This article will be divided into two parts: The first focuses on the choice of metrics specific to this type of data, the second details the range of useful methods to obtain a successful model.
After detailing the different problems related to data imbalance and demonstrating that the choice of the right performance metric is essential for the evaluation of our models, we will present a non-exhaustive list of useful techniques to fight against this type of problem.
Collect more data
This may sound simplistic, but collecting more data is almost always overlooked and can sometimes be effective.
Can you collect more data? Take a few minutes to think about collecting more data for your problem, it could potentially rebalance your classes to some degree.
Use resampling methods
You can change the dataset you use before training your predictive model to have more balanced data.
This strategy is called resampling and there are two main methods you can use to equalize the classes:
Oversampling and Undersampling.
Oversampling methods work by increasing the number of observations of the minority class(es) in order to achieve a satisfactory ratio of minority class to majority class.
Undersampling methods work by decreasing the number of observations of the majority class(es) in order to reach a satisfactory ratio of minority class to majority class.
These approaches are very easy to implement and quick to execute. They are a great starting point.
Our advice: always try both approaches on all your unbalanced datasets, and check if it improves your chosen performance metrics.
Favor downsampling when you have large datasets: tens or hundreds of thousands of cases or more.
Consider oversampling when you don’t have a lot of data: tens of thousands or less.
Consider testing different class ratios. For example, you don’t have to aim for a 1:1 ratio in a binary classification problem, try other ratios.
Synthetic sample generation
There are algorithms to generate synthetic samples automatically. The most popular of these algorithms is SMOTE (for Synthetic Minority Over-sampling Technique). As the name suggests, SMOTE is an oversampling method. It works by creating synthetic samples from the minority class instead of creating simple copies.
To learn more about SMOTE, see the original article.
The ClusterCentroids algorithm is an Undersampling algorithm that uses Clustering methods to generate a number of centroids from the original data, in order to lose as little information as possible about the majority class, when it needs to be reduced.
Rethink the problem, find an other way to solvre the problem
Sometimes resampling methods are not efficient enough, and in this case, it is necessary to rethink the problem. It may be that the algorithm used is not suitable for your data.
Do not hesitate to test other algorithms, possibly combined with the resampling methods seen above.
Tree-based ensemble models such as RandomForest are generally more suitable for unbalanced data.
It is also possible to play with the probabilities. For example, if we want to be able to predict the vast majority of potential churners, even if it means misclassifying some non-churners, we can modify the probability threshold above which customers are considered as churners.
The lower the threshold, the higher the precision of our class, but the recall will decrease.
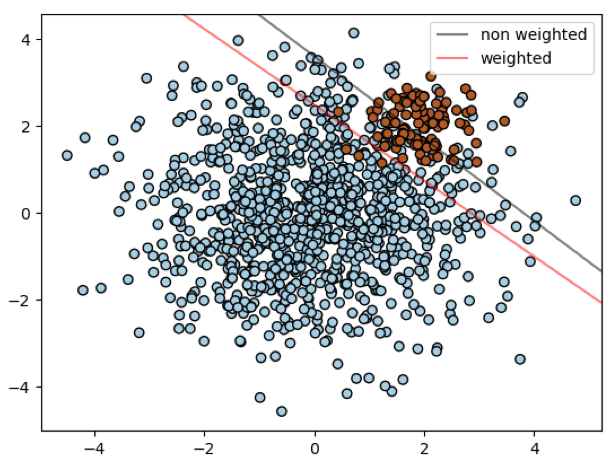
Use a penalized model
Penalized classification imposes an additional cost on the model for classification errors made on the minority class during training. These penalties can bias the model to pay more attention to the minority class.
In most classes of scikit-learn algorithms, it is possible to simply use the `class_weight` parameter. It allows penalizing errors made on a class by a new weight.
The higher the weight of a class, the more errors in this class are penalized, and the more importance is given to it.
The weights should be given in dictionary form, e.g. `{0:1, 1:5}`, to give 5 times the weight to errors made on class 1.
The argument `”balanced”` allows us to associate with each class a weight inversely proportional to its frequency.
Use methods generating subsampled subsets
Another solution proposed by the imblearn.ensemble module, is the use of classes containing ensemble models such as Boosting or Bagging which are trained at each step of the algorithm on a sample automatically rebalanced between the different classes.
These model implementations make it possible to dispense with resampling methods before training and to apply them automatically to each selection of data by the algorithm.
Think out of the box, be creative
You can test all of these techniques, combine them, or even think about relabeling the majority class data into subclasses to get a more balanced multi-class classification problem.
In some cases, you can also think about using other Machine Learning methods like Anomaly Detection or Active Learning.
We have presented many techniques, which you can choose from when working with this kind of data. Feel free to test these methods individually, and start with the simplest ones!
Want to improve your skills in building powerful and reliable models from unbalanced data sets?
Don’t hesitate to contact us for more information!








