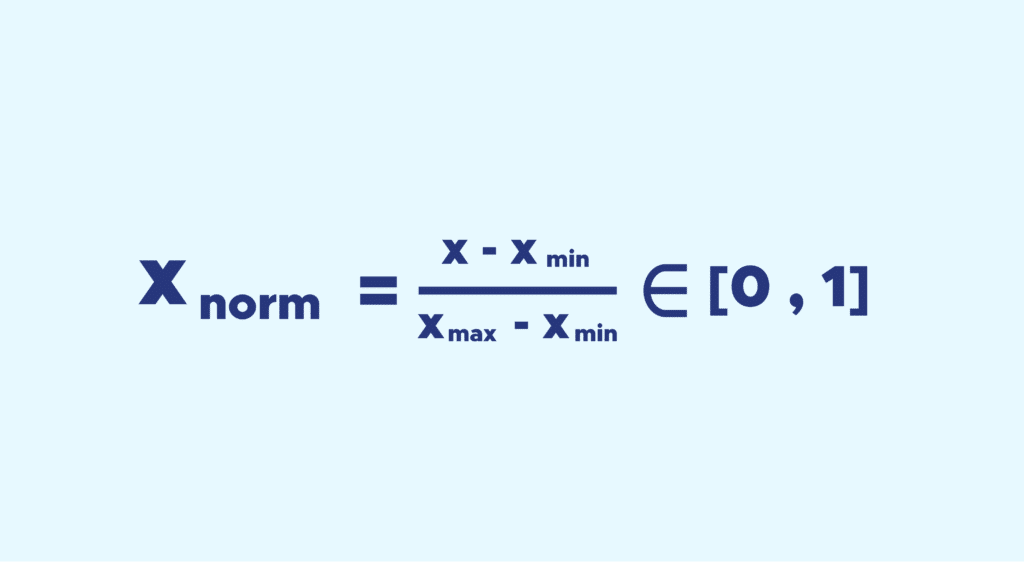
Daniel is the technical support of DataScientest’s trainings. It is the expert on every subject related to data science. Today, we have managed to get a quick interview with him, so that he can answer a few of our questions about data normalization.
What is Data Normalization?
Normalization, as it is heard in the data science area, is a very important concept in Data pre-processing, when you need to work on a Machine Learning project.
Two main processes are implied when we talk about normalization: normalization and standard normalization, more commonly known as standardization. Generally, these two processes have the same purpose: to resize numerical variables so that they are comparable on a common scale.
In mathematics terms, what do we have?
Let’s consider a numerical variable with n observations, than can be written as followed:
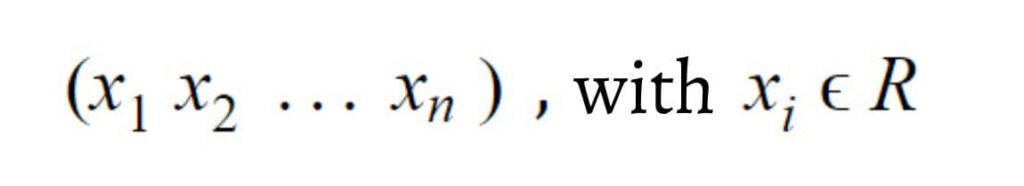
As we have a finite number of real values, we can extract various statistical pieces of information, including min, max mean, and standard deviation. The process of normalization only needs the min and max functions.
The purpose here is to bring back all the values of the variable between 0 and 1 while keeping some distance between the values.
To do that, you’ll use a simple formula:
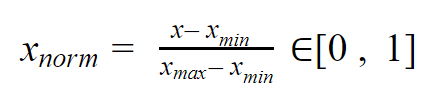
Regarding the standardization, the transformation is more diffiuclt than easily bringing back the values between 0 and 1. It aims at bringing back the average μ to 0 and the standard deviation to 1.
Again, the process is not very complicated: if you already know the mean μ and the standard deviation σ of a variable X = x1 x2 xn you will write the standardized variable as followed:
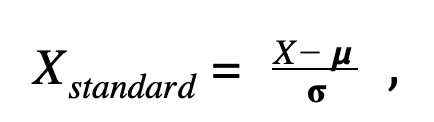
What is the link between Data Normalization and Data Science?
In Data Science, you’re often dealing with numerical data, and you can rarely compare these data in their original state.
Working with variable scale data can be a problem in analysis because a numerical variable with a range of values between 0 and 10,000 will be more important in the analysis than a variable with values between 0 and 1, which would cause a bias problem later on.
However, be careful not to consider normalization as a mandatory step in processing Data, it constitutes a loss of information in the short term and can be detrimental in certain cases!
How do you normalize data concretely?
With Python it is very simple, many libraries allow it. I will only mention Scikit-learn because it is the most used in Data Science. This library offers functions that perform the desired normalizations in a few simple lines of code.
However, it is important to put the use cases in context, because in practice it is not enough to apply a silly normalization to all the Data we have when we already normalized our training data.
Why not? The reason is very simple: It is not possible to apply this same transformation to a test sample, or new data.
It is obviously possible to center and reduce any sample in the same way, but with an average and standard deviation that will be different from those used on the training set.
The results obtained would not be a fair representation of the performance of the model, when applied to new data.
So, rather than applying the normalization function directly, it is better to use a Scikit-Learn feature called transformer API, which will allow you to adjust (fit) a preprocessing step using the training data.
So when normalization, for example, is applied to other samples, it will use the same saved average and standard deviations.
To create this ‘adjusted’ preprocessing step, simply use the ‘StandardScaler’ function and adjust it using the training data. Finally, to apply it to an array of data afterward, simply apply the following formula: scaler.transform().








