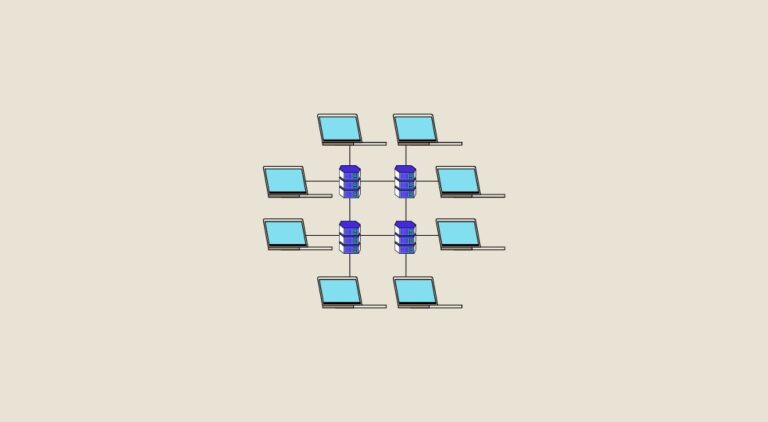
Multidimensional analysis is the ability to analyze data that has been aggregated along several dimensions. In this article, you’ll discover star and snowflake patterns, the most popular multidimensional data models. You’ll find a table comparing these two models at the end of the article.
What is an OLAP cube?
OLAP hypercubes, for Online Analytical Processing, are used to represent n-dimensional data. The data is structured along several multi-dimensional analysis axes, such as time, location, etc.
A cell is the intersection of different dimensions. Each cell is calculated on loading. This ensures a stable response time, whatever the query.
The cubes are designed to be used by all company employees, and are capable of reporting millions of records at once.
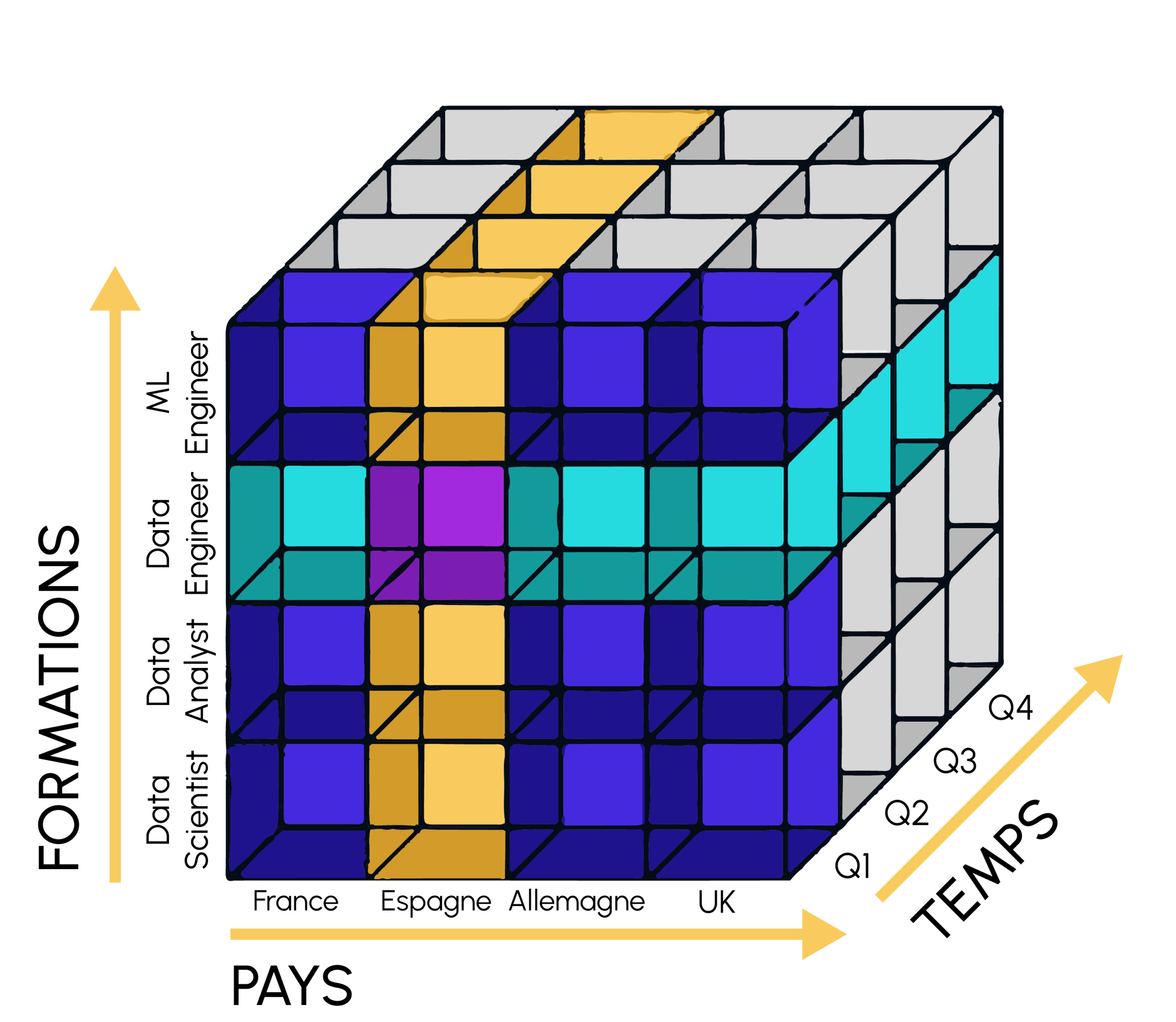
Star and snowflake schemas are the most popular multidimensional data models. While there are crucial differences between these two technologies, they both use fact tables and dimension tables to create and build a schema.
These database models are commonly used to meet the analysis needs of enterprise data warehouses.
First, let’s take a look at the difference between these two tables, then move on to data models.
Table of facts and table of dimensions
The fact table and the dimension table are used to create data schemas. A fact table record is a combination of attributes from different dimension tables. The fact table enables the user to analyze the various component functions of the company: sales, HR, support…
This will help to make decisions to improve the various activities that revolve around the company.
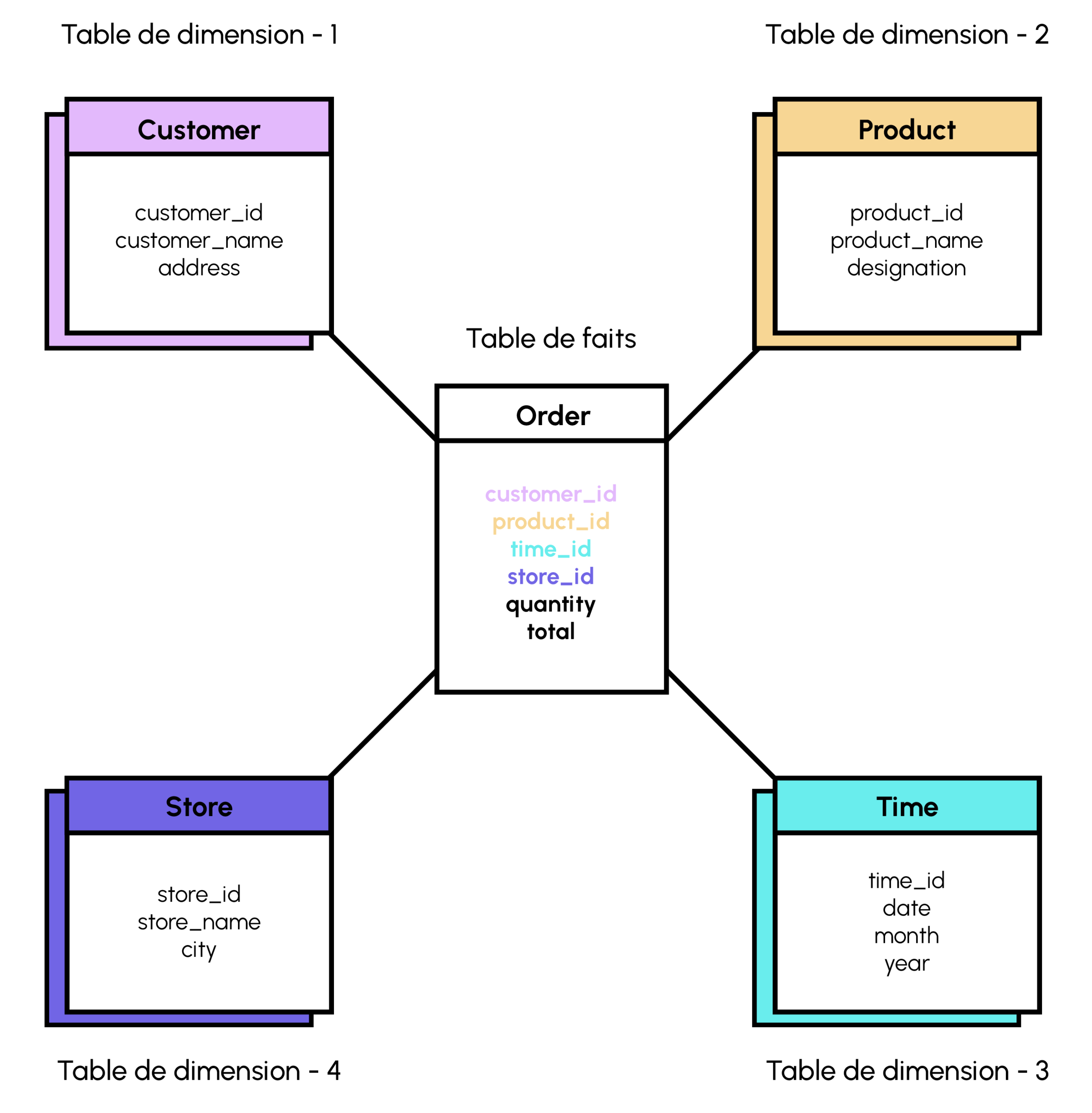
Here are a few things to bear in mind:
- The fact table contains measurements on the attributes of a dimension table.
- The fact table contains more records and fewer attributes than the dimension table.
- The fact table increases in size vertically, while the dimension table increases horizontally.
- Each dimension table contains a primary key to identify each record in the table, while the fact table contains a concatenated key which is a combination of all the primary keys of all the dimension tables.
- The dimension table must be registered before the fact table is created.
- A schema contains fewer fact tables but more dimension tables.
- Fact table attributes are both numeric and textual, while dimension tables have only textual attributes.
Definition of the star schematic
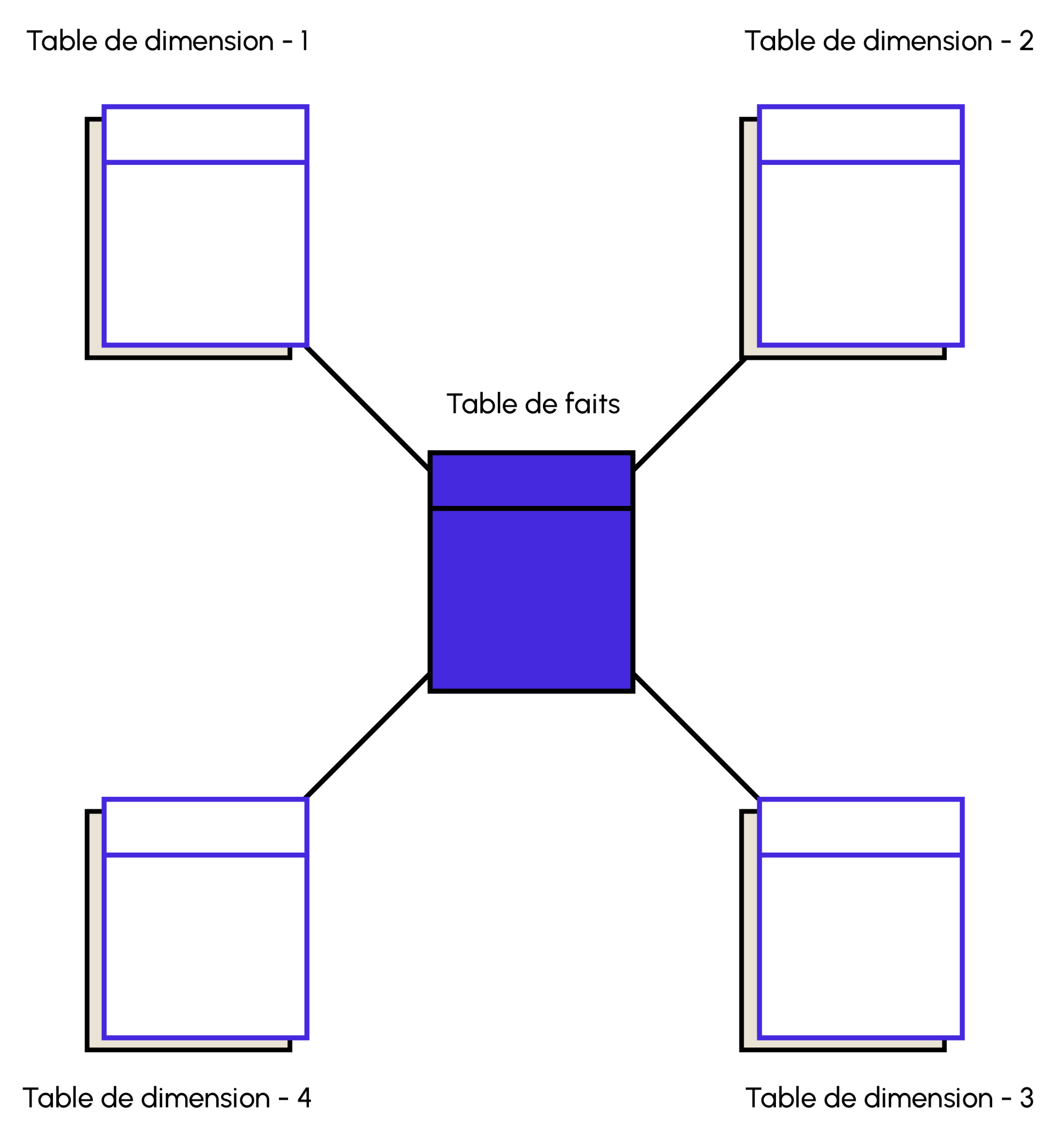
The star schema is the most common and widely used architectural model for developing data warehouses in which data is organized into facts and dimensions.
The schema mimics a star, with a dimension table presented in a spread-out pattern surrounding the central fact table. The dimension table is connected to the fact tables via primary and foreign keys.
Simplicity is one of the appealing aspects of the star schema, and the main justifications for its use are its performance and ease of understanding.
Defining the snowflake pattern
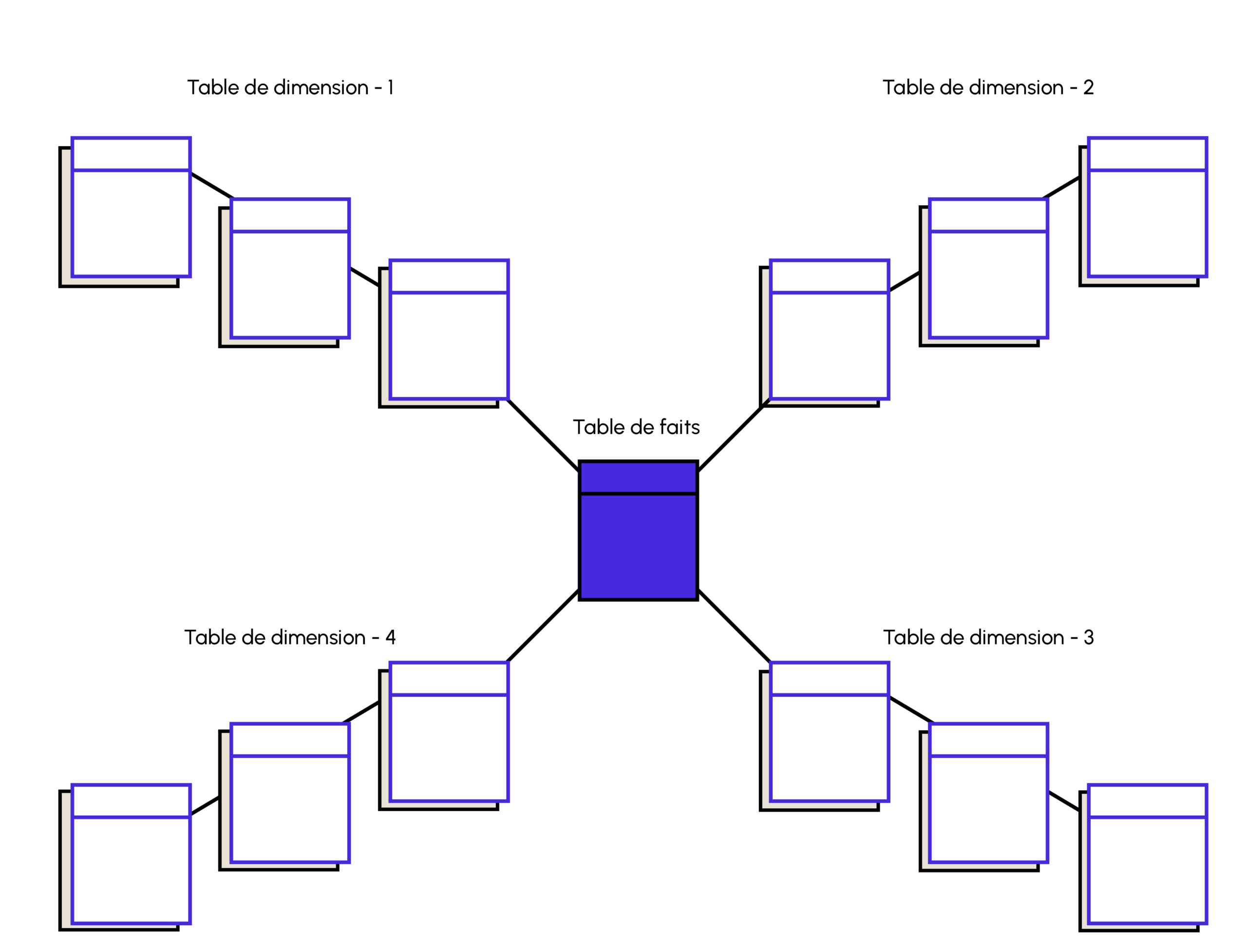
The snowflake schema is a type of star schema that includes the hierarchical form of dimensional tables. In this schema, there is a fact table made up of different dimension and sub-dimension tables linked by primary and foreign keys to the fact table.
It’s an extension of the star schema, with added functionality. Unlike the star schema, the dimension tables of the snowflake schema are normalized into several associated tables. The snowflake schema is designed to answer queries on a dimension with complex relationships between its levels.
This type of schema is suitable for dimensions whose levels are linked by n-to-n and 1-to-n relationships.
This type of schema uses normalization to partition data into tables. Partitioning reduces redundancy and avoids memory leaks. A snowflake schema is easier to maintain but more complex to design and understand than a star schema.
It can also reduce navigation efficiency, as more joins are required to execute a query.
Star or snowflake pattern: Which to choose?
Data integrity
The main difference between the two relational database models is normalization. Dimension tables in the star schema are not normalized, which means that the commercial model uses relatively more disk space to store dimension tables.
This generates more redundant records, which can be a source of inconsistencies. The flake schema, on the other hand, minimizes data redundancy since dimension tables are normalized.
Dimensions are preserved through referential integrity, meaning that relationships can be maintained independently between data stores.
Query performance
The star schema has fewer joins between the dimension table and the fact table than the snowflake schema, which means lower query complexity.
As the dimensions in a star schema are linked via a central fact table, the join paths are clear, which means fast query response times and therefore better performance.
The Snowflake schema has a higher number of joins, which lengthens query response times, making them more complex, thus compromising performance.
There you have it, I hope you now have a clear idea of the differences and advantages of each of the multidimensional data models.
I promised you a gift at the end of the article, and here it is: a summary table you can save to keep you up to date!
Comparative table of the two schemes
| Aspect | Star Schema | Snowflake Schema |
|---|---|---|
| Structure | Denormalized | Normalized |
| Dimension Tables | Fewer, typically 1 per dimension | More, separate tables for each dimension |
| Fact Table | Single, central fact table | May have multiple fact tables |
| Performance | Generally faster query performance | May have slower query performance |
| Storage | Requires more storage space | Requires less storage space |
| Data Integrity | Easier to maintain data integrity | May require more effort for data integrity |
| Complexity | Simpler to understand and implement | More complex to design and implement |
| Scalability | May become less scalable with growth | More scalable with proper indexing |
| Normalization | Not normalized | Fully or partially normalized |
- Are you interested in multidimensional data architectures?
- Would you like to learn how to manage large databases?
- Then take a look at our Data Engineer course!








