
Google Colab is an online Jupyter notebook service that enables you to write and execute Python code directly from your web browser. Accessible for free with a Google account, Colab is perfect for data analysis and data science with Python, thanks to its code cells and text blocks in Markdown syntax, allowing you to structure and annotate your code effectively.
A notebook created on Colab is saved on Google Drive. Essentially, it’s a .ipynb file that can be downloaded and opened on your local machine using Jupyter Notebook. Conversely, a .ipynb file created locally with Jupyter Notebook can be uploaded to Google Drive for editing and execution in Colab, granting access to computational resources like GPUs [1] and TPUs [2]. For remote team collaboration, a Colab notebook can be shared in the same way a Google Docs document can be. Additionally, this notebook can access files saved in Google Drive, which is particularly useful when working with datasets in .csv format.
But how do you share both the notebooks containing your code and the files containing the data? This is where things become a bit more complex. Fortunately, there are several ways to achieve this!
During their training at DataScientest, our students engage in a capstone project designed to apply the skills they have learned through a practical implementation case. This project is conducted in teams of 2, 3, or 4 members, often dispersed geographically. To efficiently initiate this remote collaborative work, our teaching team conducts a masterclass to lay the groundwork and explore various possible solutions. Each team then receives personalized guidance through regular meetings with their mentor.
In this article, we revisit the essential tips for getting started with Google Colab as a team. What tricks and tips do DataScientest mentors recommend? What cautionary points should you be aware of? In under 7 minutes, you’ll gain a clear understanding of the 3 recommended scenarios to set everything up.
First, create and share your notebook
- From your working folder in Drive, click on “+ New” > More > Google Colaboratory (or “Connect more apps” if it doesn’t appear in the list) then “Create”.
- Alternatively, from the page https://colab.google, click on “New Notebook” (the file is stored by default in your Drive in a subfolder “Colab Notebooks”).
- Rename the file, which is titled
Untitled0.ipynbby default. - Click on the button

and provide your teammates with editor access.
⚠️ Warning: The notebook can be executed by only one person at a time.
Scenario 1 with BytesIO and 1 file
Lucas advises using this method at the start of a project. It allows the same source file to be used by the entire team, stored in any account, and needs only to be made public. Thus, every team member can run the notebook without altering the code cell that loads the dataset.
import pandas as pd
from io import BytesIO
import requests
# Ceci est uniquement utilisé pour vous montrer où obtenir le file_id
original_link = "https://drive.google.com/file/d/1fRkXUdfLzTMkscHsAI8_NJuuDptwk02W/view?usp=drive_link"
# ID du fichier (à partir du lien partagé) (LE FICHIER DOIT ÊTRE PUBLIC)
file_id = "1fRkXUdfLzTMkscHsAI8_NJuuDptwk02W"
# Télécharger un fichier CSV depuis Google Drive
download_url = f"https://drive.google.com/uc?id={file_id}"
response = requests.get(download_url)
data = BytesIO(response.content)
# Charger le fichier CSV dans un DataFrame
df = pd.read_csv(data)
df.head()
🔗 To learn more: Check out the documentation at https://docs.python.org/3/library/io.html.
Scenario 2 with gdown (Google Drive Public File Downloader) and 1 or multiple files
Alia often recommends this method to her students. The gdown library is specifically designed to import files from Google Drive. Again, with this approach, the source file stored on Drive must be public. Tip: the parameter “quiet = True” suppresses the progress output during the download, making it less verbose.
# import de packages
import subprocess
import sys
import pandas as pd
# Ce code permet de s'assurer que gdown est bien installé.
# Si ce n'est pas le cas, il l'installe automatiquement.
# Cela évite des erreurs au moment de l'utiliser, surtout sur Colab où certaines bibliothèques ne sont pas déjà présentes.
try:
import gdown
except ImportError:
# Si gdown n'est pas installé, l'importer en utilisant pip
subprocess.check_call([sys.executable, "-m", "pip", "install", "gdown"])
# Remplacez l'ID par le vôtre (tout ce qui se trouve entre /d/ et /view)
# Par exemple avec https://drive.google.com/file/d/1ptwmJbk8ToMt4BvQeG5ni37IeNAOoAsb/view?usp=drive_link
file_id = '1ptwmJbk8ToMt4BvQeG5ni37IeNAOoAsb' # Remplacer par un fichier plus léger!
url= f'https://drive.google.com/uc?id={file_id}'
# Téléchargement du fichier csv
gdown.download(url, 'your_file_name.csv', quiet=True)
# Chargement du fichier csv dans un dataframe
df = pd.read_csv('your_file_name.csv')
df.head()
🗃️ Do you have multiple files to import? gdown also allows you to import a Drive folder and its contents in bulk before opening the dataset(s) you need.
import gdown
url = "https://drive.google.com/drive/folders/1HWFHKCprFzR7H7TYhrE-W7v4bz2Vc7Ia"
gdown.download_folder(url, quiet=True, use_cookies=False)
The output then lists the paths of each file in the folder:
Output
['https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/special_general.csv',
'https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/remain_person.csv',
'https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/general.csv',
'https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/eunuch.csv',
'https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/civil_servant.csv']
Then we open the desired file with Pandas:
# Nous ouvrons le premier fichier avec pandas et vérifions les premières lignes
import pandas as pd
df = pd.read_csv('https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/special_general.csv')
df.head()
🔗 To learn more: The documentation is available at https://pypi.org/project/gdown, and our script follows the demo proposed by Google Colab on the page https://colab.research.google.com/github/intodeeplearning/blog/blob/master/_notebooks/2022-05-08-how-to-download-files-in-gdrive-using-python.ipynb#scrollTo=I4vv49erlMC3
Scenario 3 with a Drive shortcut for private files
Do you need to keep your source files private? You can share a notebook with your team, allowing each member to run it in turns to analyze a dataset shared exclusively with other members. The following procedure aims to standardize the file path so every team member can execute the same import cell for the datasets at the beginning of the notebook.
Let’s see what this looks like for users A, B, and C.
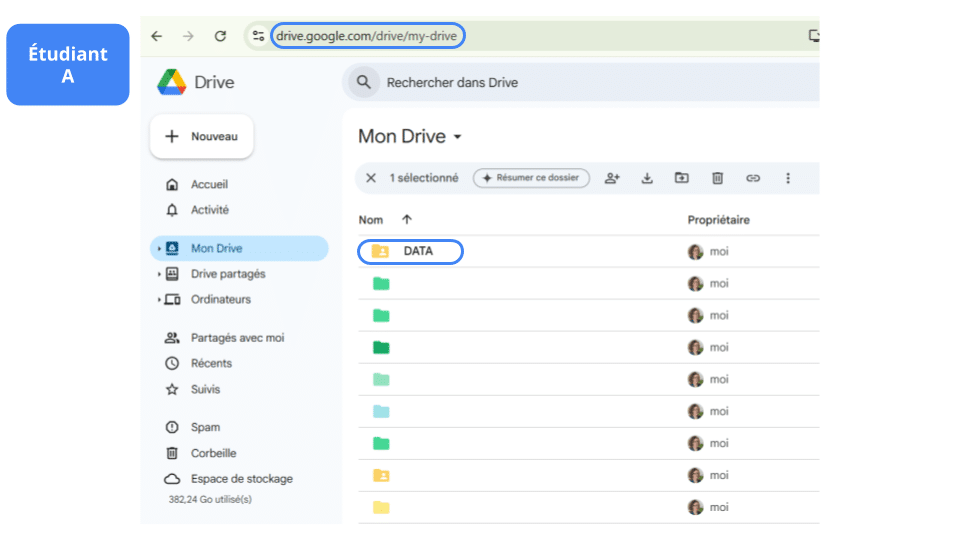
A places the dataset data.csv in a “Data” folder created at the root of their Drive, with the full path as follows:
python '/content/drive/My Drive/Data/dataset.csv'
A shares the “Data” folder with their teammates B and C.
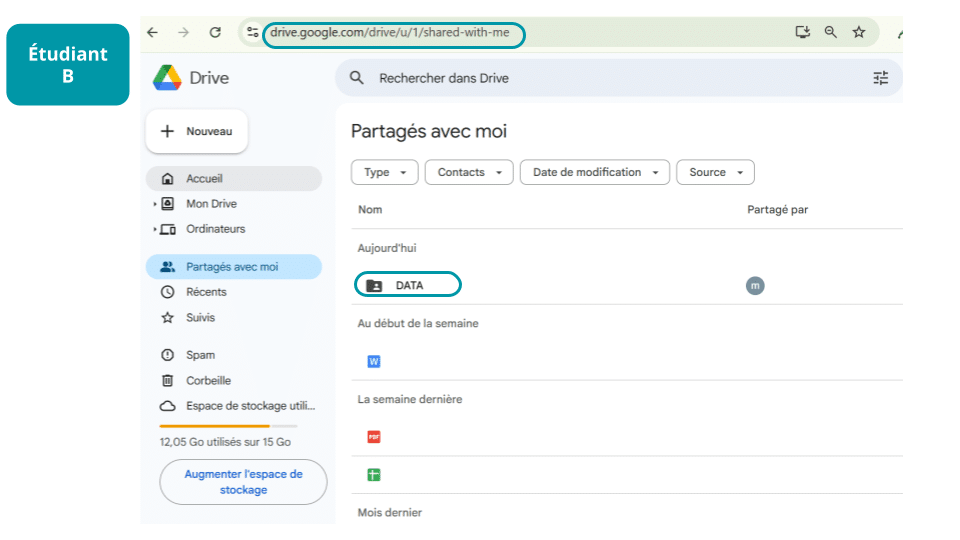
B and C, in turn, will find “Data” among their shared folders, create a shortcut to “Data” (by right-clicking), and place it at the root of their Drives (each in “My Drive”).
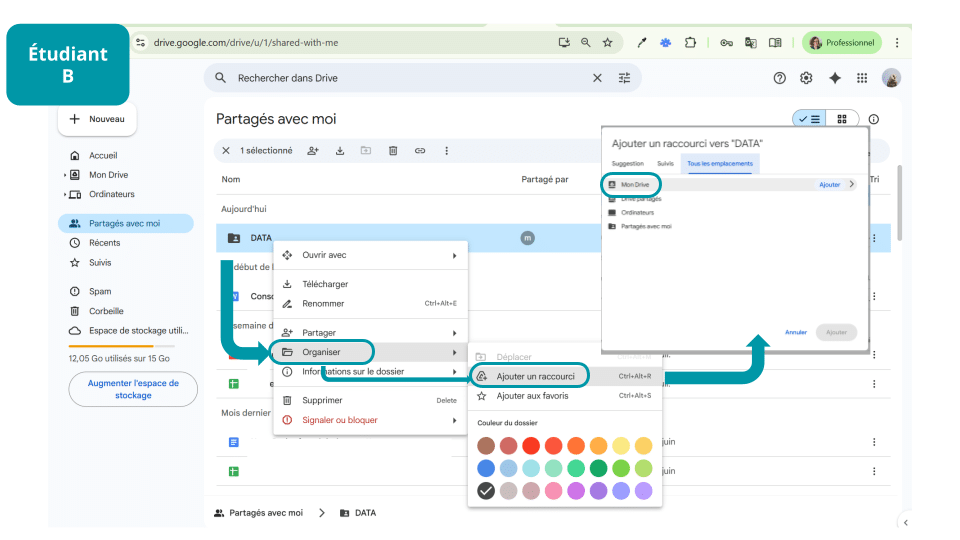
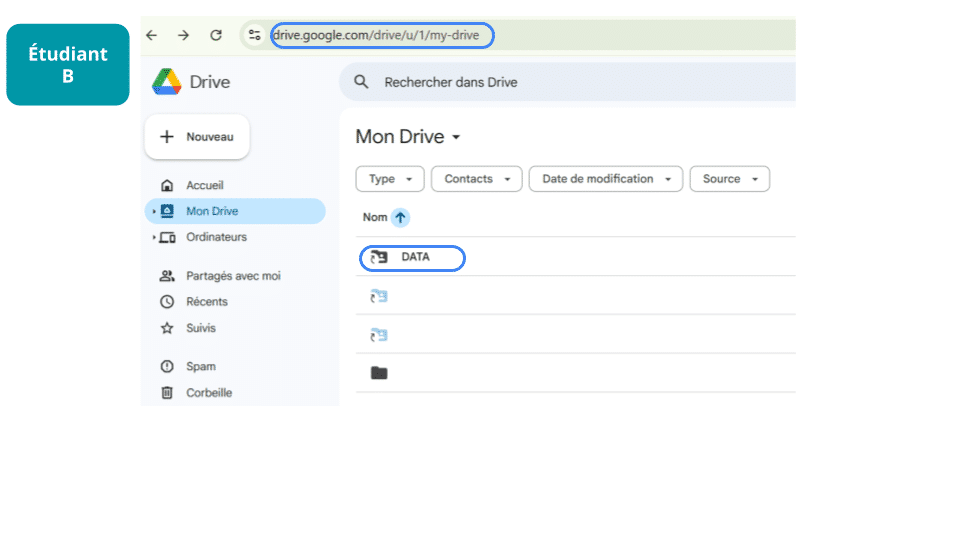
They can then use the same path as A:
python '/content/drive/My Drive/Data/dataset.csv'
The notebook will therefore include a code cell to connect Colab to Drive (each student taking turns must connect the notebook to their Drive):
from google.colab import drive
drive.mount('/content/drive')
Then the following cell, to be executed to activate the path to the file:
# File path for A, B, C
import pandas as pd
pathA='/content/drive/My Drive/Data/dataset.csv'
df = pd.read_csv(pathA)
In summary
- At the start of a capstone project, during the open data exploration phase (public data), BytesIO offers the simplest syntax.
- During the project, gdown provides a more effective solution for cleaning, combining, and transforming data from multiple files in the same folder.
- If datasets need to remain private, the solution is to organize the sharing of a single folder containing all datasets, with an identical shortcut for all other members, enabling a common access path in Colab.
To explore further
- Google Colab: https://colab.google/
- Introductory video to Google Colab (3 minutes): https://www.youtube.com/watch?v=inN8seMm7UI&ab_channel=TensorFlow
[1]: Graphic Processing Unit
[2]: Tensor Processing Unit








