
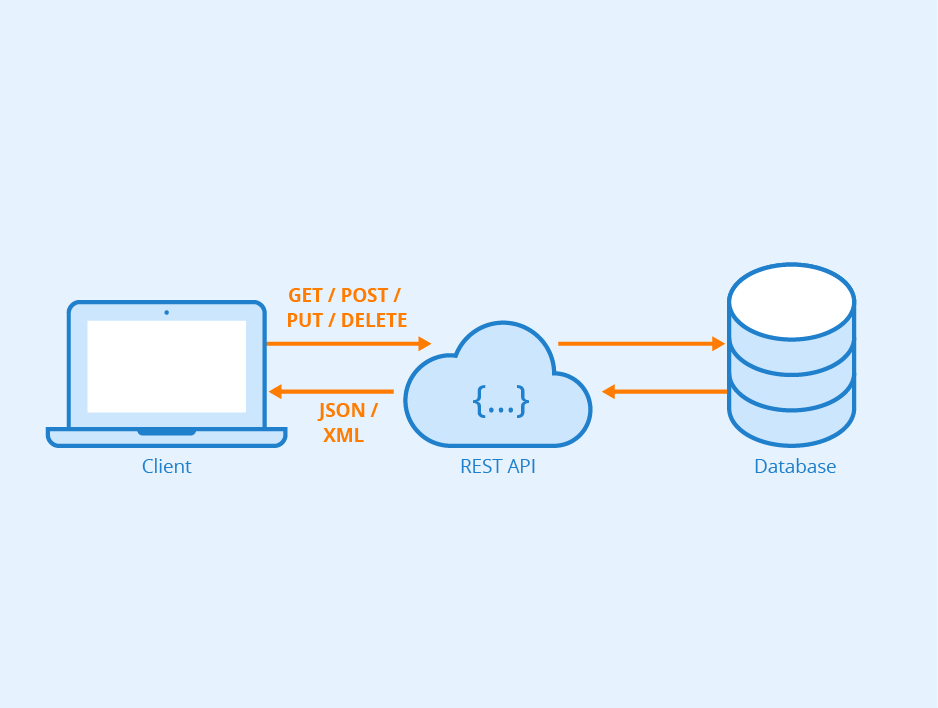
Today, web and mobile applications are ubiquitous in our daily lives. Companies are constantly looking for ways to improve the user experience and performance of their applications. This is where REST APIs (API for Application Programming Interface and REST for REpresentational State Transfer) come in.
REST APIs are programming interfaces that enable communication between different applications, systems and web services. They have become an essential part of modern application development, and are used in many fields.
Whether you’re ordering a meal online, exploring the content of your favorite streaming platform or sharing a photo on a social network, you’re interacting with a REST API.
In this article, we’ll take a closer look at what REST APIs are and how they work.
API Rest operating principles
Roy Fielding first defined the principles of REST architecture in 2000. It is based on the following pillars:
| Principle | Description |
|---|---|
| Client-Server | Client-server architecture, where the client sends a request to the server and waits for its response. The server processes the request and sends the response back to the client. |
| Statelessness | APIs do not store the session state on the server side. Thus, each request is treated independently. |
| Caching | Responses can be cached, eliminating some client-server interactions, improving system scalability and performance. |
| Secure Transport Layer | The secure HTTPS protocol can be used to ensure the security of data transferred between the client and the server. |
| Code on Demand | Servers can temporarily extend or modify a client's functionality by transferring executable code to it. |
| Uniform Interface | To achieve application uniformity, the following interface constraints are used:
|
What is CRUD?
The CRUD principle is a method for describing the basic operations that can be performed on data from a database or API.

CRUD stands for Create, Read, Update & Delete. Let’s take a look at what each of these terms means:
- Create consists in adding new data to the data source. For example, for a contact management application, create will add a new contact with its information (name, email, telephone, etc.).
- Read, to retrieve existing data from the data source. Again in our contact management application, reading will enable the user to consult the details of saved contacts.
- Update, to modify existing data. Using the same example, the user can modify the telephone number of an existing contact.
- Delete, to delete existing data. For example, you can delete a contact from your contact list
Anatomy of a query
A query is composed of the following elements:
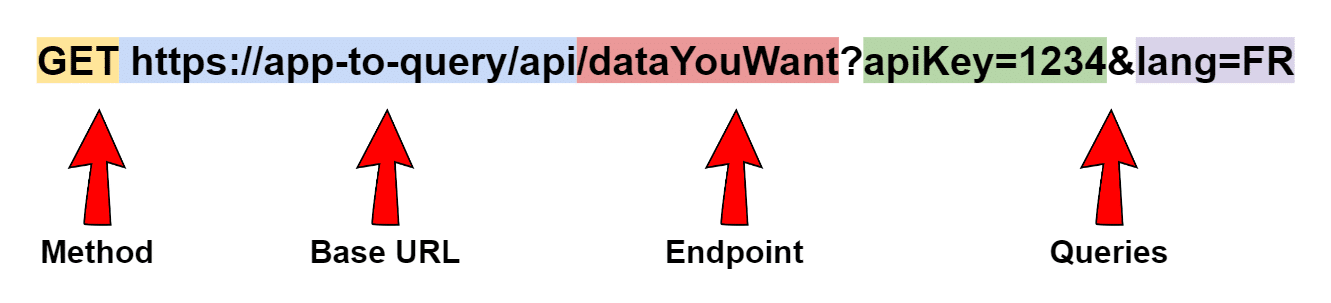
The method can be defined as a verb that stipulates what you expect from your request, in line with the CRUD principles. The most common methods are :
- GET: The server responds to your request by displaying the desired data. This is the Read operation
- POST: The server creates a new entry in the database, and notifies you of the result. This method executes a Create operation
- PUT / PATCH: These two methods update an entry in the database and notify you of the result. They perform an Update operation
- DELETE: Deletes an entry from the database, and notifies you of the result. This method performs a Delete operation
There are others, but they are much less frequently used: HEAD, CONNECT, OPTIONS and TRACE.
The base URL, or request address, is the address you wish to use to access the API.
The endpoint is the location of the data you wish to interact with
Queries are a set of indications designating what you wish to obtain, in key-value form, linked by &, and preceded by ?
We’ve just seen what makes up a query. Two important elements remain:
The headers, which are used to give additional information to the client and server. There are many header parameters, the full list of which is available on the Mozilla website.
They are always in key-value form.
The body of the request is the result returned to you from the server. This result also includes a return code informing you of the success or failure of the request. Codes 2XX indicate success, codes 4XX and 5XX indicate an error (e.g. 400 for an incorrect request, 404 for a resource not found, 501 for an authentication error, etc.).
Finally, codes 3XX indicate a URL redirect.
Anatomy of a query
A query is composed of the following elements:
The method can be defined as a verb that stipulates what you expect from your request, in line with the CRUD principles seen above. The most common methods are:
- GET: The server responds to your request by displaying the desired data. This is the Read operation
- POST: The server creates a new entry in the database, and notifies you of the result. This method executes a Create operation
- PUT / PATCH: These two methods update an entry in the database and notify you of the result. They perform an Update operation
- DELETE: Deletes an entry from the database, and notifies you of the result. This method performs a Delete operation
There are others, but they are much less frequently used: HEAD, CONNECT, OPTIONS and TRACE.
The base URL, or request address, is the address you wish to use to access the API.
The endpoint is the location of the data you wish to interact with
Queries are a set of indications designating what you wish to obtain, in key-value form, linked by &, and preceded by ?
We’ve just seen what makes up a query. Two important elements remain:
The headers, which are used to give additional information to the client and server. There are many header parameters, the full list of which is available on the Mozilla website. They are always in key-value form.
The body of the request is the result returned to you from the server. This result also includes a return code informing you of the success or failure of the request. Codes 2XX indicate success, codes 4XX and 5XX indicate an error (e.g. 400 for an incorrect request, 404 for a resource not found, 501 for an authentication error, etc.). Finally, codes 3XX indicate a URL redirect.
Authentification
A REST web service must be able to authenticate requests before it can send a response. This authentication verifies the identity of the person making the request.
The most common authentication methods are as follows:
- HTTP basic authentication: The client sends the username and password in the request header, which are then re-encoded in base64 for transmission.
- API keys: The server assigns you a unique key, usually a string of alphanumeric characters.
- OAuth: This is the most advanced level of security. The server first requests a password, then an additional token to complete the authentication process.
- The token can also be checked at regular intervals and have a certain lifetime.
Conclusion
This article has given you an insight into REST APIs, their power and scope. REST APIs are ubiquitous when it comes to web services and applications. We haven’t gone into the details of REST API development here, but the various DataScientest courses will give you an insight into this aspect.








