
The acronym HDFS stands for Hadoop Distributed File System. As its name suggests, HDFS is closely linked to the Hadoop tool. What is HDFS used for? What is the link between HDFS and Hadoop? How does HDFS work? We'll answer all these questions in this article.
What is Hadoop?
Hadoop is an open-source tool that has revolutionised the world of computing, and is one of the reasons why Big Data has emerged. Indeed, with Big Data (mass data), we are forced to process voluminous data, and this is a long and arduous task with traditional tools. With Hadoop, we can use a distributed architecture to save costs and improve performance.
The difference between a distributed architecture and a traditional architecture lies in the use of a cluster of machines, in other words a group of computers. With Hadoop, data is shared between the machines in the cluster, so operations are parallelized.
There is a distinction to be made between the machines in the cluster: some machines own the data and process the data, while one coordinates them. This architecture is commonly referred to as “master-slave”. In Hadoop, the “master” machine is called the Namenode and the “slave” machines are called Datanodes.
Now that we have the basics about Hadoop, we can start talking about HDFS. For more information on Hadoop, you can read this article.

Why use HDFS?
We have mentioned the operations carried out with Hadoop, but this tool is made up of several components. We process the data using MapReduce operations, while the Yarn component is used to monitor the various machines in your cluster by allocating the necessary resources to them. HDFS is designed for file storage; as its name suggests (Hadoop Distributed File System), it is a file system.
As with our operating system’s file system, all types of file can be organised in different folders (“hierarchical file system”) with HDFS. These can be ‘classic’ files such as csv or json, or other file types used for Big Data tasks such as parquet, avro and orc. We’re not limited in the same way as a relational database; we should think of HDFS as a Data Lake. We store the raw data from our data pipeline in HDFS, then carry out processing to place it in a Data Warehouse or databases.
How does HDFS work?
Although it can be compared with a conventional operating system file system, there are differences in terms of usage and storage. We’re in a cluster of machines, so how do we know which machine in the cluster holds our data? As you may have guessed, we’re going to use Namenode.
To be able to administer the different machines in the cluster, the Namenode needs to be aware of the status of each machine, which is why we can find metadata in it.
In particular, we will know in which machines the data is stored. Another advantage of a Hadoop cluster is that we are fault tolerant. We have several machines at our disposal, so we can create copies of our data and distribute them between the machines.
So if one machine breaks down, we can still access the data. What’s more, the data is not distributed “entirely” between the machines; it is segmented into blocks. This allows us to protect ourselves against the risk of machine breakdowns by only partially losing our data.
Let’s take a look at the diagram below to get a good idea of how data is stored in HDFS:
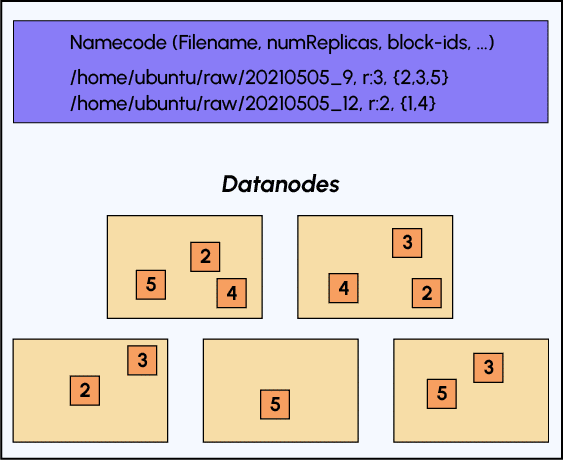
As previously stated, in the namenode we find the metadata for our file: its name, the number of replicas and its segmentation into blocks, but other metadata is also available.
These different elements confirm that using HDFS is different from using a file system via a graphical interface. In fact, we’re using it more for batch processing and we’ll be accessing our data via a link like this “hdfs:/cluster-ip:XXXX//data/users.csv”.
Find out more
Having understood how Hadoop works, we now want to practise using the HDFS file system and the Hadoop suite. However, it is difficult to use it as an individual. The first reason is simply that we don’t have a cluster of machines at our disposal. The second reason is that even with a cluster of machines, we still have to install Hadoop on it and use it in Big Data problems, which is rarely necessary for an individual.
You can learn more about the different components of the Hadoop tool by taking the Data Engineer course with DataScientest.
You will also learn more about its ‘replacement’: Spark, which can process large data much more quickly than Hadoop, but which has no storage aspect, which is why it is being taught alongside HDFS.








