
If you are a follower of our blog, you already know what a neural network is (if not, feel free to read this article first) but what does the adjective recurrent bring to this model? In this article, we will see how recurrent neural networks, called RNN, have become a classic model in deep learning.
How to set up this neural network in situations ?
Before explaining a RNN, let’s focus on a bullet. Indeed, it is common in Machine Learning to want to predict the trajectory of a movable object. As shown in figure 1, from the starting point, the ball can take all sorts of directions. How can we know what the next movement of the ball is?

However, if we take figure 2, it is obvious to say that the ball will continue to go towards the right, thanks to the past trajectories, which translate a movement towards the right.
So far, everything seems logical.
Contrary to figure 1, we have more training data, from which we are better able to decide on the movement of the ball.
Thus, we just need to give our neural network the old ball movements and our study is over. However, how do we choose the number of input neurons? A trajectory can be split in any way we want. Whether it is 10 or 100.

The white ball represents the current position of the ball and the light blue balls represent the old trajectories of the white ball, so we guess that the ball is heading to the right.
Let’s ignore this detail for now, and fix the size of our input samples. Let’s look at Figure 3, where will the ball go?

Admittedly, the motion of the ball is more complex than in figure 1, but we can still tell that the next move of the ball will be upwards. Will the model make the same prediction? Unfortunately not, because the neural network does not think like we do! The model, unlike us, does not take into account the link between the inputs. The inputs are not independent of each other, so we must preserve this link between them when we train our neural network.
We need to overcome 2 problems:
- The size of our input samples is not fixed.
- The input data are not linked together.
Let’s go back to our ball trajectory study. We will consider a plane, so the ball trajectory will have two coordinates, which we name x^1,x^2 and we want to predict the next location of the ball, the prediction of future coordinates will be ŷ^1,ŷ^2. Let us represent this with a traditional neural network.
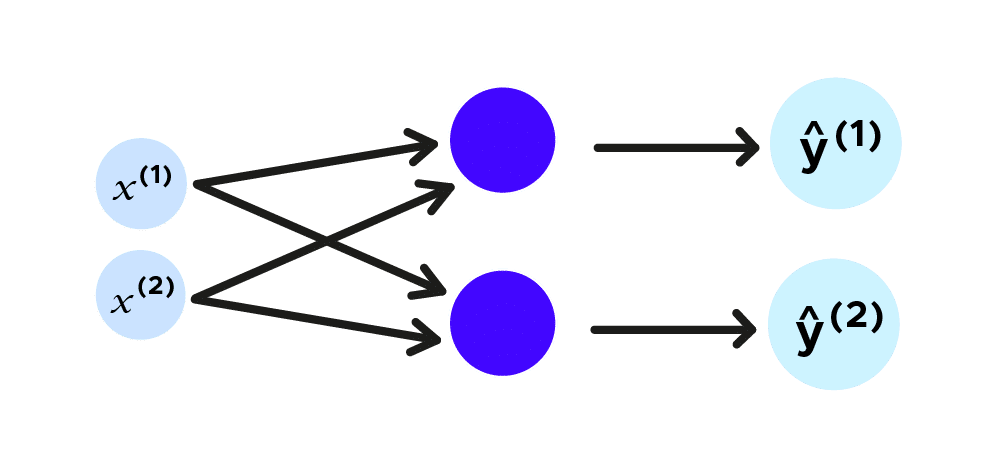
Synthetically, if we posit (x^1,x^2)=x_t and (ŷ^1,ŷ^2)=ŷ_t, we can make the diagram below:
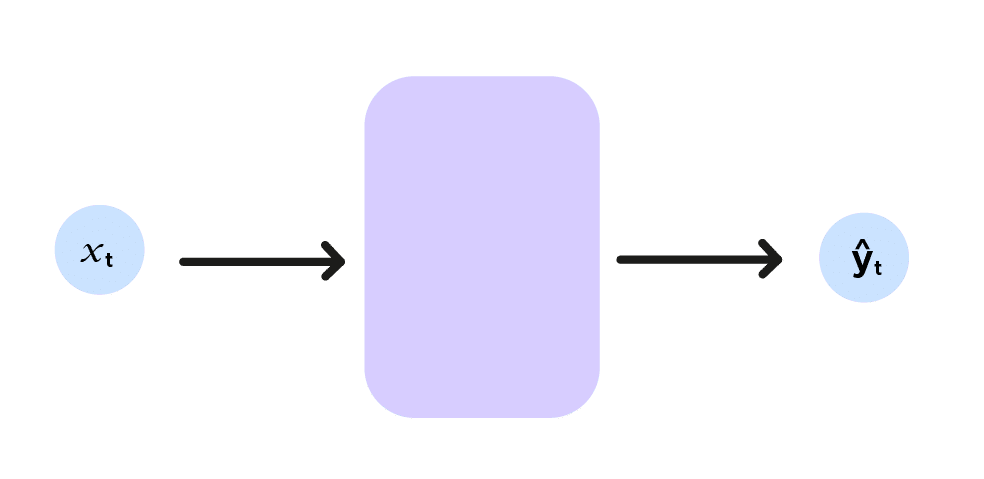
Here the index t indicates the coordinates of the ball at time t, representing the neural network by a function f, we have:
f(x_t)=ŷ_t (resume the mathematical style of the RNN formula)
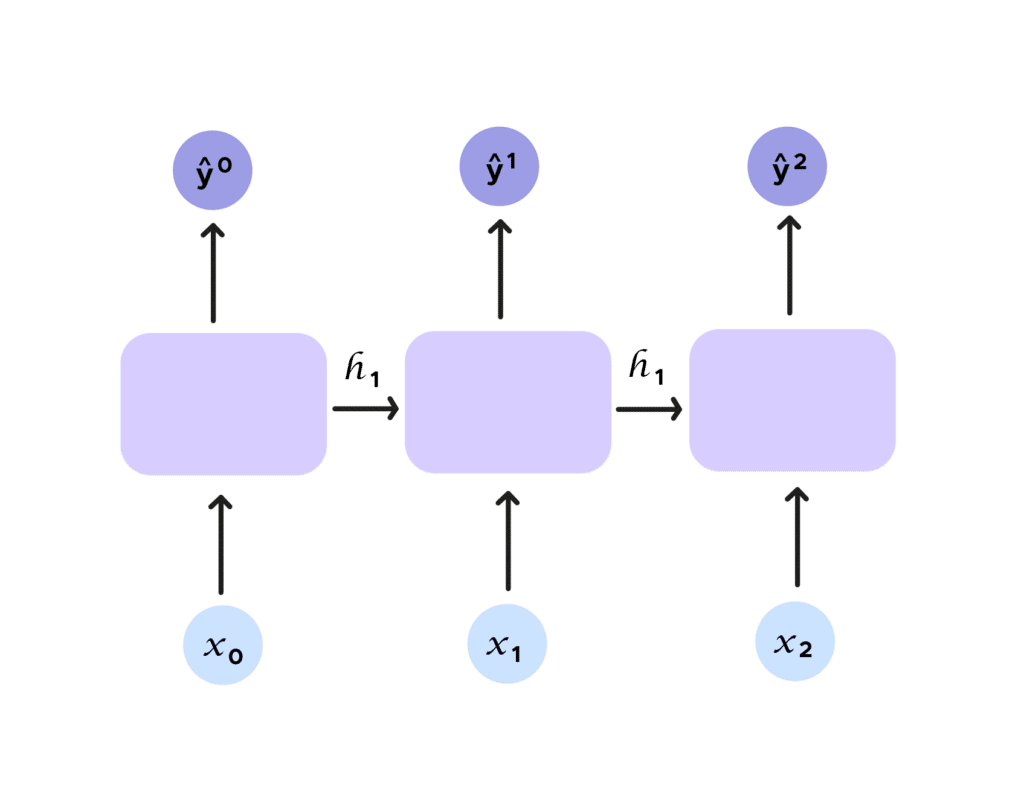
As mentioned earlier, we are studying the motion of the ball locally. We want to take into account several instants of the ball’s motion. If we can’t do this with a traditional neural network, with RNNs, everything changes, because the concept of recurrence is introduced. Indeed, let us observe the figure below. We add an input h_t, called hidden state. This hidden state embodies ŷ_t and is given as an argument to the next prediction in addition to the input x_t. We have indeed considered a set, and thus link outputs and inputs without bound for our input samples.
If we try to symbolize this with a formula, we get the following equation:
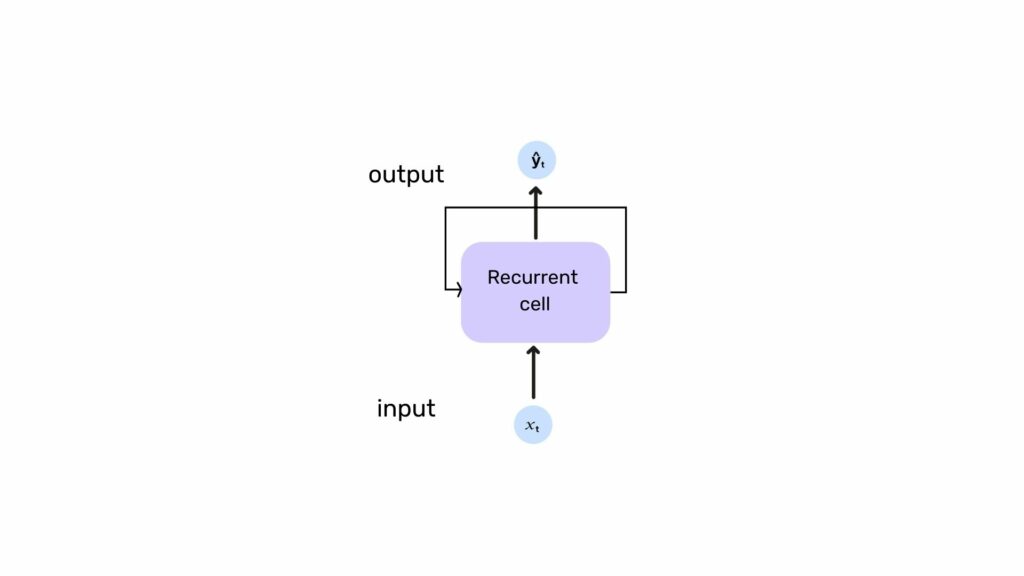
We can see the concept of recurrence. To predict the next term, we need previous information from h_{t-1}.
The recurrence is even more obvious in this summary diagram.
What are the different applications of RNNs?
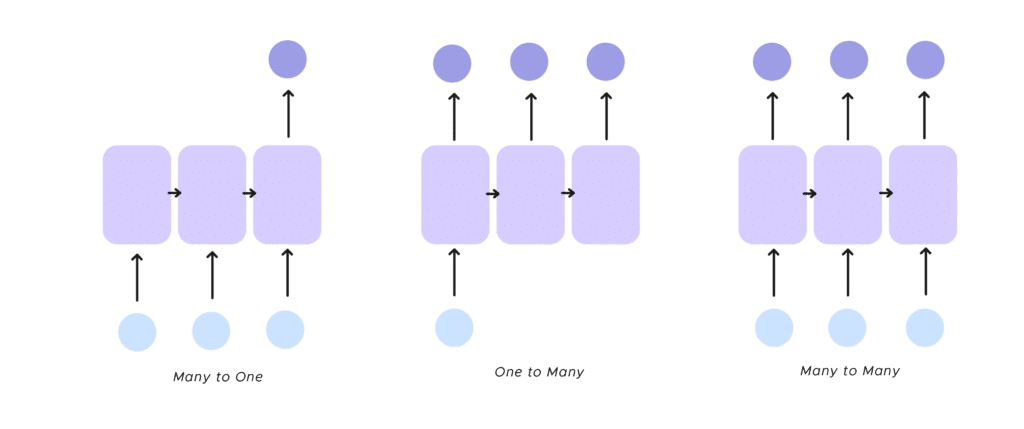
- One to many, The RNN receives a single input and returns multiple outputs, the classic example of this process is the image legend
- Many to one There are several inputs and there is a single output. An illustration of this mode is the sentiment analysis of texts. This makes it possible to identify a feeling from a group of words, determine the word that is missing to finish the sentence received as input.
- Many to many, Finally, you can take several inputs and get several outputs. We don’t necessarily have the same number of input and output neurons. We can cite, here, the translation of text, but we can be ambitious and plan to finish a musical work with its beginning.
Perfect, we have seen the operation of an RNN and its multiple applications, but is it perfect?
Unfortunately, it has a major drawback, called short-term memory, of which we will see an example in ANLP (Automatic Natural Language Processing).
Is the RNN a goldfish?
Take the case of sentence completion.
“I like sushi, I’m going to eat at the …“
The RNN can’t remember the word sushi to predict Japan, because they can’t remember the word sushi. In order to determine Japan, the RNN has to have a stronger memory. We can do that, by making neurons more complex. In particular, we will see the case of LSTM(Long Short Term Memory). In addition to the conventional hidden state h_t, we will add a second state called c_t. Here, h_t represents the short memory of the neuron and c_t the long memory.
We will not go into the technical considerations of this frightening scheme. The main point is that we have a much more complex cell, which allows us to solve the memory problem. With the LSTM, we run the h_t and c_t through doors, 4 of them.
- The first door eliminates unnecessary information, it’s the forget gate.
- The second door, stores the new information, the store gate.
- The third gate updates the information we will give to the RNN with the result of the forget gate and the store gate, it is the update gate.
- Finally, the last gate (output gate), gives us y_t and h_t.
This long process allows us to control the information we keep and transmit over time.
The RNN manages to know what to keep and what to forget, thanks to its learning. The LSTM (Long Short Term Memory) is not unique, we can also use GRU (Gated Recurrent Unit), just the architecture of the cell changes.
Let us now summarize what we have seen. NRNs are a particular type of neural network that can process data that are not independent and have no fixed size. However, standard NRNs are quite limited with the short memory problem, which we can solve by using more complex cells like LSTM or GRU.
In addition, we can draw a parallel with another neural network system: convolution neural networks (CNN). Indeed, NNCs are known to share spatial information while NRNs are known to share temporal information. Finally, if you want to put NRNs into practice, don’t hesitate to join one of our Data Scientist training.








