
In a previous article, we presented the DevOps philosophy, and how this new approach enables faster value delivery for businesses through the unification of development (Dev) and operations (Ops) teams, which previously worked in silos. In this article, we'll look at the application of this approach to Machine Learning problems: we're talking about MLOps.
Back to Devops
DevOps reduces time-to-market and improves the quality of software products, thanks to 3 principles:
- Disengagement: development and operations teams must work together towards a common goal, sharing all information.
- Automation: Everything that can be automated must be: build, test, deployment. This has the dual aim of reducing the time needed for deployment and the number of non-quality issues, as manual steps are prone to human error.
- Monitoring: collect and monitor important metrics, both on the business side (number of users connected, number of orders, etc.) and on the operations side (percentage of server CPU / RAM utilization, number of errors, etc.).
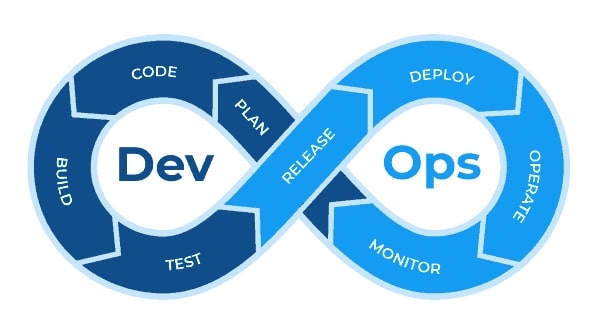
Following the massive adoption of DevOps and the significant increase in the use of Machine Learning and AI in the enterprise, DevOps concepts have been taken up in data projects. While the objectives and principles remain broadly the same, certain specific features of machine learning have necessitated the creation of a specific approach: MLOps.
What is MLOps?
According to a google documentation:
MLOps is an ML engineering culture and practice that aims to unify the development (Dev) and operations (Ops) of ML systems.
To understand what MLOps is, let’s focus on the differences with classic DevOps:
- Experimental development: by nature, all ML projects follow a non-linear development path: different preprocessing, feature engineering and algorithms are tested, until sufficient performance is achieved. Keeping track of what has and hasn’t worked can be complex.
- But it’s crucial for reducing development time, especially in the case of large teams, to avoid retesting approaches that have already been tried and failed by another data scientist.
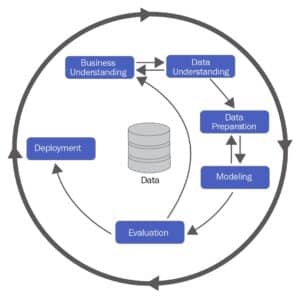
- Conceptual drift: unlike a conventional software product, an ML system can see its performance vary (and most of the time decline) over time, without any change in the code or infrastructure. This is due to the phenomenon of conceptual drift, in which the relationships between the variable to be predicted and the explanatory variables will evolve in unforeseen ways.
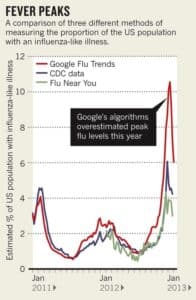
- It is therefore essential to monitor the performance of ML models in production, and potentially to implement an automatic re-learning strategy to “re-calibrate” the model when its performance declines. A case in point is Google Flu Trends, a Google project which was designed to estimate the number of cases of influenza based on searches made on the search engine, but which showed its limitations by significantly overestimating the number of cases after a few years of operation.
Team: In most organizations, cross-functional data teams or teams integrated into different business departments are relatively young, and lack the qualified resources to manage the deployment and maintenance of complex ML systems.
Indeed, these teams tend to consist mainly of data scientists who focus on the development of machine learning models, but lack the necessary skills to manage the deployment and maintenance of complete applications. What’s more, data teams still too often operate in silos, without communicating with the various technical teams with whom they would need to interact to put their models into production.
These specificities and complexities inherent to data projects partly explain why, while more and more companies are investing massively in machine learning and AI, very few models are actually deployed in production. According to a study conducted by Algorithmia in 2020, 55% of companies committed to AI have never carried out a production run.
The aim of MLOps is therefore to overcome these difficulties and enable ML systems to be deployed and run, applying principles similar to DevOps:
Monitoring: monitoring is becoming even more important in the MLOps philosophy, both in the run (notably by collecting model performance metrics to detect conceptual drift) and at the development stage (to track the various experiments and their results).
Culture: data teams mqust also work with other technical teams (operations, but also the teams developing the software products with which the ML models are to be integrated).
Automation: in addition to the classic stages (build, test, deploy), MLOps advocates the automation of tasks specific to the maintenance of ML systems, such as relearning models. Once models have been trained, they must also be automatically deployed.
To help data teams adopt an MLOps approach, a growing number of tools have been developed. These include MLflow, Metaflow and Kubeflow.
But to make the MLOps shift a success, it is essential to break down the silos between operations and data teams, and to ensure that the latter have the necessary resources (Data Engineers, Machine Learning Engineers). Machine Learning Engineers are experienced profiles with expertise in machine learning (statistical modeling, deep learning, etc.), software development, data engineering and the production roll-out of ML models.
Interested in becoming a MLOps? Find out more about our MLOps training course!








