
Motivation
Machine Learning Development goes beyond developing a model. Productionizing a model quickly becomes a multi-faceted, indeed even a multi-disciplinary process that involves several key stakeholders across both the business and IT. As depicted in the image below, the code to actually develop a model is a small component compared to other complexities such as configuring serving infrastructure, data verification, and monitoring.
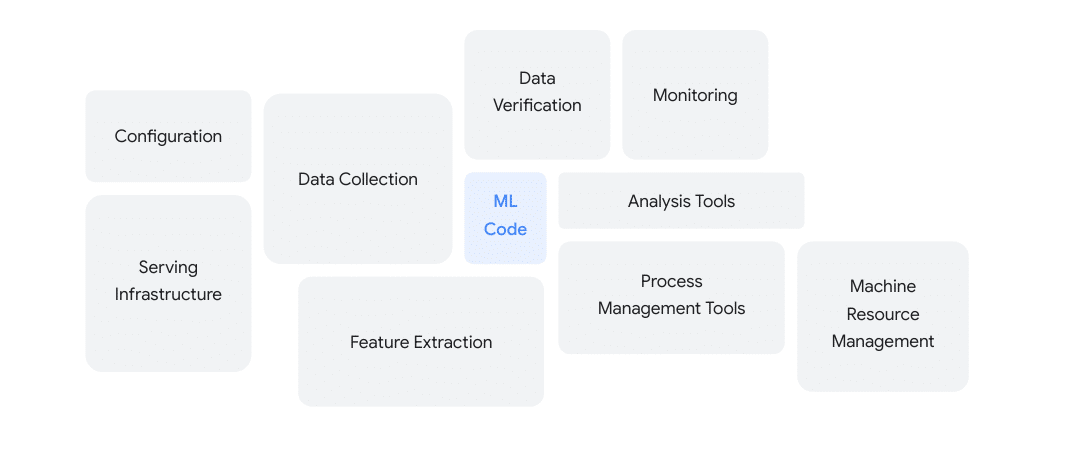
Purpose
The goal of this article is to serve as a gentle introduction to Kubeflow pipelines and how it can address the challenges in ML Learning Lifecycle development. To address all the components in the image above would go beyond the scope of a short blog. For the sake of simplicity, we are going to reference Vertex Pipelines on Google Cloud for our example. Note that Kubeflow is an open source project and can be deployed in several different environments.
What is Kubeflow ?
Kubeflow is an open-source MLOps (Machine Learning Operations) platform built on top of Kubernetes. It simplifies and automates various stages of the machine learning lifecycle, from data preparation and model training to deployment and monitoring. Think of it as a toolkit that helps you build and manage your ML workflows efficiently and portably across different platforms.
Here are some key aspects of Kubeflow:
- Components: It provides a collection of components for different stages of the ML lifecycle, such as pipelines for data processing, notebooks for experimentation, training jobs for model training, and KFServing for model deployment.
- Kubernetes integration: It leverages Kubernetes for resource management, scheduling, and scaling. This makes Kubeflow workflows portable and scalable across different environments.
- Flexibility and customization: You can tailor your ML workflows by choosing and configuring the specific components you need.
- Community-driven: Kubeflow is an active open-source project with a vibrant community that contributes to its development and supports users.
Several different cloud providers (AWS, Google Cloud, Microsoft Azure ) offer pre-configured Kubeflow distributions that can be installed on a Kubernetes cluster. For this article, Vertex Pipelines will be used since it is a fully-managed Kubeflow service. Fully managed cloud services are cloud services that are handled by a cloud service provider using automations, typically meaning that a developer doesn’t have to set up and manage machines, patching, or backing up clusters.
Pipelines and components
A Kubeflow Pipeline is a platform-agnostic way to define, orchestrate, and manage repeatable, end-to-end machine learning (ML) workflows based on containers.
Think of a pipeline as the workflow for your machine learning job. A pipeline is built up from components. Components are light weight abstractions of a task in a pipeline. These tasks can be isolated containers or implementations of a function. This is useful because now we can reap several benefits in our machine learning workflows
- Modularity: Components break down complex machine learning workflows into manageable, reusable steps. This improves organization and scalability.
- Reusability: Well-defined components can be used across various pipelines, reducing code duplication and promoting efficiency.
- Flexibility: You can develop Kubeflow components in various ways, giving you flexibility in your technology choices.
Hello Kubeflow - A Rudimentary Example
In this example we are going to create 3 functions
- Example_string will take a string and append some text to the string
- Example_number will take a number and add 10
- Example_combo will take the output of both of those function return a string of the out

- We are using the kfp.dsl.component decorator to transform our python functions into components
- Each of these components will be executed in their own container, note that we are defining our base image as well as our packages to install.
Next we are going to define our pipeline, which will in turn define how the components are going to interact with each other. In this case, we are going to create a DAG pipeline which will take the output of the example_string() and example_number() functions and feed them into a the example_combo() function. Note that the pipeline creation is happening inside the example_pipeline() function and we are using the kfp.dsl.pipeline decorator.

After defining the pipeline function, the next step is to compile the pipeline. The output of this compilation is a YAML template (can also be JSON) that will give the instructions to the Kubeflow service on how to create the pipeline and its components. In this example, we are submitting the template to Google Cloud’s Vertex Pipelines for execution.

A Minimalistic End-to-End Pipeline
Installation
! pip3 install --no-cache-dir --upgrade "kfp>2" \
google-cloud-aiplatform
import google.cloud.aiplatform as aiplatform
import kfp
from kfp import compiler, dsl
from kfp.dsl import Artifact, Dataset, Input, Metrics, Model, Output, component
from kfp.dsl import ClassificationMetrics
from typing import NamedTuple
import os
PROJECT_ID = '<YOUR-PROJECT-ID>' # replace with project ID
REGION = '<YOUR-REGION>'
EXPERIMENT = 'vertex-pipelines'
SERIES = 'dev'
# gcs bucket
GCS_BUCKET = PROJECT_ID
BUCKET_URI = f"gs://{PROJECT_ID}-bucket" # @param {type:"string"}
aiplatform.init(project=PROJECT_ID, staging_bucket=BUCKET_URI)
Note that Vertex Pipelines require a Google Cloud Storage bucket to store pipeline metadata and artifacts. If you don’t have one created yet, you can create a bucket manually through the console or use this gsutil command line :
! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URI
Defining the components
We are going to create 4 different components
- get_data() – this will retrieve a curated breast cancer dataset from kaggle and perform a train/test split. Note that this example is using the Output[Dataset] artifact to store the metadata (such as the path of where the dataset is stored).
- train_model() – this will take the dataset artifact created in get_data(), train an XGBoost classification model, and finally use the Model Artifact to store the model and it’s metadata in a google cloud storage bucket. Note that custom metadata, such as the training score and framework, is being defined inside of the model artifact.
- eval_model() – this function will take the test dataset created from the get_data() and the model artifact created in the train_mode() as inputs and create an evaluation step. In an MLOps process, we may want to ensure that the machine learning model is meeting a certain performance threshold before deploying the model to an environment
- deploy_xgboost_model() – finally, if our model meets our conditions established in the eval_model(), the model will then be deployed to an Vertex AI Endpoint where it will service requests.
Note that this is a simplified and minimalistic example. In practice, instead of deploying the model directly in the same environment, there may be using several different environments (Dev UAT) that the model artifact has to traverse before being deployed to a production environment.
@dsl.component(base_image='python:3.8',
packages_to_install=[
"pandas==1.3.4",
"scikit-learn==1.0.1",
"google-cloud-bigquery==3.13.0",
"db-dtypes==1.1.1"
],
)
def get_data(
project_id: str,
dataset_train: Output[Dataset],
dataset_test: Output[Dataset]
) -> None:
""" Loads data from BigQuery, splits it into training and test sets,
and saves them as CSV files.
Args:
project_id: str
dataset_train: Output[Dataset] for the training set.
dataset_test: Output[Dataset] for the test set.
"""
from sklearn import datasets
from sklearn.model_selection import train_test_split
import pandas as pd
from google.cloud import bigquery
# Construct a BigQuery client object.
client = bigquery.Client(project=project_id)
job_config = bigquery.QueryJobConfig()
query = """
SELECT
* EXCEPT(fullVisitorId)
FROM
# features
(SELECT
fullVisitorId,
IFNULL(totals.bounces, 0) AS bounces,
IFNULL(totals.timeOnSite, 0) AS time_on_site
FROM
`data-to-insights.ecommerce.web_analytics`
WHERE
totals.newVisits = 1
AND date BETWEEN '20160801' AND '20170430') # train on first 9 months
JOIN
(SELECT
fullvisitorid,
IF(COUNTIF(totals.transactions > 0 AND totals.newVisits IS NULL) > 0, 1, 0) AS will_buy_on_return_visit
FROM
`data-to-insights.ecommerce.web_analytics`
GROUP BY fullvisitorid)
USING (fullVisitorId)
LIMIT 10000
;
"""
query_job = client.query(query, job_config=job_config)
df = query_job.to_dataframe()
# Split Data
train, test = train_test_split(df, test_size=0.3, random_state=42)
# Save to Outputs
train.to_csv(dataset_train.path, index=False)
test.to_csv(dataset_test.path, index=False)
@dsl.component(base_image='python:3.8',
packages_to_install=[
"xgboost==1.6.2",
"pandas==1.3.5",
"joblib==1.1.0",
"scikit-learn==1.0.2",
],
)
def train_model(
dataset: Input[Dataset],
model_artifact: Output[Model]
) -> None:
"""Trains an XGBoost classifier on a given dataset and saves the model artifact.
Args:
dataset: Input[Dataset]
The training dataset as a Kubeflow component input.
model_artifact: Output[Model]
A Kubeflow component output for saving the trained model.
Returns:
None
This function doesn't have a return value; its primary purpose is to produce a model artifact.
"""
import os
import joblib
import pandas as pd
from xgboost import XGBClassifier
# Load Training Data
data = pd.read_csv(dataset.path)
# Train XGBoost Model
model = XGBClassifier(objective="binary:logistic")
model.fit(data.drop(columns=["will_buy_on_return_visit"]), data.will_buy_on_return_visit)
# Evaluate and Log Metrics
score = model.score(data.drop(columns=["will_buy_on_return_visit"]), data.will_buy_on_return_visit)
# Save the Model Artifact
os.makedirs(model_artifact.path, exist_ok=True)
joblib.dump(model, os.path.join(model_artifact.path, "model.joblib"))
# Metadata for the Artifact
model_artifact.metadata["train_score"] = float(score)
model_artifact.metadata["framework"] = "XGBoost"
@dsl.component(base_image='python:3.8',
packages_to_install=[
"xgboost==1.6.2",
"pandas==1.3.5",
"joblib==1.1.0",
"scikit-learn==1.0.2",
"google-cloud-storage==2.13.0",
],
)
def eval_model(
test_set: Input[Dataset],
xgb_model: Input[Model],
metrics: Output[ClassificationMetrics],
smetrics: Output[Metrics],
bucket_name: str,
score_threshold: float = 0.8
) -> NamedTuple("Outputs", [("deploy", str)]):
"""Evaluates an XGBoost model on a test dataset, logs metrics, and decides whether to deploy.
Args:
test_set: Input[Dataset]
The test dataset as a Kubeflow component input.
xgb_model: Input[Model]
The trained XGBoost model as a Kubeflow component input.
metrics: Output[ClassificationMetrics]
A Kubeflow component output for logging classification metrics.
smetrics: Output[Metrics]
A Kubeflow component output for logging scalar metrics.
bucket_name: str
The name of the Google Cloud Storage bucket containing the model.
score_threshold: float, default=0.8
The minimum score required for deployment.
Returns:
NamedTuple("Outputs", [("deploy", str)])
A named tuple with a single field:
* deploy: str
A string indicating whether to deploy the model ("true" or "false").
"""
from google.cloud import storage
import joblib
import pandas as pd
from sklearn.metrics import roc_curve, confusion_matrix
from collections import namedtuple
# Load Test Data and Model
data = pd.read_csv(test_set.path)
client = storage.Client()
bucket = client.get_bucket(bucket_name)
blob_path = xgb_model.uri.replace(f"gs://{bucket_name}/", "")
smetrics.log_metric("blob_path", str(blob_path))
blob = bucket.blob(f"{blob_path}/model.joblib")
with blob.open(mode="rb") as file:
model = joblib.load(file)
# Evaluation and Metrics
y_scores = model.predict_proba(data.drop(columns=["will_buy_on_return_visit"]))[:, 1]
y_pred = model.predict(data.drop(columns=["will_buy_on_return_visit"]))
score = model.score(data.drop(columns=["will_buy_on_return_visit"]), data.will_buy_on_return_visit)
fpr, tpr, thresholds = roc_curve(data.will_buy_on_return_visit.to_numpy(), y_scores, pos_label=True)
metrics.log_roc_curve(fpr.tolist(), tpr.tolist(), thresholds.tolist())
cm = confusion_matrix(data.will_buy_on_return_visit, y_pred)
metrics.log_confusion_matrix(["False", "True"], cm.tolist())
smetrics.log_metric("score", float(score))
# ----- 3. Deployment Decision Logic -----
deploy = "true" if score >= score_threshold else "false"
# ----- 4. Metadata Update -----
xgb_model.metadata["test_score"] = float(score)
Outputs = namedtuple("Outputs", ["deploy"])
return Outputs(deploy)
@dsl.component(base_image='python:3.8',
packages_to_install=["google-cloud-aiplatform==1.25.0"],
)
def deploy_xgboost_model(
model: Input[Model],
project_id: str,
vertex_endpoint: Output[Artifact],
vertex_model: Output[Model]
) -> None:
"""Deploys an XGBoost model to Vertex AI Endpoint.
Args:
model: The model to deploy.
project_id: The Google Cloud project ID.
vertex_endpoint: Output[Artifact] representing the deployed Vertex AI Endpoint.
vertex_model: Output[Model] representing the deployed Vertex AI Model.
"""
from google.cloud import aiplatform
# Initialize AI Platform with project
aiplatform.init(project=project_id)
# Upload the Model
deployed_model = aiplatform.Model.upload(
display_name="xgb-classification",
artifact_uri=model.uri,
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/prediction/xgboost-cpu.1-6:latest",
)
# Deploy the Model to an Endpoint
endpoint = deployed_model.deploy(machine_type="n1-standard-4")
# Save Outputs
vertex_endpoint.uri = endpoint.resource_name
vertex_model.uri = deployed_model.resource_name
Defining the pipeline
Next step is to define the pipeline function. Similar to the initial example, the pipeline components are stitched together to create a Directed Acyclic graph of steps. The dsl.Condition is introduced as a control flow step for the evaluation function. In this case, if the evaluation criteria is met (returns true), the pipeline will proceed with the deployment.
PIPELINE_ROOT = BUCKET_NAME + "/pipeline_root/" # path to pipeline metadata @dsl.pipeline(
# Default pipeline root. You can override it when submitting the pipeline.
pipeline_root=PIPELINE_ROOT + "xgboost-pipeline-v2",
# A name for the pipeline. Use to determine the pipeline Context.
name="xgboost-pipeline-with-deployment-v2",
)
def pipeline():
dataset_op = get_data()
training_op = train_model(dataset = dataset_op.outputs["dataset_train"])
eval_op = eval_model(
test_set=dataset_op.outputs["dataset_test"],
xgb_model=training_op.outputs["model_artifact"],
bucket_name = "kubeflow-mlops-410520-bucket"
)
with dsl.Condition(
eval_op.outputs["deploy"] == "true",
name="deploy",
):
deploy_op = deploy_xgboost_model(model = training_op.outputs["model_artifact"],
project_id = PROJECT_ID,
)
Compiling and executing the pipeline
Finally, the pipeline is compiled to create the YAML template. That template is submitted to the Vertex AI platform service. The model is then trained and deployed to the endpoint :
compiler.Compiler().compile(pipeline_func=pipeline, package_path="pipeline-breast-cancer.yaml")
from google.cloud.aiplatform import pipeline_jobs
job = aiplatform.PipelineJob(
display_name="breast-cancer-demo-pipeline",
template_path="pipeline-breast-cancer.yaml",
pipeline_root=PIPELINE_ROOT,
)
job.run()
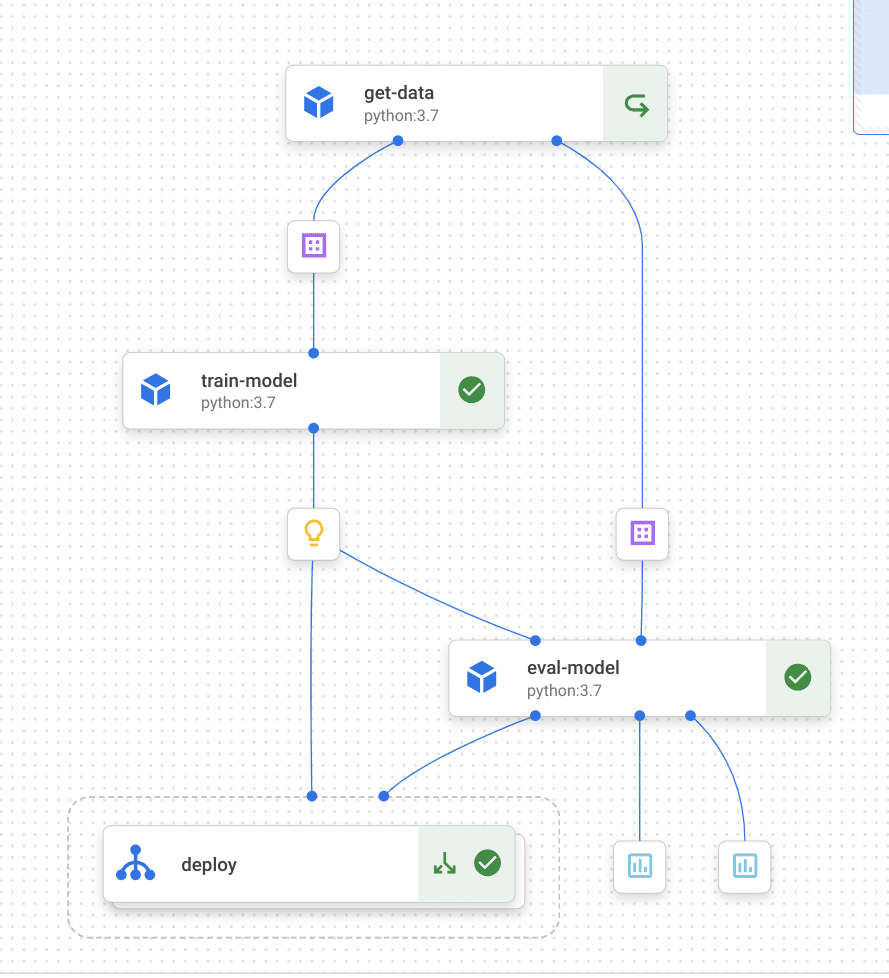
Conclusion
This article covers a lot of ground. To summarize we covered some basic components Kubeflow pipelines and their part to play in creating a modularize, reusable, and flexible machine learning workflows. We also created a minimalistic end-to-end pipeline on Googe Cloud. Congratulations !








