
With the advent of NoSQL databases, Redis is coming into its own, offering in-memory data management.
Created in 2009 by Salvatore Sanfilippo, Redis has become one of the most popular NoSQL databases. Named the database most loved by developers for 5 years in a row according to the annual “Stackoverflow Developer Survey”, Redis is currently used by numerous companies such as Twitter, GitHub and Snapchat. Find out all you need to know about this fast in-memory database.
What is Redis?
Redis (Remote Dictionary Server) is an open source data management system written in C, designed to store, retrieve and manipulate various types of data. It is a NoSQL key/value pair database.
Redis can be configured to store data on disk, but is mainly used for data management in RAM, making it much faster than traditional databases.
With its fast response times enabling millions of queries per second for real-time applications, Redis is used in production in sectors such as video games, advertising, financial services, healthcare and IoT.
How does Redis work?
Redis is a NoSQL database whose management system is based on a key-value structure, where each value is associated with a unique key. Redis data structures natively support different types of values, such as integers, strings, hashes, lists, sets, sorted sets, bitmaps, bitfields, hyperLogLog, spatial indexes and streams.

Each structure type has dedicated commands to facilitate the execution of operations on the different value types. Data can then be stored in RAM or permanently on disk using the Redis backup function. Data recovery in the event of system failure is made possible by these backups, which can be performed automatically or manually.
The tool offers a variety of ways of modeling data in a wide range of modern use cases.
Redis is not a relational database, so the ACID concept (Atomicity, Consistency, Isolation, Durability) is not applicable. However, atomic transactions and data isolation to ensure data integrity are provided by the database management system.
How does Redis work?
Redis is a NoSQL database whose management system is based on a key-value structure, where each value is associated with a unique key. Redis data structures natively support different types of values, such as integers, strings, hashes, lists, sets, sorted sets, bitmaps, bitfields, hyperLogLog, spatial indexes and streams.
Each structure type has dedicated commands to facilitate the execution of operations on the different value types. Data can then be stored in RAM or permanently on disk using the Redis backup function. Data recovery in the event of system failure is made possible by these backups, which can be performed automatically or manually.
The tool offers a variety of ways of modeling data in a wide range of modern use cases.
Redis is not a relational database, so the ACID concept (Atomicity, Consistency, Isolation, Durability) is not applicable. However, atomic transactions and data isolation to ensure data integrity are provided by the database management system.
What are Redis' features?
If Redis is so popular with developers, it’s due to the many features offered by the database.
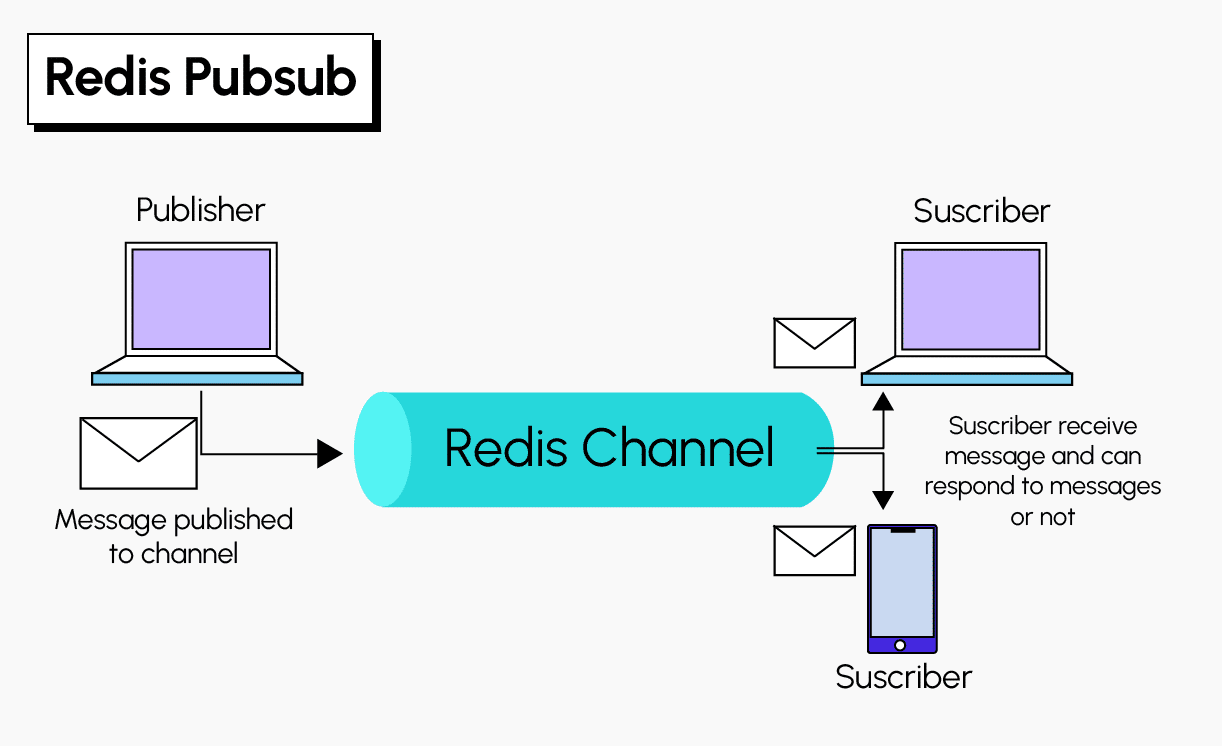
Redis’ Publish/Subscribe (pub/sub) function enables messages to be broadcast in real time between different parts of an application. How this works is simple.
Messages sent by publishers are not sent directly to specific recipients (subscribers), but pass through channels. Only subscribers to the channel in question receive the message, which is sent “at-most-once”.
This means that once a message has been sent by the Redis server, there’s no chance of it being sent again. In the event of an error or network disconnection, the message is lost forever. This decoupling of publishers and subscribers enables greater scalability and a more dynamic network topology.
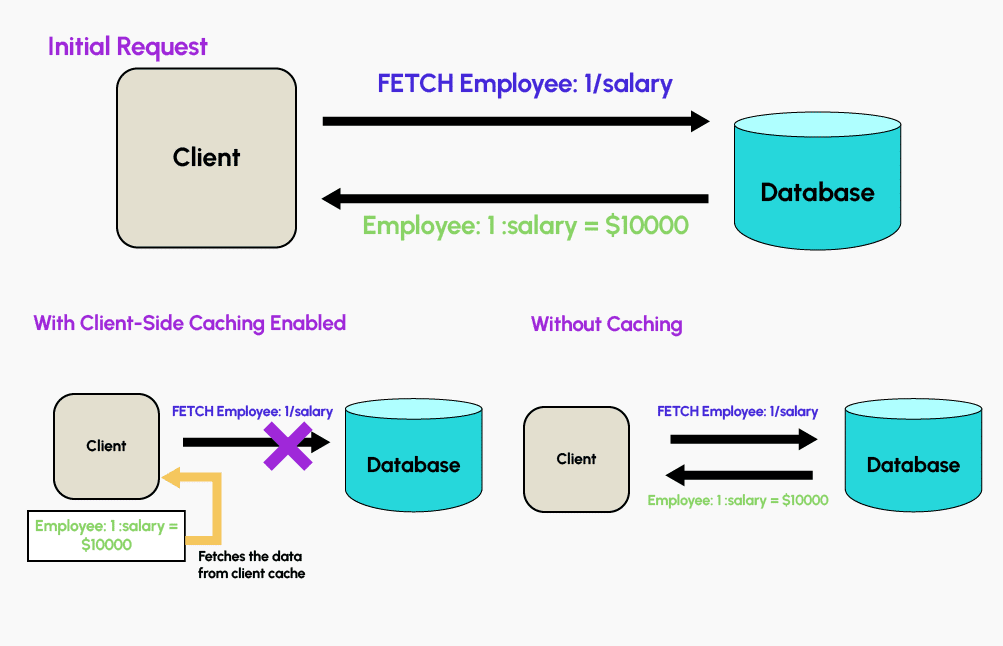
Redis offers client-side caching functionality. By exploiting the memory available on application servers to store a subset of database information directly in the application, it enables the creation of high-performance services.
The application will then store the response to the most common queries directly in its application memory and reuse them later, without having to recontact the database. It is possible to ensure that cached data is always up to date by configuring an expiration of the stored data after a certain period of time.
The user can send multiple Redis commands to the database in a single network operation, thanks to the Redis pipeline. Instead of sending each Redis command separately, a pipeline allows all commands to be sent at once, encoding them in a single network packet.
The Redis server then stores these commands in a temporary queue and executes them all in succession, returning the results to the client in the same order. This is a very useful feature for applications that need to process a large number of commands at once, and to have considerably reduced latency.
Redis also supports automatic data sorting, which saves time and facilitates data management. This feature is particularly useful for applications requiring real-time retrieval of sorted data, such as leaderboards.
In conclusion
Redis is a database used mainly in production that is much faster than traditional databases thanks to its in-memory storage, using disk only for persistence. It can process millions of queries per second, making it ideal for real-time applications. However, Redis’ strength doesn’t mean it’s ideally suited to the needs of Big Data, as all the data still resides in RAM. For very large datasets, you can expect performance problems and high costs for servers with sufficient RAM.
Redis is simple to use, both in terms of setting up the environment and in practical use. However, it is possible to solve complex problems with this technology, and even use it for APIs or artificial intelligence such as facial recognition.
The technology is highly flexible, as it is supported by numerous programming languages such as C, C#, C++, Java, Python, Perl, PHP and Node.js, and natively supports most data types already known to users.
Overall, Redis is an excellent choice for applications requiring a fast, reliable database, and those that don’t require the manipulation of large quantities of data. Appreciated for the production phase, it is nevertheless sometimes preferable to choose technologies designed specifically to meet the needs of Big data, such as Apache Hadoop, Apache Spark, or Cassandra. Many companies are looking to master these tools. Don’t hesitate to consult DataScientest’s Data Engineer training program to acquire the skills you need in the world of Big Data.








