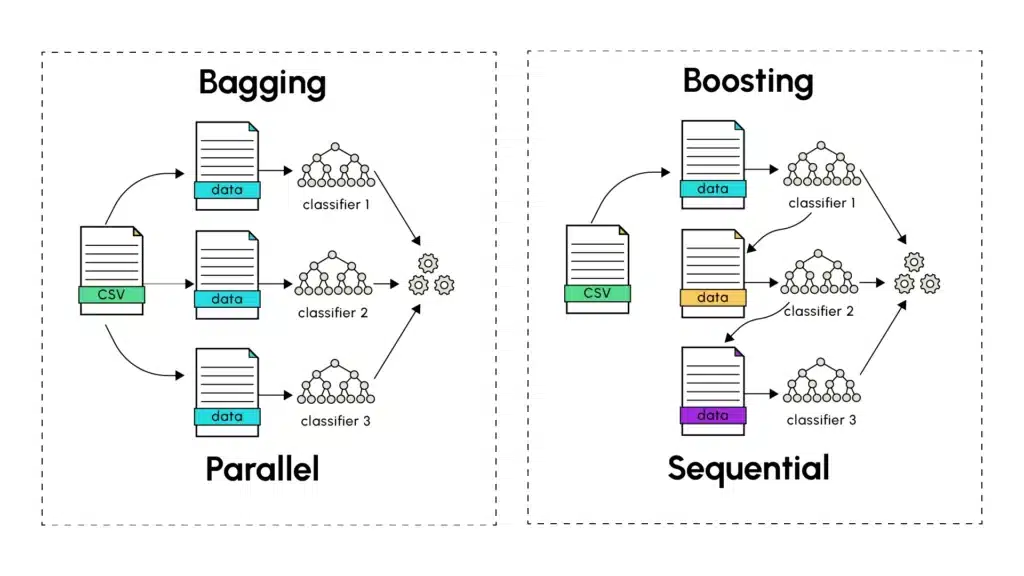
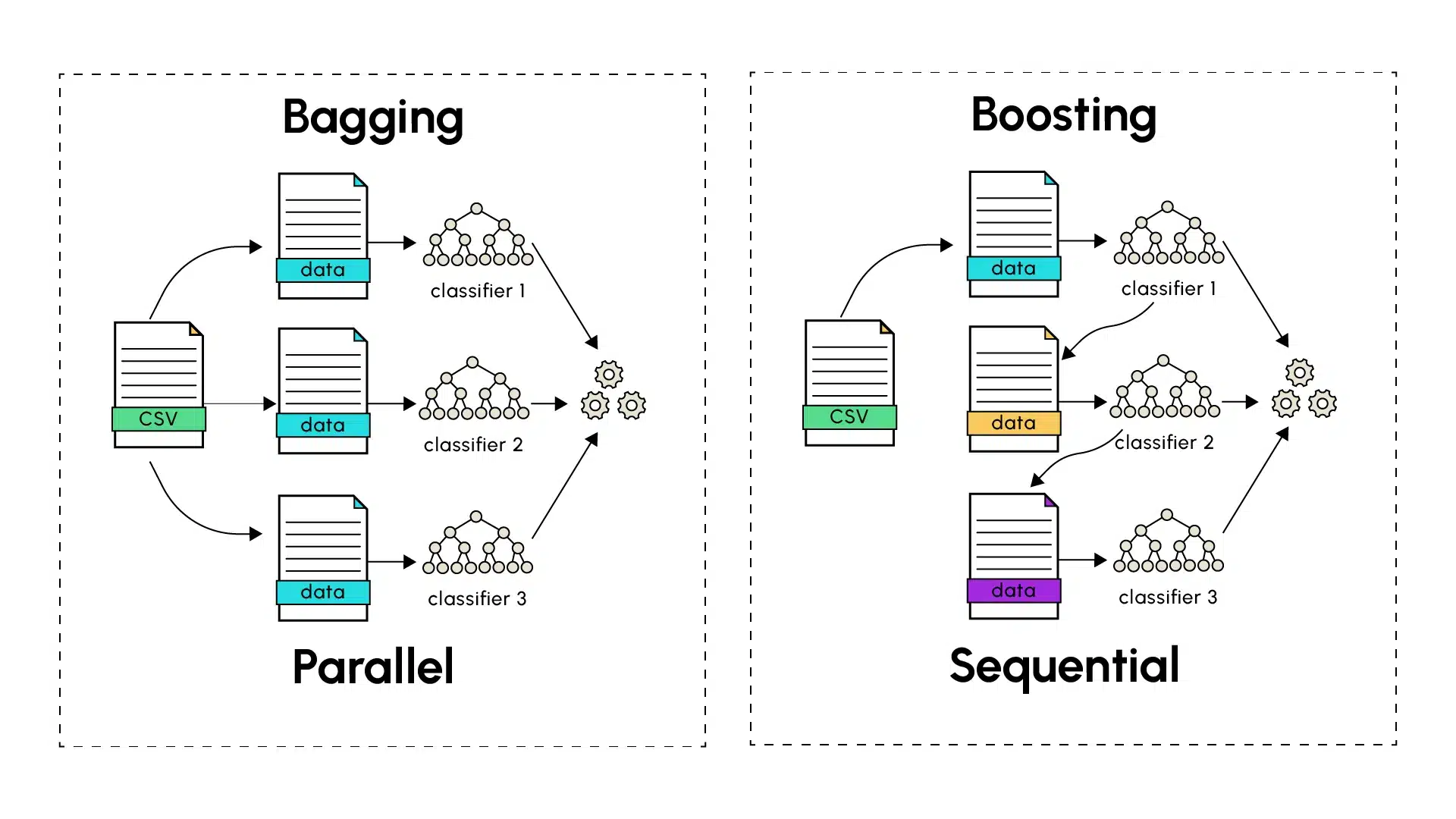
When the performance of a single model falters in delivering accurate predictions, ensemble learning techniques often emerge as the preferred solution. The most renowned methods, Bagging (Bootstrap Aggregating) and Boosting, aim to enhance the accuracy of predictions in machine learning by amalgamating the outcomes from individual models to derive more robust and precise final predictions.
Bagging: The Power of Parallel Learning
Introduced by Leo Breiman in 1994, Bagging involves training multiple versions of a predictor, such as a decision tree, which are trained in parallel and independently. The first step in bagging is to perform a random sampling with replacement (known as bootstrapping) from the training dataset. Each predictor is assigned a training sample to make predictions, which are then combined with those from other distinct predictors. The final step involves calculating the average of predictions made by different models (for quantitative predictions) or using a voting method (for categorical predictions), where the majority prediction based on the number of occurrences or probability is retained.
The main strength of bagging lies in its ability to reduce variance without increasing bias. By training models on different subsets that share a certain percentage of data, each model captures the diversity within the random datasets, leading to final results generalizing well on the test dataset. A real-world analogy is consulting several experts on a complex issue. Each expert, although competent, might have slightly different experiences and viewpoints. Averaging their opinions often results in better decisions than relying on a single expert.
In summary, aggregating several high-variance models effectively captures the variations in each training set. This approach helps smooth out the individual prediction errors from different models to build a global model with low variance by combining the predictions of several models with high variances (overfitting). Bagging has gained popularity through Random Forests, derived from parallel training of decision trees, known for their high variance.
Boosting: Sequential Learning for Error Reduction
Unlike Bagging, Boosting employs a sequential method in constructing the final model. Individual predictors are considered weak (underfitting) and are constructed in series, one following another. Each model attempts to rectify the errors of its predecessor, thereby reducing the bias introduced by each weak model. Boosting algorithms include notable examples like AdaBoost (Adaptive Boosting), Gradient Boosting, and its variants XGBoost and LightGBM.

The process starts with a weak learner making predictions on the training dataset. The incorrectly predicted instances are identified by the Boosting algorithm, which assigns them higher weights. The next model concentrates more on these previously hard-to-classify cases during its training to enhance its predictions. This process continues, with each subsequent model addressing errors from previous weak learners, until the series’ final model is trained. As with Bagging, the number of models to be trained for the final predictions can be determined empirically, considering complexity, training time, and accuracy of final predictions.
Gradient Boosting extends the concept of Boosting by employing a gradient-based approach to refine predictions. Each new model is trained to correct the residuals of previous predictions by following the loss function gradient’s direction, facilitating more precise and efficient optimization.
Key Differences and Trade-offs
1. Training Approach:
- Bagging: Models are trained independently and in parallel.
- Boosting: Models are trained sequentially, learning from the errors of the preceding ones.
2. Error Management:
- Bagging: Reduces variance through averaging.
- Boosting: Reduces both bias and variance via sequential learning.

3. Risk of Overfitting:
- Bagging: Generally more robust against overfitting.
- Boosting: More prone to overfitting, especially when classifying noisy data.
4. Training Speed:
- Bagging: Faster due to the parallel training of models.
- Boosting: Slower, owing to its sequential nature.
Practical Applications
Both techniques excel in different contexts. Bagging often performs well when:
- Base models are complex (high variance).
- The dataset is noisy.
- Parallel processing power is available.
- Interpretability is a focus.
Boosting typically excels when:
- Base models are simple (high bias).
- The data is relatively free of noise.
- Maximizing prediction accuracy is essential.
- Computational resources can support sequential processing.

Implementation Considerations
When implementing these techniques, several factors should be considered:
- Size of the Dataset: Large datasets tend to benefit more from bagging.
- Computational Resources: Bagging can take advantage of parallel processing.
- Parameter Tuning: Boosting usually requires more careful tuning.
- Interpretability: Bagged models tend to be more interpretable.
Conclusion
Bagging and Boosting have become fundamental techniques in machine learning. While Bagging offers robustness and simplicity through parallel learning, Boosting provides powerful sequential improvements. Knowing their respective strengths and weaknesses helps practitioners choose the most suitable approach for their specific applications.








