
Distributed architectures are information systems that distribute and use available resources that are not located in the same place or on the same machine. In this article, we will explain in detail what these architectures are, their advantages over other architectures and how they are used in practice in Data Science.
What is a distributed architecture?
With the exponential evolution of technology and the facilitation of access to information, more and more computer systems such as applications or their deployment are linked together by a network and communicate data. In order to implement a complex system requiring the execution of several interconnected services, monolithic architectures have become unusable and obsolete.
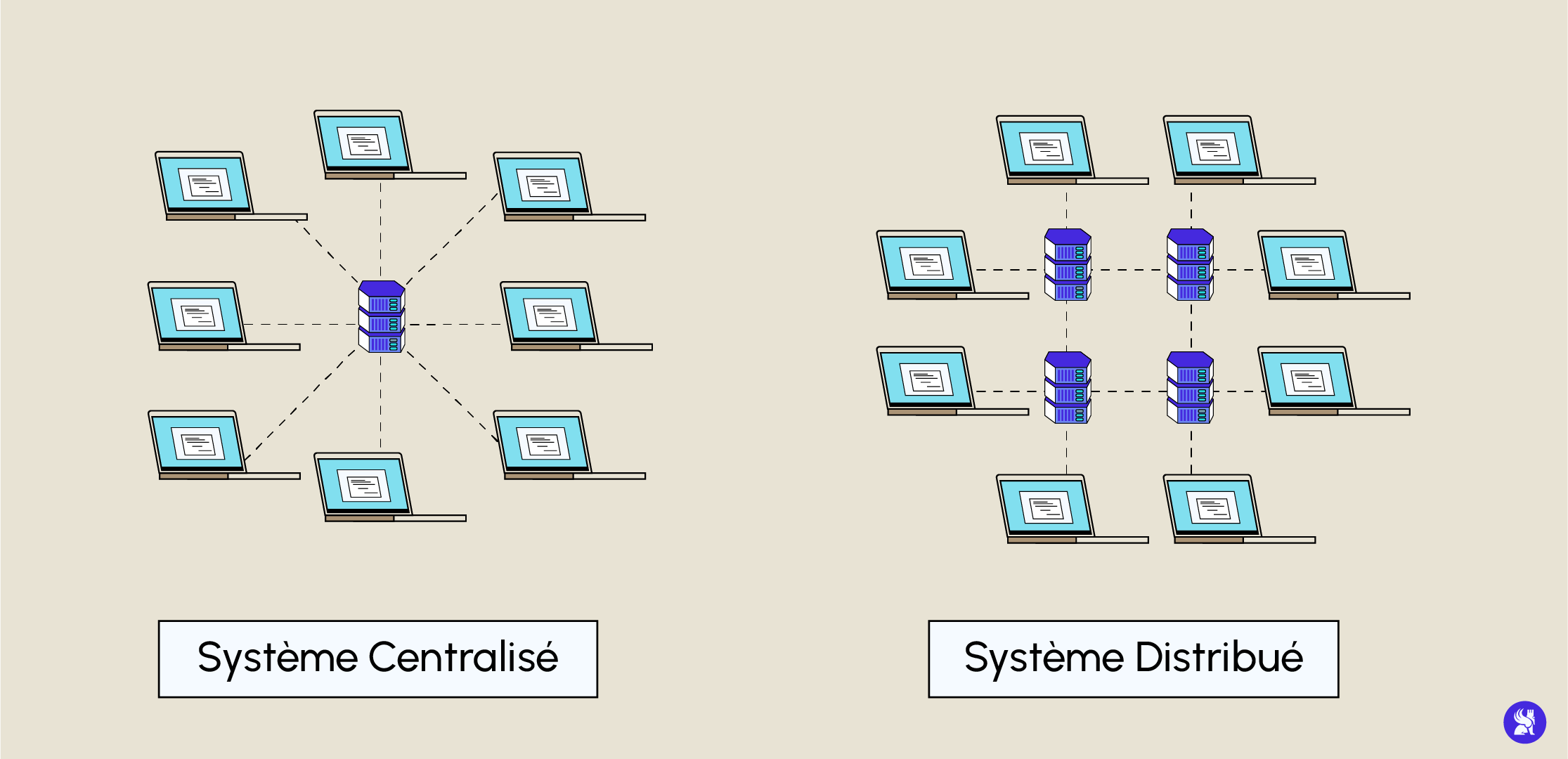
In such an architecture, all available resources are located in the same place and on the same machine, so modifying one part of the system means modifying all the other parts (to keep them coherent), which is unthinkable in a system where potentially thousands of services inter-communicate.
To combat the limitations of monolithic architecture, we can use distributed architecture, but what exactly is distributed architecture?
Distributed architecture is the exact opposite of monolithic architecture. Where a monolithic architecture would centralize all its resources and systems in the same place and on the same machine, a distributed architecture uses resources available on different machines in different locations.
Such an architecture can be either an information system or a network, or both. The Internet is an example of a distributed network, since it has no central node and accesses different resources distributed over several nodes (spread across the network), which communicate via messages across the network
One of the characteristics of distributed architectures is that each node can provide client-server functionality, i.e. it can act both as a provider and consumer of services or resources. The result is total resource sharing.
Fifty years ago, getting two machines to talk to each other over the network required precise knowledge of network protocols and sometimes even network hardware. With the advent of object-oriented programming, monolithic architectures gave way to distributed architectures, which are now viable thanks to new high-level libraries enabling different machines to communicate with several objects running on different machines.
Distributed architectures are based on the ability to use objects distributed over the network. Objects distributed on the network (and not located in the same place) communicate via messages using specific technologies such as Common Object Request Broker Architecture or CORBA, which enables different objects written in different languages such as C++ or Java to communicate with each other. Another well-known tool is Java EE software, which enables multiple objects to communicate in a distributed architecture, thanks to its catalog of specialized libraries.
Today, one of the disadvantages of this type of architecture paradoxically stems from its initial advantage: the isolation of the various services, and therefore of the teams of developers working on them independently. Indeed, because of its potential geographical remoteness, the heterogeneity of the tasks tackled and the isolation of technical responsibilities, distributed architecture is susceptible to poor maintainability, which can have serious consequences on costs and service functionality. Stacking uncontrolled, independent building blocks on top of each other can lead to exponential drift. The architecture would instantly lose its ability to quickly understand the various services developed and their interconnections.
The relationship between Big Data and distributed architecture
It’s important to know that in a big data architecture, distribution is a key element. Before, we were in a system of vertical scalability, i.e. we added RAM, CPU, etc. to solve any problems linked to storage or computing power. The problem was that this was very expensive, and we were using hardware that was destined to be thrown away.
Since the emergence of Big Data, we’ve switched to a horizontal scalability architecture to solve this problem. This means that we prefer to add computers to an architecture to solve big data problems. This architecture has a number of advantages. First of all, all data is replicated at a certain replication factor and partitioned across the different machines.
This means greater data security. What’s more, since we’re using different machines, calculations can be parallelized in a distributed architecture, so we gain in calculation speed and computing power. Finally, scaling up is easier. Let’s say we run out of storage in our machines. Instead of swapping computers for more powerful ones (vertical scalability), we can add another machine to our architecture, thus solving the storage problem.
More specifically, in Data Science, to successfully perform calculations with a distributed architecture and manage storage between the various nodes of this distributed architecture, we mainly use Hadoop. This framework is made up of three sub-frameworks: HDFS, MapReduce and YARN.
HDFS is Hadoop’s storage manager. It stores the various blocks of partitions on the different nodes of the distributed architecture.
MapReduce is the computation system in a distributed architecture. It performs calculations in parallel on the different nodes of the architecture to produce a final result. It operates in the form of a key/value system with different stages. The first is the mapping phase, which aggregates the requested query according to a key across all the blocks in our document. Next comes the shuffle phase, which sorts the results of the various aggregations according to this key. Then comes the reducing phase, which applies the query (e.g. a sum) to our various sorted keys. Finally, there’s the final phase, which involves re-aggregating our different reducing operations into a single node.
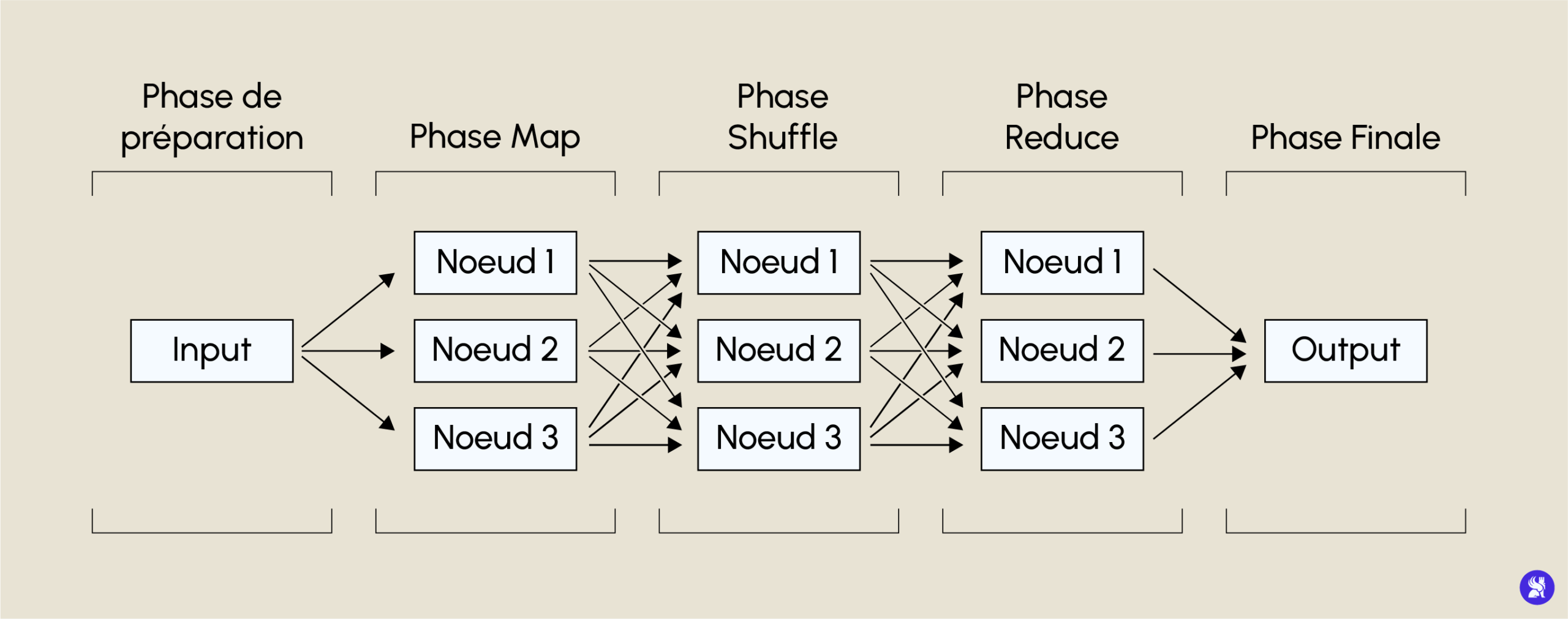
The third sub-framework, YARN, is Hadoop’s orchestration manager. It knows how to replicate data, how to send different blocks to different nodes and which partition to use for MapReduce.
Hadoop is obviously only one of the many tools available for building distributed architectures. Another widely-used tool is Spark, available in several programming languages: Scala, Python, Java and R.
If you’d like to find out more about distributed architectures and how to use them, don’t hesitate to make an appointment with our experts to learn more about Data Science and to find out about our Data Engineer training course, the brochure of which you can find here!








