For the effective processing of sequential data in Deep Learning and Machine Learning, understanding Gated Recurrent Units (GRUs) is crucial. These neural networks are capable of retaining critical information over time.
Data with a temporal nature is everywhere: text, music, stock prices, sensor data… The meaning of each piece of data is influenced by preceding elements: a word gains its full meaning from the words that precede it in a sentence; predicting tomorrow’s temperature depends on today’s temperatures and those from previous days; or identifying a pattern in an audio signal requires analyzing the sound sequence across a period…
Traditional neural networks are not suitable for handling sequences of this kind because they lack “memory”.
The initial solution for managing this type of data properly was Recurrent Neural Networks (RNNs). However, they find it challenging to retain distant information due to the vanishing gradient (as gradients diminish with each layer of the RNN, they become so minuscule that they can no longer effectively update the weights of layers that are too far apart, thus losing information from the start of a sequence by the time it reaches its end).
To address this critical limitation and enable Deep Learning networks to process long sequences efficiently, more advanced RNN architectures have been developed.
Among the most effective and popular ones are Gated Recurrent Units (GRUs).
GRUs are an improvement over simple RNNs, designed to better manage memory, and consequently, information transmission over extended periods.
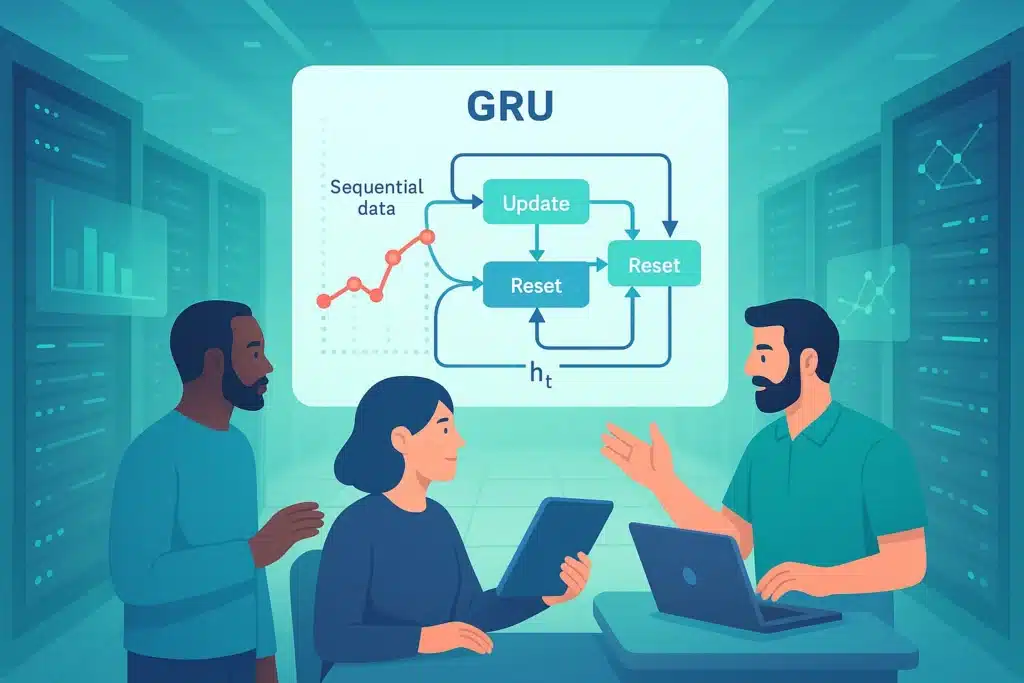
The Key Mechanism: Gating Mechanism
The primary innovation of GRUs, and RNNs from their family (such as LSTMs), is in the use of “gates” (gating mechanism). Rather than just blending the current input and the previous hidden state (h t-1) indiscriminately, as a simple RNN does, GRUs utilize these gates to selectively and dynamically regulate the flow of information through the recurrent unit.
These gates act as filters, based on activation functions (such as the sigmoid function), to determine which information from the past memory and the new input is most significant.
A GRU uses two essential gates:
- Reset Gate: This gate decides which part of the previous hidden state is ignored or “forgotten” when calculating a potential candidate state for the new hidden state.
- Update Gate: Determines how much of the previous hidden state should be retained and how much of the new candidate state (which represents the new potential information to integrate) should be added to form the new hidden state.
These mechanisms enable the GRU to preserve or discard information over long durations.
GRU vs LSTM
Long Short Term Memory (LSTMs) are very similar to GRUs, as they also employ “gates” to manage long-term memory and alleviate the vanishing gradient problem.
The difference with GRUs is that LSTMs use three gates, whereas GRUs use only two, thus making them more complex and slower to train.

The Advantages of GRUs
The primary advantage of GRUs over traditional RNNs lies in their ability to effectively capture dependencies between data in the same series, including more distant ones. In fact, thanks to the gates, the GRU can selectively retain relevant information over very long sequences and disregard information that is not.
For instance, in a lengthy sentence, a GRU can learn to keep the main subject and verb in memory, even if they are separated by numerous words, to ensure grammatical and semantic coherence by the end of the sentence. This ability makes them particularly effective at understanding context in long data sequences.
These gates allow gradients to pass more directly through time, preventing them from becoming too small (vanishing) as they are propagated back to the network’s initial layers. This stabilizes training and enables the network to effectively learn the weights that capture long-term dependencies.
LSTMs adhere to these principles as well. However, GRUs have a simpler architecture with fewer parameters (fewer gates) compared to LSTMs. This results in enhanced computational efficiency: they are generally faster to train and execute while delivering top performance on a wide array of sequential tasks, sometimes even surpassing LSTMs.
This is a significant advantage for real-time applications or when computing resources are constrained.

What Applications?
The benefits of GRUs pave the way for various concrete applications across different fields:
- Natural Language Processing (NLP): GRUs are widely used for tasks such as machine translation, text generation, sentiment analysis, speech recognition, and other tasks where understanding the sequential context is crucial.
- Time Series: They are also effective for predicting future values based on historical data (financial forecasts, weather predictions, energy consumption forecasts, etc.).
- Diverse Sequence Modeling: Lastly, they are regularly used for generating music, genomes, and any other data that presents itself in an ordered sequence.
Conclusion
In summary, Gated Recurrent Units (GRUs) represent a significant advancement over simple Recurrent Neural Networks (RNNs).
Thanks to their intelligent gating mechanisms, they effectively manage long-term memory and overcome the training challenges of simple RNNs, such as the vanishing gradient.
Their efficiency, robustness, and impressive performance make them a popular choice in Deep Learning and Machine Learning for a variety of applications.









