Thanks to the development of Big Data and Artificial Intelligence, Data Scientists can use data learning models to perform predictive analyses. Among the most effective methods is ensembling.
So what is it all about? How does model assembly work? What are its advantages and disadvantages? That’s what we’re going to find out in this article.
What is ensembling?
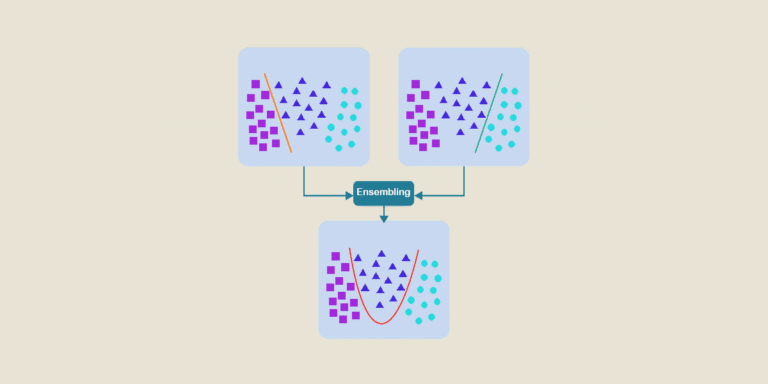
Ensembling combines several neural network models to solve a given problem. Each model uses its own learning techniques. This enriches predictions.
With model ensemble learning, it is possible to obtain much more reliable and relevant results than with any single model.
How does model ensembling work?
Any learning model requires the use of large quantities of data to produce relevant results. However, depending on the technique used, care must be taken in selecting the right components (share of bias and variance).
Here are a few examples of learning techniques:
- Bagging: the aim is to reduce variance, in order to improve the stability of predictions. In this case, you need components with low bias and high variance. The biases then counteract the variances. This makes the results less sensitive to the specifics of the training data.
- Boosting: conversely, the aim is to reduce bias. To achieve this, models are run sequentially.
- Stacking: improves accuracy while keeping variance and bias low. This is particularly useful for random forests.
In principle, ensembling runs the models separately before combining the predictions. This model assembly then reduces the variance of predictions obtained on test and validation data.
Good to know:
Although the combination of several models can produce more reliable predictions, the number of models should be limited. This is both because of the costs involved in training, but also because of a drop in performance linked to the addition of new models.
Generally speaking, the right balance is between 3 and 10 trained models. This is the number that will deliver the best results.

What are the advantages?
Ensembling is one of the most commonly used Machine Learning techniques. And with good reason: it offers data experts a multitude of benefits:
- Accuracy: in general, model assemblies offer better results than any single-component model. In most cases, results improve with the size of the ensemble. But as we saw earlier, it’s important to strike the right balance. In other words, don’t add too many models.
- Relevance: model assemblies are better able to generalize in response to a given problem. This limits the dispersion of analyses.
- Flexibility: with ensembling, Data Scientists have access to large quantities of data, but it is entirely possible to adapt results to the level of information available. In particular, they can select the best model from among several choices.
What are the limits?
Although ensembling is very effective, it does have certain limitations. For example:
- Only models trained with the same parameters can be combined;
- Some learning models cannot be assembled. This is particularly true of models trained using K-Fold cross-testing, with vectors or image features, partitioned models or computer vision models.
Things to remember :
- Ensembling combines several neural network models to optimize the relevance of predictive results.
- Prior to assembly, each model is run separately, with its own learning techniques.
- Model ensemble learning improves the accuracy and relevance of predictions.
- That said, it is not possible to use this technique with all models.








