MapReduce is the programming model of the Hadoop framework. It enables the analysis of massive volumes of Big Data through parallel processing. Discover everything you need to know: overview, functioning, alternatives, benefits, training...
The massive volumes of Big Data offer numerous opportunities for businesses. However, it can be challenging to process this data quickly and efficiently on traditional systems. It’s necessary to turn to new solutions specifically designed for this purpose.
The MapReduce programming model is one of these solutions. It was originally created by Google to analyze the results of its search engine. Over time, this tool has become extremely popular for its ability to break down terabytes of data to process them in parallel. This approach allows for faster results.
What is MapReduce?
The MapReduce programming model is one of the key components of the Hadoop framework. It is used to access Big Data stored within the Hadoop File System (HDFS).
The significance of MapReduce is to facilitate concurrent data processing. To achieve this, massive volumes of data, often in the order of several petabytes, are divided into smaller chunks. These data chunks are processed in parallel on Hadoop servers. After processing, the data from multiple servers is aggregated to provide a consolidated result to the application.
Hadoop is capable of executing MapReduce programs written in various languages, including Java, Ruby, Python, C++, etc.
Data access and storage are disk-based. The inputs are stored as files containing structured, semi-structured, or unstructured data. The output is also stored as files.
For example, consider a dataset of 5 terabytes. If you distribute the processing across a Hadoop cluster of 10,000 servers, each server would need to process approximately 500 megabytes of data. This allows the entire dataset to be processed much faster than traditional sequential processing.
Fundamentally, MapReduce enables running the logic directly on the server where the data resides. This approach contrasts with sending the data to the location where the logic or application resides, which accelerates processing.
Alternatives to MapReduce: Hive, Pig...
In the past, MapReduce was the primary method for retrieving data stored in HDFS. However, this is no longer the case today. There are other query-based systems like Hive and Pig.
These systems enable data retrieval from HDFS using SQL-like queries. Most of the time, though, they are executed alongside jobs written with the MapReduce model to leverage its many advantages.
How does MapReduce work?
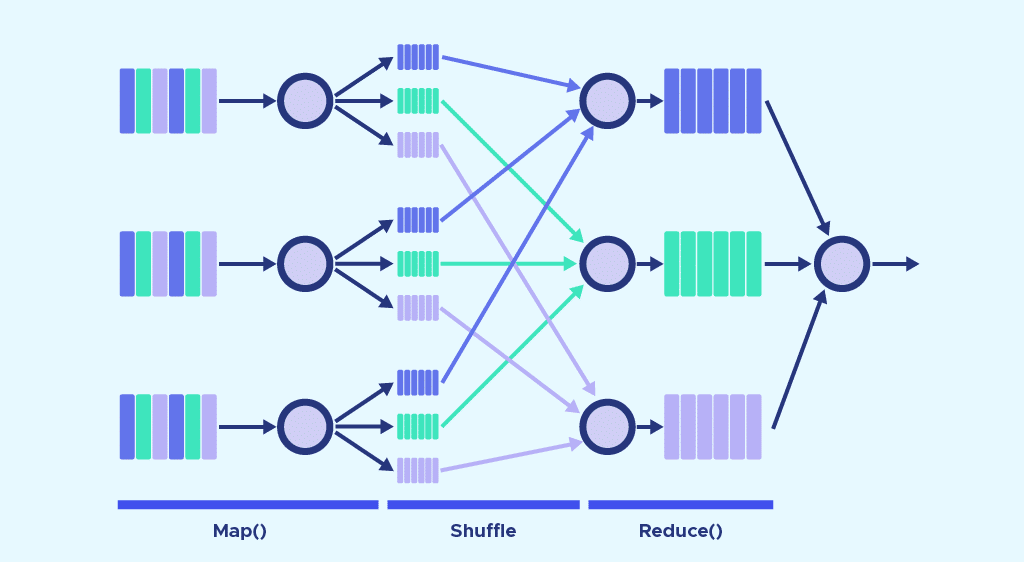
The operation of MapReduce primarily revolves around two functions: Map and Reduce. To put it simply, Map is used to break down and map the data, while Reduce combines and reduces the data.
These functions are executed sequentially. The servers running the Map and Reduce functions are referred to as Mappers and Reducers. However, they can be the same servers.
The Map function
The input data is divided into smaller blocks, and each of these blocks is assigned to a “mapper” for processing.
Let’s take an example of a file containing 100 records to process. It’s possible to use 100 mappers simultaneously to process each record separately. However, multiple records can also be assigned to each mapper.
In reality, the Hadoop framework automatically decides how many mappers to use. This decision depends on the size of the data to be processed and the available memory blocks on each server.
The Map function receives the input from the disk in the form of “key/value” pairs. These pairs are processed, and another set of intermediate key/value pairs is produced.
The Reduce function
After all the mappers have completed their processing tasks, the framework shuffles and organizes the results. It then sends them to the “reducers.” It’s worth noting that a reducer cannot start if a mapper is still active.
The Reduce function also receives inputs in the form of key/value pairs. All the values produced by the map with the same key are assigned to a single reducer. The reducer is responsible for aggregating the values for that key. Reduce then produces a final output, still in the form of key/value pairs.
However, the types of keys and values can vary depending on the use case. All inputs and outputs are stored in HDFS. It’s important to mention that the map function is essential for filtering and sorting the initial data, while the reduce function is optional.
Combine and Partition
There are two intermediate steps between Map and Reduce called Combine and Partition.
The Combine process is optional. A “combiner” is a “reducer” executed individually on each mapper server. It further reduces the data on each mapper in a simplified form. This helps simplify shuffling and organization because the volume of data to be organized is reduced.
The Partition step, on the other hand, translates the key-value pairs produced by the mappers into another set of key-value pairs before sending them to the reducer. This process decides how the data should be presented to the reducer and assigns them to a specific reducer.
The default partitioner determines the “hash” value for the key produced by the mapper and assigns it to a partition based on that value. The number of partitions is equal to the number of reducers. Once partitioning is complete, data from each partition is sent to a specific reducer.
Examples of use cases
The MapReduce programming paradigm is ideal for any complex problem that can be solved through parallelization. It’s therefore a suitable approach for Big Data.
Companies can use it to determine the optimal price for their products or to assess the effectiveness of an advertising campaign. They can analyze clicks, online sales, or Twitter trends to decide which products to launch to meet consumer demand.
While these calculations were once very complicated, MapReduce now makes them simple and accessible. It’s possible to perform these functions on a network of inexpensive servers, making Big Data processing much more cost-effective.
What are the advantages of MapReduce ?
There are many advantages to using MapReduce. Firstly, this programming model makes Hadoop highly scalable, enabling large datasets to be stored in distributed form across multiple servers.
This makes parallel processing possible. Map and Reduce tasks are separated, and parallel execution reduces overall run time.
It’s also a cost-effective solution for data storage and processing. The performance/price ratio is unrivalled.
With MapReduce, Hadoop is also extremely flexible. It is possible to store and process data from different sources, even unstructured data.
Speed is also a key strength. The distributed file system enables data to be stored on a cluster’s local disk, and MapReduce programs to be stored on the same servers. This means that data can be processed more quickly, as it does not need to be accessed from other servers.
How can I learn to use MapReduce ?
Companies in all sectors are collecting more and more data. They therefore need to process this data in order to make the most of it, and MapReduce is one of the main solutions.
As a result, learning to master Hadoop and MapReduce opens up a wide range of career opportunities. It’s a highly sought-after skill.
DataScientest is the place to go to master this tool. The Hadoop framework and its various modules are at the heart of our Data Engineer training, within the “Big Data Volume” module.
You’ll learn how to use Hadoop, Hive, Pig, Hbase and Spark, as well as all the theoretical aspects of Big Data architectures. The other modules in this course cover Python programming, databases, Big Data Vitesse and, finally, automation and deployment.
On completion of this course, you’ll have all the skills required to start working directly as a Data Engineer. This is a fast-growing profession, and you’re guaranteed a job with a high salary in the field of your choice.
Like all our training courses, the Data Engineer course adopts a blended learning approach, combining face-to-face and distance learning. It can be taken as a Continuing Education course or as an intensive BootCamp.
On completion of the program, students receive a diploma certified by Sorbonne University. Among alumni, 93% have found a job immediately. Don’t waste another moment and discover the Data Engineer training program.
You know all about MapReduce. Discover our complete dossier on Hadoop, and our introduction to the Python programming language.








