Nowadays, we are witnessing a resurgence of interest and progress in new technologies related to artificial intelligence, especially in the use of neural networks. We can observe their power in image classification and object recognition. At first glance, we might think that these neural networks are very powerful and infallible. This article aims to understand the challenges and impacts that adversarial examples can have.
However, with the rapid developments in artificial intelligence (AI) and deep learning (DL) techniques, it is essential to ensure the security and robustness of deployed algorithms. It would be legitimate to question and investigate the potential limitations and performance issues associated with their use.
What is an "adversarial example"?
An “adversarial example” is an example of an object capable of deceiving and fooling a neural network algorithm into believing it should be classified as a certain object when it is not.
An “adversarial example” is a set of correctly initialized data to which an imperceptible perturbation has been added by the neural network to induce incorrect classification.
What are the risks?
When you ask a human to describe how they detect a panda in an image, they may look for physical features such as round ears, black eye patches, the snout, furry skin, and provide other information like the type of habitat where they expect to see a panda and the kind of poses it takes.
For an artificial neural network, as long as applying pixel values to the equation yields the correct answer, it is convinced that what it sees is indeed a panda. In other words, by altering the pixel values of the image in the right way, you can deceive the AI into thinking it doesn’t see a panda.
In the case of the adversarial example we will see in the rest of the article, AI researchers added a layer of noise to the image. This noise is barely perceptible to the human eye. However, when the new pixel values pass through the neural network, they produce the result of a gibbon, even though it’s actually a panda.
Adversarial examples make machine learning models vulnerable to attacks, as in the following scenarios:
1. A self-driving car collides with another car because it fails to recognize a stop sign.
– Someone placed an image on the stop sign that looks like a stop sign to humans but was designed to resemble a no-parking sign for the car’s sign recognition software.
2. A spam detector fails to classify an email as spam.
– The spam email was designed to look like a normal email, but with the intent to deceive the recipient.
3. An AI-powered scanner at the airport scans luggage for weapons.
– A knife was designed to evade detection by making the system believe it’s an umbrella.
4. An automated AI that doesn’t detect a disease (e.g., in radiology) when it actually corresponds to a serious illness.
Let’s now look at some concrete examples that have fooled neural networks.
In the example below, we can see that with a slight perturbation invisible to the naked eye, it was possible to deceive the neural network, which classified a picture of a dog as an ostrich.

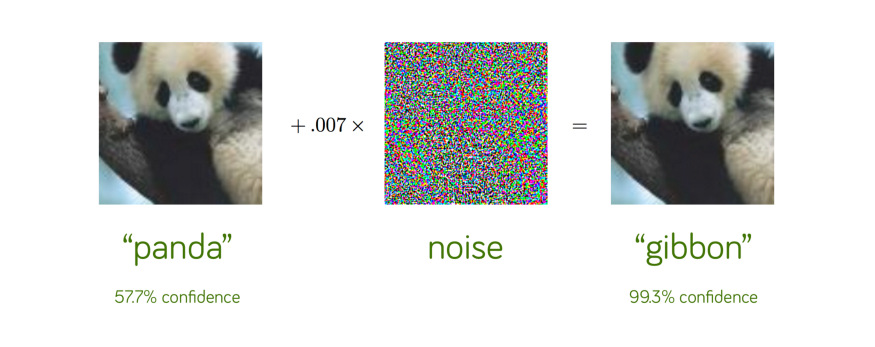
Let’s take another example of image classification with pandas that a neural network correctly recognizes as a panda with a confidence rate of 57.7%.
If we add a carefully constructed perturbation, the same neural network now classifies the image as a gibbon with a confidence of 99.3%!
It’s clearly an optical illusion, but only for the neural network. We can confidently say that both of these images are indeed pandas. In fact, we can’t even perceive that a slight perturbation was added to the original image on the left to create the adversarial example on the right!
In the following example, you can see the impact this can have in everyday life on self-driving cars that misinterpret a traffic sign.

In the case above, the perturbation perceptible to the human eye was not detected by the neural network. The stop sign on the right above was classified as a 45 km/h speed limit sign. We can still see the challenges and limitations that neural networks can face in image classification.
How are adversarial examples created?
It is crucial to understand the distinction between targeted and non-targeted attacks.
A non-targeted attack simply aims to induce misclassification, regardless of the specific category. The goal is solely to achieve an incorrect classification of the object by the neural network.
In contrast, a targeted attack intends to trigger a misclassification in a particular category. For example, a non-targeted attack on an image of a dog would seek to get a classification other than “dog” by the neural network. Conversely, a targeted attack on the same dog image would aim to classify the dog as an ostrich, but not as a cat, for example.
There are several methods to create adversarial examples, including those used in cyberattacks, such as data poisoning, Generative Adversarial Networks (GANs), and robot manipulation.
How can I protect myself against adversarial examples?
There are several ways to defend against adversarial examples, but it’s important to note that the fight against these attacks remains a rapidly evolving research area.
Adversarial training is one of the simplest and most natural defense methods. It involves putting oneself in the attacker’s shoes by generating adversarial examples against one’s own neural network and then training the model on these generated data. While this can help improve the model’s robustness, attackers can still find subtle perturbations to deceive the network.
Another defensive approach is defensive distillation. It entails creating a second model whose decision boundary is smoothed in directions susceptible to attack. This model acts as an additional filter to detect anomalies in inputs, making it more challenging for attackers to spot modifications that would lead to misclassification.
However, it’s important to note that research in this field is continually evolving. New attacks are regularly developed to circumvent new defenses, making the security of neural networks an ongoing challenge.
Conclusion
Adversarial examples highlight surprising vulnerabilities in many modern machine learning algorithms. These failures demonstrate that even simple algorithms can behave unexpectedly compared to the intentions of their designers. This is why Data Scientists are encouraged to engage in research and design methods to prevent adversarial examples, reducing the gap between designers’ intentions and the actual behavior of algorithms.
If you want to master the Deep Learning techniques discussed in this article, we invite you to inquire about our Data Scientist training program.








