diverse individuals?
Thanks to the StyleGAN2 algorithm developed by a team of researchers from NVIDIA! This algorithm, still very recent (February 2019), builds upon an initial version published by the team in 2018 and is itself based on the GAN architecture.
What is a GAN ?
A GAN (Generative Adversarial Network) is a highly effective and widely used unsupervised learning algorithm in certain computer vision problems.
It is particularly this type of machine learning algorithm that is used to create deepfakes, which we discussed in one of our previous articles.
In concrete terms, a GAN consists of two neural networks that train simultaneously against each other to create fake images.
The first one is the generator (G), which generates fake face images from a random noise vector (z). This allows the algorithm to generate a different face with each new iteration.
The discriminator (D), on the other hand, learns to distinguish fake images created by the generator from real-life images. In practice, it acts as a classifier.
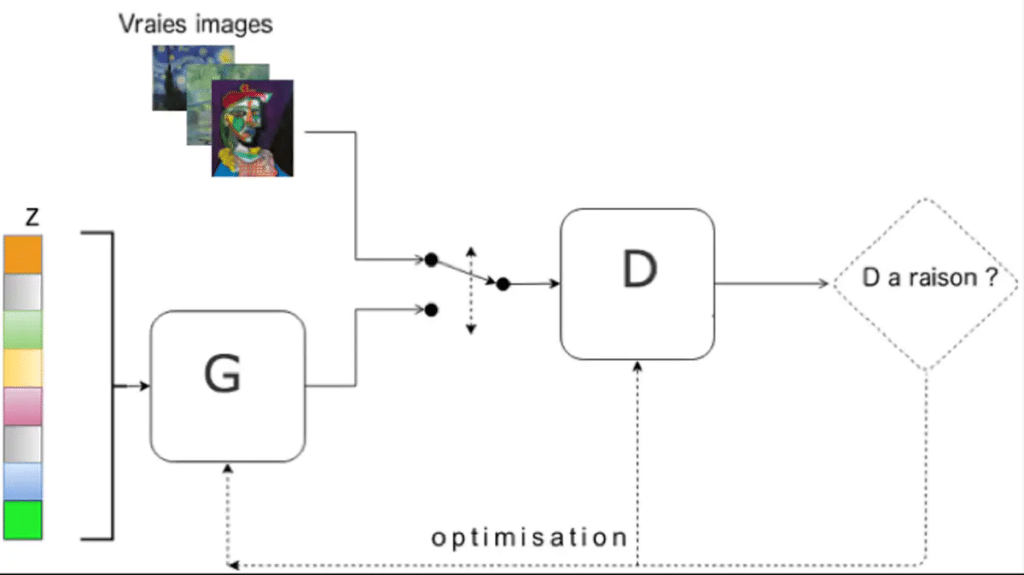
At the beginning, neither of the two networks is trained. During the training process, the discriminator is exposed to both real images and images generated by the generator. Its objective is to distinguish the source of each image. In parallel, the generator learns to create an image that can deceive the discriminator. As training progresses, the generator becomes increasingly effective at generating realistic images while the discriminator becomes better at identifying errors in the fake images.
It is through this adversarial learning process that the neural network can learn to create lifelike photographs of people with such realism.
Where does GAN come from?
Artificial intelligence has made tremendous strides in tasks like identifying objects in an image or mastering complex games by playing against itself thousands of times. However, a significant challenge arises when we ask AI to create something entirely new, something that didn’t exist before. This is because AI can simulate our intelligence but not our imagination.
In 2014, during a debate in a bar with fellow doctoral students, a student from the University of Montreal named Ian Goodfellow had an idea for overcoming this obstacle.
Like much in science, his inspiration drew from previous research, such as the work published by Jürgen Schmidhuber in the 1990s on “Predictability Minimization” and “Artificial Curiosity,” as well as the concept of “Turing Learning.”
What is GAN for?
One of the latest and most surprising applications of this technology, which allows us to “put one face on another,” is the generator of fake human faces, such as DCGAN developed by Nvidia. This technology now enables the generation of hyper-realistic (or nearly so) faces that correspond to no real person.
Building on this technology, several web generators have been developed, expanding beyond faces to include characters from manga or even cats.
However, the utility of a GAN is not limited to images alone. It can also be used in videos, as seen with the highly controversial Deepfakes.
Nevertheless, Goodfellow believes that his creation can offer much more to humanity. GAN has the potential to generate objects that we can use in the real world. In the not-so-distant future, GAN could be applied in various fields such as drug design, faster computer chips, earthquake-resistant buildings, more efficient vehicles, or affordable housing. It’s important to note that this technology is still in its infancy.
StyleGAN improvements
However, the architecture of GAN still has some limitations:
1. Generating high-resolution images is challenging for GANs. The number of parameters to learn right from the start is particularly high.
2. Generated images lacked diversity. GANs are quite sensitive to what’s known as “mode collapse,” where the generator consistently produces the same images that manage to fool the discriminator.
3. It’s difficult to control the output characteristics of the generated images.
Progressive growing addresses the resolution limitations. Essentially, adaptive growing involves training the model on images with increasing resolution. As the learning progresses, layers are added to both the generator and discriminator to work on higher-resolution images while benefiting from the learning already achieved.
Furthermore, progressive growing also improves the algorithm’s stability and the diversity of created images.

To control the characteristics of the generated images, there’s an effort to decorrelate (disentangle) the noise vector (z) from the desired features.
Let’s imagine that we want to generate a person with glasses: modifying just one value of the noise vector could lead to many different changes. This is because a single noise value isn’t directly correlated with a single image feature. Therefore, the goal is to disentangle the dimensions of the noise vector from the image features.
Disentanglement is achieved, in part, by creating an intermediate noise vector in a subspace where the dimensions are decorrelated.
Finally, StyleGAN incorporates other more complex improvements such as Adaptive Instance Normalization and style mixing.
Conclusion
By addressing certain shortcomings of the traditional GAN, StyleGAN and its successor, StyleGAN2, have defined a state-of-the-art approach for generating realistic images through machine learning. However, there are still some areas for improvement, such as handling backgrounds. You can practice spotting images by playing the discriminator on this site.
If you want to learn more about computer vision and artificial intelligence applied to images, consider exploring one of our training programs.








