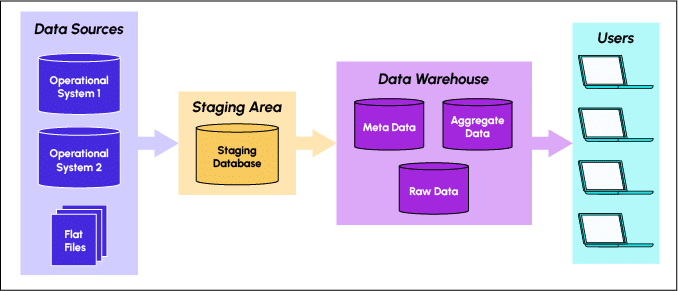
The 'Staging Area' is an important step in the ETL (Extract, Transform, Load) process, which involves extracting data from heterogeneous data sources, transforming it to prepare it for analysis and loading it into a destination system such as a data warehouse or database.
What is a Staging Area?
The Staging Area is a temporary storage area for data that has been extracted from various raw data sources (of different structures and formats). In this area, the data is often cleaned, standardised, enriched and structured to facilitate further processing.
In effect, the Staging Area acts as a buffer zone for data processing:
- Temporarily store data extracted from different data sources before transforming it and loading it into the destination system;
- Clean and normalise the data to eliminate duplicates, inconsistencies, missing or erroneous values, etc;
- Apply validation and quality rules to ensure that the data is complete, accurate and consistent;
- Apply transformations to change the format, structure and values of data to adapt them to the requirements of the destination system;
- Enable consistency and conformity checks on data before it is finally loaded into the destination system.
Why use a Staging Area?
There are several reasons why it is important to use a Staging Area in the ETL process rather than performing the transformations at the time of extraction and then loading the data directly into the target data warehouse:
- Flexibility: The Staging Area enables different data sources to be managed flexibly. It enables data from heterogeneous sources to be processed and specific transformations to be applied to adapt them to the requirements of the destination system.
- Performance: The Staging Area optimises the performance of the ETL process. It separates the processing of data from its loading into the destination system, minimising the impact on the performance of the target data warehouse.
- Monitoring and auditability: The Staging Area enables the ETL process to be monitored and audited. It captures errors, exceptions and statistics to facilitate monitoring and continuous improvement of the process.
What tools should I use to set up a Staging Area?
There are several tools you can use to set up an effective “Staging Area” in your ETL process. Here are a few examples:
- Relational databases: Relational databases such as MySQL, PostgreSQL or SQL Server can be used to temporarily store data extracted from different data sources. They offer powerful features for manipulating, cleansing and transforming data before it is loaded into the destination system.
- ETL tools: ETL tools such as Talend, Pentaho or Informatica can also be used to set up a staging area. These tools enable data flows to be managed, transformed and loaded into different data sources. They offer advanced functions for error management, data validation and task scheduling.
- File storage systems: File storage systems such as Hadoop HDFS, Amazon S3 or Azure Blob Storage can be used to temporarily store files containing data extracted from different data sources. These storage systems offer high storage capacity, high availability and data redundancy to guarantee data security.
- Workflow management tools: Workflow management tools such as Apache Airflow, Azkaban or Luigi can be used to automate the ETL process and schedule tasks efficiently. They offer advanced features for planning, monitoring and managing tasks centrally.
In short, the Staging Area is a temporary work area where data is prepared for loading into a destination system, going through cleansing, normalisation and transformation operations.








