| Aurora Global DB |
Deploys an Aurora database across multiple AWS regions |
- Very low latency
- Rapid data replication
- Quick and transparent recovery after failures
- High performance
|
- Global-scale applications
- Disaster recovery
|
| Amazon Aurora Serverless |
Automatically scales the database based on application traffic |
- Automatic scaling
- Low maintenance costs
|
- Variable traffic applications
- Developers
|
| Amazon RDS Proxy |
Creates a connection pool to improve application performance |
- Performance improvement
- Connection management
- High availability
|
- High-demand applications
- Production environments
|
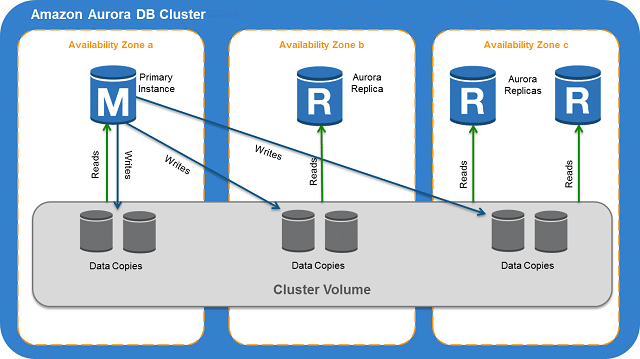
| Single-master clusters |
Used to handle read-intensive workloads or mixed read-write workloads |
- High availability
- Load balancing
- High performance
|
- Larger-scale applications
- Read-intensive workloads
|
| Multi-master cluster |
Used to enable horizontal load balancing for mixed read-write workloads |
- High availability
- Load balancing
- High performance
|
- High-demand applications
- Read-write intensive workloads
|
| Read replicas |
Replicates data from the primary database for read operations, improving performance |
- High availability
- Reduced downtime
- High performance
|
- Larger-scale applications
- Read-intensive workloads
|
| Babelfish for Aurora PostgreSQL |
Allows migration of PostgreSQL applications to Aurora PostgreSQL using existing tools and skills |
- Easy migration
- Compatibility with PostgreSQL
- Cost savings
|
- Existing applications
- PostgreSQL workloads
|