
Hadoop is an Open Source framework dedicated to Big Data storage and processing. Discover everything you need to know: definition, history, functioning, advantages, training…
For several decades, companies mainly stored their data in the Relational DataBases Management System (RDBMS) in order to store them and perform queries. However, this type of database does not allow the storing of unstructured data and is not adapted to the vast volumes of Big Data.
Indeed, digitalization and the appearance of many technologies such as IoT and smartphones have caused an explosion in the volume of raw data. Faced with this revolution, new technologies are needed for data storage and processing. The Hadoop software framework allows us to respond to these new constraints.
What is Hadoop?
Hadoop is a software framework dedicated to the storage and processing of large volumes of data. It is an open source project, sponsored by the Apache Software Foundation.
It is not a product but a framework of instructions for the storage and processing of distributed data. Various software vendors have used Hadoop to create commercial Big Data management products.
Hadoop’s data systems are not limited in terms of scale, which means that more hardware and clusters can be added to support a heavier load without reconfiguration or the purchase of expensive software licenses.
The history of Hadoop
The origin of Hadoop is closely linked to the exponential growth of the World Wide Web over the last decade. The web has grown to include several billion pages. As a result, it has become difficult to search for information efficiently.
We have entered the era of Big Data. It has become more complex to store information efficiently for easy retrieval, and to process the data after storing it.
To address this problem, many open source projects have been developed. The goal was to provide faster search results on the web. One of the solutions adopted was to distribute the data and the calculations on a cluster of servers to allow simultaneous processing.
This is how Hadoop was born. In 2002, Doug Cutting and Mike Caferella of Google were working on the Apache Nutch open source web crawler project. They faced difficulties in storing the data, and the costs were extremely high.
In 2003, Google introduced its GFS file system: Google File System. It is a distributed file system designed to provide efficient access to data. In 2004, the American firm published a white paper on Map Reduce, the algorithm for simplifying data processing on large clusters. These publications of Google have strongly influenced the genesis of Hadoop.
Then in 2005, Cutting and Cafarella unveiled their new NDFS (Nutch Distributed File System) file system that also included Map Reduce. When he left Google to join Yahoo in 2006, Doug Cutting based on the Nutch project to launch Hadoop (whose name is inspired by a stuffed elephant of Cutting’s son) and its HDFS file system. The version 0.1.0 is relaxed.
Afterwards, Hadoop does not stop growing. It becomes in 2008 the fastest system to sort a terabyte of data on a cluster of 900 nodes in only 209 seconds. Version 2.2 was released in 2013, and version 3.0 in 2017.
In addition to its performance for Big Data, this framework has brought many unexpected benefits. In particular, it has brought down the cost of server deployment.
What are the four modules in Apache Hadoop?
Apache Hadoop relies on four main modules. First, the Hadoop Distributed File System (HDFS) is used for data storage. It is comparable to a local file system on a conventional computer.
However, its performance is much better. HDFS also delivers excellent elasticity. It is possible to scale from a single machine to several thousand of them very easily.
The second component is the YARN (Yet Another Resource Negotiator). As its name suggests, it is a resource negotiator. It allows you to schedule tasks, manage resources and monitor cluster nodes and other resources.
For its part, the Hadoop MapReduce module helps programs perform parallel computations. The Map task converts data into key-value pairs. The Reduce task consumes the input data, aggregates it and produces the result.
The last module is Hadoop Common. It uses standard Java libraries between each module.
How does Hadoop enable Big Data processing?
Hadoop’s processing of Big Data is based on the use of distributed storage and processing capacity of clusters. This is a foundation for building Big Data applications.
Applications can collect data in different formats and store it in the Hadoop cluster through an API connecting to the NameNode. The NameNode captures the file folder structure, and replicates chunks between different DataNodes for parallel processing.
Data queries are performed by MapReduce, which also maps all DataNodes and reduces data-related tasks in HDFS. Map tasks are performed on each node, and reducers are run to link the data and organize the final result.
What are the different tools in the Hadoop ecosystem?
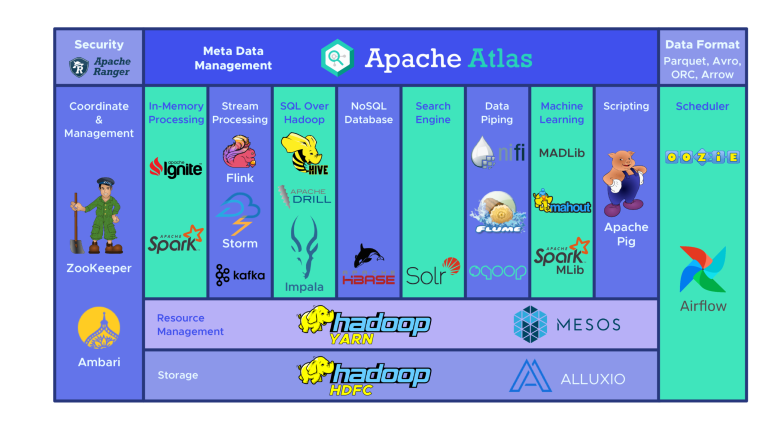
The Hadoop ecosystem includes a wide variety of open source Big Data tools. These various tools complement Hadoop and enhance its Big Data processing capability.
Among the most popular, Apache Hive is a Data Warehouse dedicated to processing large datasets stored in HDFS. The Zookeeper tool automates failovers and reduces the impact of a NameNode failure.
For its part, HBase is a non-relational database for Hadoop. The Apache Flume distributed service enables data streaming of large amounts of log data.
Also worth mentioning is Apache Sqoop, a command-line tool for migrating data between Hadoop and relational databases. The Apache Pig development platform enables the development of jobs to be run on Hadoop.
The Apache Oozie scheduling system facilitates the management of Hadoop jobs. Finally, HCatalog is a table management tool for sorting data from various processing systems.
What are the advantages of Hadoop?
The advantages of Hadoop are numerous. Firstly, this framework allows for faster storage and processing of large volumes of data. This is a valuable asset in the age of social networks and the Internet of Things.
Furthermore, Hadoop offers the flexibility to store unstructured data of any kind such as text, symbols, images or videos. Unlike a traditional relational database, data can be stored without being processed first. The operation is therefore comparable to a NoSQL database.
In addition, Hadoop also provides significant processing power. Its distributed computing model offers performance and efficiency.
This open source framework also makes it possible to tackle Big Data at a lower cost, since it can be used free of charge and freely. It also relies on very common hardware to store data.
Another major advantage is its elasticity. You can simply change the number of nodes in a cluster to expand or reduce the system.
Finally, Hadoop does not depend on hardware to preserve data availability. Data is automatically copied multiple times to different nodes in the cluster. If one device fails, the system automatically redirects the task to another. The framework is therefore fault-tolerant.
What are the weaknesses of Hadoop?
Despite all its strengths, Hadoop also has weaknesses. Firstly, the MapReduce algorithm is not always adequate. It is suitable for the simplest information queries, but not for iterative tasks. It is also not effective for advanced analytical computing, since iterative algorithms require intensive intercommunication.
For data management, metadata and data governance, Hadoop does not offer suitable and understandable tools. There is also a lack of tools for data standardization and quality determination.
Another problem is that Hadoop is difficult to master. Therefore, there are few programmers who are competent enough to use MapReduce. This is why many vendors add SQL database technology on top of Hadoop. There are significantly more programmers who are proficient in SQL.
The final weakness is data security. However, the Kerberos authentication protocol helps secure Hadoop environments.
What are the use cases for Hadoop?
Hadoop offers multiple possibilities. One of its main use cases is Big Data processing. This framework is indeed adapted to the processing of vast volumes of data, of the order of several petabytes.
Such volumes of information require a lot of processing power, and Hadoop is the right solution. An enterprise that needs to process smaller volumes, in the order of a few hundred gigabytes, will have to make do with an alternative solution.
Another major use case for Hadoop is the storage of various data. The flexibility of this framework allows it to support many different types of data. It is possible to store text, images, or even videos. The nature of the data processing can be selected according to the needs. This gives us the flexibility of a data lake.
In addition, Hadoop is used for parallel data processing. The MapReduce algorithm is used to orchestrate the parallel processing of stored data. This means that several tasks can be performed simultaneously.
How are companies using Hadoop?
Companies from all industries use Hadoop for Big Data processing. For example, the framework helps to understand customer needs and expectations.
Large companies in the financial and social networking industries use this technology to understand consumer expectations by analyzing Big Data on their activity, on their behavior.
From this data, it is possible to propose personalized offers to customers. This is the principle behind targeted advertising on social networks or recommendation engines on e-commerce platforms.
This leads to better decisions and higher profits. By analyzing data on employee behavior and interactions, it is also possible to improve the work environment.
In the healthcare industry, medical institutions can use Hadoop to monitor the vast amount of data related to health problems and medical treatment outcomes. Researchers can analyze this data to identify health problems and choose appropriate treatments.
Traders and more generally, the financial world also use Hadoop. Its algorithm scans market data to identify opportunities and seasonal trends. Finance companies can automate operations using the framework.
In addition, Hadoop is used for the Internet of Things. These devices require data to function properly. Therefore, manufacturers use Hadoop as a data warehouse to store the billions of transactions recorded by the IoT. This way, the data streaming can be managed properly.
These are just a few examples. In addition, Hadoop is used in the field of sports and scientific research.
How to learn to use Hadoop?
In summary, Hadoop is very useful for Big Data processing when implemented and used correctly. This versatile and multipurpose tool is ideal for companies dealing with large volumes of data.
In this context, learning to master Hadoop can be very useful. Your skills will be highly sought after by many organizations in all industries, so you can easily find a well-paying job.
If you are a business owner, you can also fund Hadoop training for your employees. This will enable them to handle Big Data and seize all the opportunities offered.
DataScientest’s Data Engineer training offers to learn how to master Hadoop, and all the data engineering tools and techniques. The program is divided into five modules: programming, database, Big Data Volume, Big Data Speed, and automation and deployment.
Throughout the course, learners will discover Hadoop, but also Hive, Hbase, Pig, Spark, Bash, Cassandra, SQL or even Kafka. At the end of the training, a Data Engineer diploma certified by the Sorbonne University is awarded.
This course allows students to train as data engineers. Among the alumni, 93% found a job immediately after graduation. The skills acquired can be used directly in companies.
The program can be completed in 9 months in bootcamp, or 11 weeks in continuing education. All of our courses adopt an innovative hybrid approach of Blended Learning, combining face-to-face and distance learning.








