
Adversarial Training: Since the 2010s, thanks to advances in Machine Learning, especially Deep Learning with deep neural networks, errors have become increasingly rare. Today, they are even very exceptional. However, these models sometimes still make mistakes, without researchers succeeding in developing effective defense systems.
Adversarial Examples, or contradictory examples, are among those inputs that the model misclassifies. Faced with this, a defense technique called Adversarial Training has been developed. But how does this defense technique work? Is it really effective?
What is an Adversarial Example?
Adversarial Training is a technique that has been developed to protect Machine Learning models from Adversarial Examples. Let’s briefly recall what Adversarial Examples are. These are inputs that are very slightly and cleverly perturbed (such as an image, text, or sound) in a way that is imperceptible to humans but will be misclassified by a machine learning model.

What is astonishing about these attacks is the model’s confidence in its incorrect prediction. The example above illustrates this well: while the model only has a confidence rate of 57.7% for the correct prediction, it will exhibit a very high confidence rate of 99.3% for the incorrect prediction.
These attacks are very problematic. For example, an article published in Science in 2019 by researchers from Harvard and MIT demonstrates how medical AI systems could be vulnerable to adversarial attacks. That’s why it’s necessary to defend against them. This is where Adversarial Training comes in. It, along with ‘Defensive Distillation,’ is the primary technique to protect against these attacks.
How does Adversarial Training work?
How does this technique work? It involves retraining the Machine Learning model with numerous Adversarial Examples. Indeed, during the training phase of a predictive model, if the input is misclassified by the Machine Learning model, the algorithm learns from its mistakes and adjusts its parameters to avoid making them again.
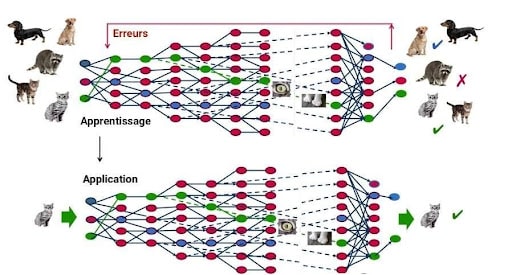
Thus, after initially training the model, the model’s creators generate numerous Adversarial Examples. They expose their own model to these contradictory examples to prevent it from making these mistakes again.
While this method defends Machine Learning models against some Adversarial Examples, does it generalize the model’s robustness to all Adversarial Examples? The answer is no. This approach is generally insufficient to stop all attacks because the range of possible attacks is too wide and cannot be generated in advance. Thus, it often becomes a race between hackers generating new adversarial examples and designers protecting against them as quickly as possible.
In a more general sense, it is very difficult to protect models against adversarial examples because it is nearly impossible to construct a theoretical model of how these examples are created. It would involve solving particularly complex optimization problems, and we do not have the necessary theoretical tools.
All strategies tested so far fail because they are not adaptive: they may block one type of attack but leave another vulnerability open to an attacker who knows the defense used. Designing a defense capable of protecting against a powerful and adaptive attacker is an important research area.
In conclusion, Adversarial Training generally fails to protect Machine Learning models against Adversarial Attacks. If we were to highlight one reason, it’s because this technique provides defense against a specific set of attacks without achieving a generalized method.
Do you want to learn more about the challenges of artificial intelligence? Interested in mastering the Deep Learning techniques discussed in this article? Find out about our Machine Learning Engineer training.








