
Amazon SageMaker is a cloud platform developed by Amazon Web Services (AWS) that is particularly useful for data science. Below you can learn more about the main features and how to use the tools of the platform from the development of a machine learning model to its deployment.
Introduction to Amazon SageMaker
Amazon SageMaker is a Machine Learning based cloud platform that is a service of the Amazon Web Services (AWS) cloud platform. AWS has numerous services on the Internet and can be used to manage a cloud application.
SageMaker allows a user to create and deploy Machine Learning models in a production environment at scale. Thus, using this platform, a data scientist can access powerful tools to solve problems such as classification, regression, clustering, etc. Sagemaker enables companies to accelerate the development process of their models by reducing costs and improving operational efficiency through its numerous features.
The main functions of SageMaker
First of all, to use the SageMaker platform, the user has two options:
- Use a notebook instance through the Amazon SageMaker Notebooks Instances environment to run Jupyter notebooks. This environment includes common machine learning libraries and frameworks.
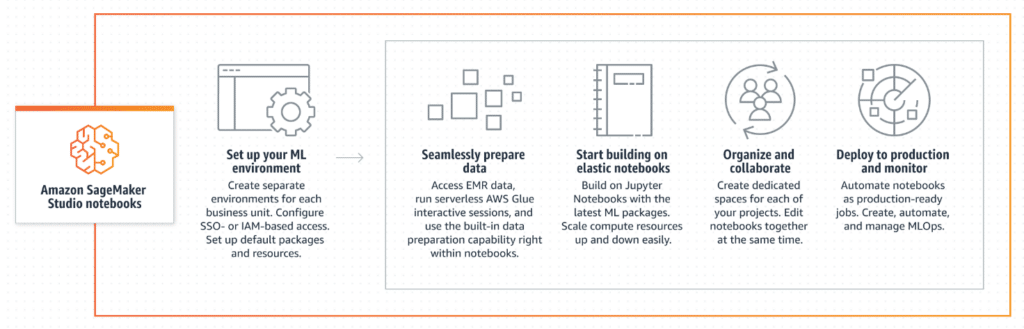
- SageMaker Studio is an integrated, cloud-based machine learning development environment that allows a user to manage the entire model development process through a user interface with numerous tools and advanced features.
- For example, Amazon SageMaker Studio consists of, among other things, integrated notebooks, but also tools for managing data and models (training, deployment, and monitoring).
- Amazon SageMaker Studio thus offers a more comprehensive experience for machine learning development than the SageMaker Notebook environment. The choice is therefore up to the user and should be tailored to the project they want to implement.
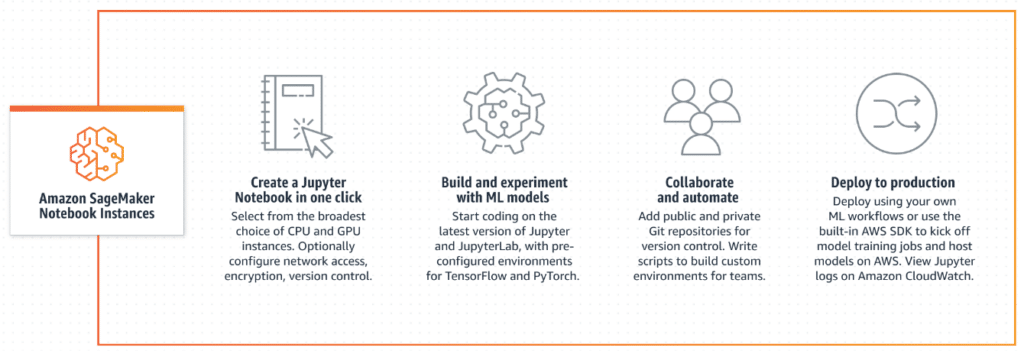
Once the project is created, a variety of different functions are available to the user with the Sagemaker tool to develop their machine learning project. These functions include, for example :
- The preparation of the data.
- The training of the models using machine learning algorithms preconstructed by AWS Sagemaker or by using common libraries such as Pytorch, TensorFlow and Scikit Learn.
- Deploying the models.
- Monitoring the models by examining the performance of a model in real time through performance analysis and anomaly detection.
- Resource management.
How do I create and deploy a machine learning model using Amazon SageMaker?
1. Preparation of the data
The first step is to prepare the data, which can be optimized using various tools from the platform:
- Sagemaker Clarify: This tool is able to detect biases in the training data to ensure that the model is accurate enough. It also suggests strategies to correct these biases.
- SageMaker Ground Truth: This feature is used to annotate datasets needed for training machine learning models. This reduces the cost of data labeling.
- SageMaker Data Wrangler: This feature cleans, normalizes, and transforms raw data into a dataset that can be used to train a model. The user is also provided with a graphical user interface to facilitate data preparation.
- Geospatial ML: This tool enables large-scale geospatial data analysis and processing.
- Feature Store: With the help of this service, the user can store, share and manage the features used in his models.
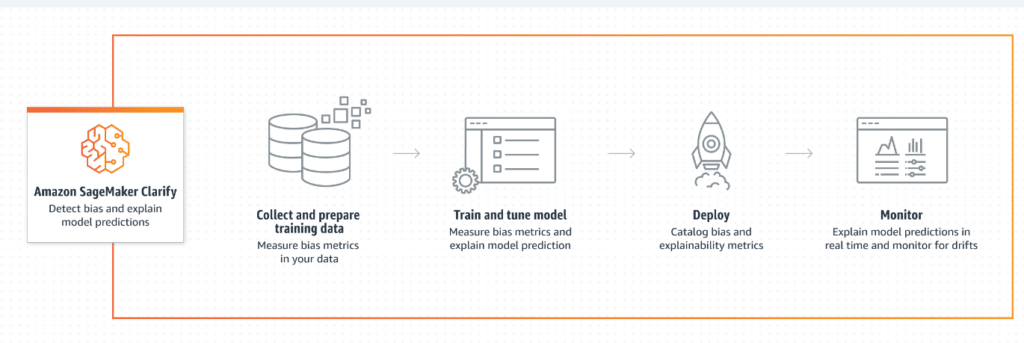
2. Train model
Regarding the training of a model, thanks to the platform, the user has several tools at his disposal, such as:
- SageMaker Autopilot: This tool enables automated machine learning development. It allows an inexperienced user to easily create a machine learning model. After you provide Amazon SageMaker Autopilot with all the data, the tool automatically creates and optimizes a model. With the help of this tool, the user can also figure out how the model makes decisions.
- SageMaker Debugger: With this feature, the user can debug models to get information about calculation errors and convergence problems. This is very useful to find out if the model fits the data well.
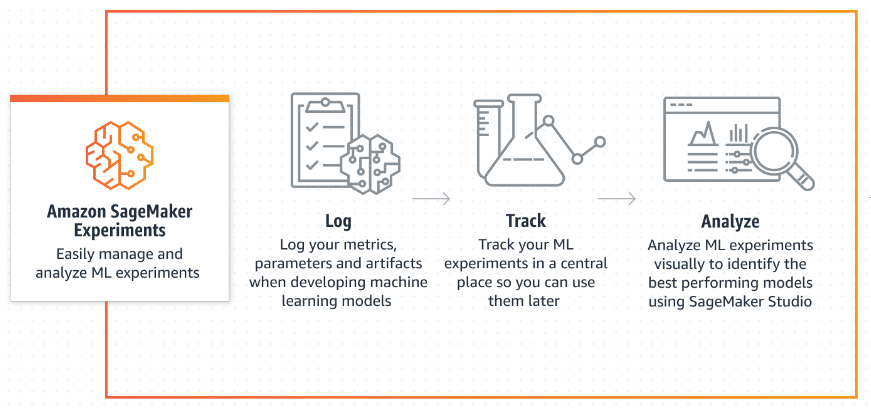
- SageMaker Experiments: this feature allows the developer to examine models, compare them and observe the logging of metrics.
- Automatic Model Tuning: This tool is able to automate the selection of optimal hyperparameters for a model through various search techniques.
- Distributed Training: this feature is useful for greatly reducing the time required to train models by parallelizing the training processes across multiple instances.
- SageMaker Canvas: this is a visual environment used to create, manage and visualize machine learning workflows. A workflow is a tool used to organize and manage the development steps of a model. It is also possible to share one’s workflows with other users to collaborate on projects.
3. Roll out the models
To roll out its model, the main feature that the user can use is Amazon SageMaker Edge. This feature can deploy machine learning models to edge devices and applications through a software development kit (SDK) that simplifies the integration of the deployed models.
Edge devices are hardware devices consisting of sensors, processors, and operating software, among others, that are used to collect, process, and store data in the field. Examples of edge devices include security cameras, connected watches, self-driving cars, and smart thermostats…). Edge applications, on the other hand, are software applications designed for use on edge devices. They can be used to process data, optimize performance, make decisions, and much more.
4. Maintenance of the rolled out model
After deployment, users can apply the following functions to their deployed models:
- SageMaker Model Monitor: this feature monitors the performance of machine learning models that have been deployed in production. The tool can detect prediction errors, performance degradation and irregularities in data distribution. The final benefit of this tool is that it sends alerts to the user so they can take corrective action.
- SageMaker Pipelines: this service is used to create and manage machine learning workflows. It provides the user with an environment to create, validate and deploy the workflows using Docker containers.
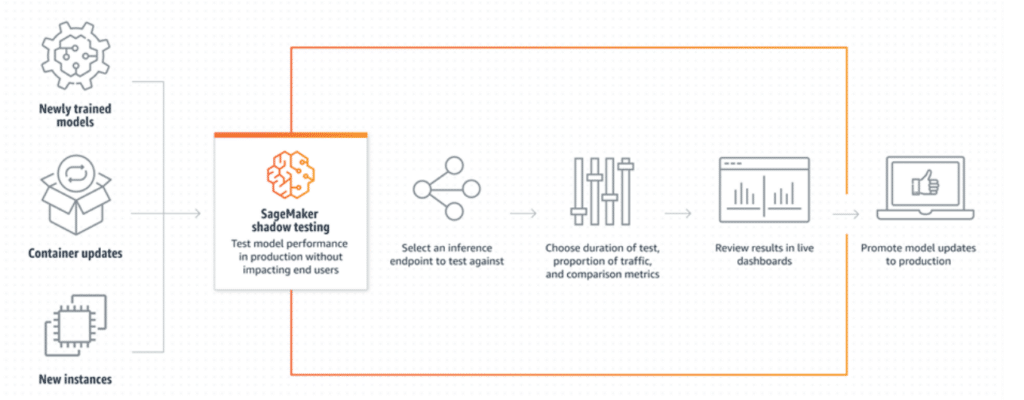
- SageMaker Test Shadow: This feature can simulate predictions of machine learning models in a production environment with specific test data to validate the behavior of the models.
Conclusion
Amazon SageMaker is a particularly useful and comprehensive platform for Data Scientists because it has a variety of tools that are high quality and interesting.
These tools can be used for all phases of developing a machine learning model, from preparing the data, to training and deploying the model, to maintaining the deployed model. So, the AWS SageMaker platform will be used more often by Data Scientists for Machine Learning because of its many centralized features.
If you want to further your education in Data Science to go deeper into the topics around Machine Learning, you should take a look at our courses in Machine Learning Engineering and Data Science, which can also enable you to get the AWS certification.








