
What is Apache Storm?
Apache Storm is an open-source distributed real-time data flow processing system, developed mainly in Clojure. It enables continuous data flow management. Today, Storm is widely used in social networking, online gaming and industrial monitoring systems.
Apache Storm was originally developed by Nathan Marz for the startup Backtype, which was subsequently acquired by Twitter.
Storm makes a point of keeping things as simple as possible, allowing developers to create topologies using any programming language. In fact, development in Storm involves the manipulation of tuples (as a reminder, a tuple is a named list of values).
These tuples can contain any type of object, and even if Apache Storm doesn’t know the type, it’s easy to set up a serializer.
How is Apache Storm structured?
Apache Storm uses a “master-slave” architecture with the following components:
- Nimbus: This is the master node, responsible for distributing code among supervisors, allocating input data sets to machines for processing and monitoring for failures.
- Zookeeper: Coordinates and manages data distribution processes.
- Supervisors: Services running on each worker node, which manage work processes and monitor their execution.
- Workers: Are the multiple or single processes on each node started by supervisors. They perform parallel data input management and send data to a database or file system.
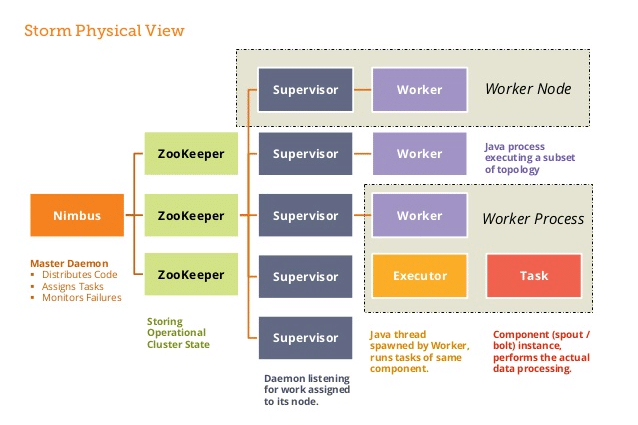
Tool layout
The topology in Storm uses a system of directed acyclic graphs (DAG). It works in a similar way to MapReduce jobs in Hadoop. The topology is made up of the following elements:
- Spouts: These are the entry point for data flows. They connect to the data source, retrieve the data continuously, transform the information into a stream of tuples and send these results to the bolts.
- Bolts: store the processing logic. They perform various functions (such as aggregation, join, filter, etc.). Output creates new streams for further processing via additional bolts, or stores data in a database or file system.

This diagram shows that Storm’s topology is a sequence of processes, with bolts and spouts distributed in such a way as to achieve very rapid results.
What is the Parallelism Model?
Apache Storm uses a parallelism model based on tasks and bolts. Data is processed by a set of parallel tasks that are linked together using bolts. Each task processes a subset of the input data, and bolts connect the tasks together to create data streams. This enables Storm to process data in a distributed way, boosting performance by using multiple machines to process data simultaneously.
DRPCs (Distributed Remote Procedure Calls) enable the parallelism of very intensive, high-consumption calculations.
They behave more or less like a spout, except that the data sources are the arguments of the function, which returns a response in the form of text or json for each of these streams.
They are useful for time-consuming calculations, to reduce response times.
Fault tolerance
When managing Big Data processing, information overload can lead to errors or breakdowns on certain clusters. So it’s vital that Storm can continue to operate despite a failure.
So when a worker fails, Storm automatically restarts it. If an entire node fails, Storm restarts tasks that were running on other workers.
Similarly, when the Nimbus or supervisors fail, they too are automatically restarted. It’s even possible to force a process to stop (e.g. with taskkill -9) without affecting clusters or topologies.
The different levels of cover
Storm offers several warranty levels for data stream processing:
- At most once: This is the default guarantee level. It guarantees that each tuple is processed at least once.
- At least once: This guarantees that each tuple will be processed at least once. It may result in some tuples being processed twice.
- Exactly once: This guarantee means that each tuple will be processed exactly once. This is the highest guarantee level, but also the most complicated to implement, and requires third-party libraries.
Trident
Trident is a high-level abstraction that provides an API for real-time data transformation and aggregation. It allows developers to focus on business logic rather than the implementation details of processing tasks. It offers state management, facilitating in-memory data management for long-term processing tasks, and supports distributed transactions to guarantee data reliability.
Apache Storm vs Spark
Although these two technologies have different uses, they are nevertheless both widely used in Big Data management. The following table shows how these two technologies compare.
| Storm | Spark | |
|---|---|---|
| Architecture | Micro-batch | Micro-batch/batch |
| Processing Type | Real-time Streaming | Real-time Streaming and Batch Processing |
| Latency | A few milliseconds | A few seconds |
| Scalability | Thousands of nodes | Tens of thousands of nodes |
| Supported Languages | No distinction | Java, Scala, Python, R |
| Usage | Real-time Data Stream Processing | Real-time Data Stream Processing and Batch Processing |
Conclusion
In conclusion, Apache Storm is a distributed data stream processing system that enables large quantities of real-time data to be processed efficiently and reliably. With its flexible, scalable platform, Apache Storm has proved to be a popular choice for companies looking to process real-time data and make decisions accordingly.








