U-NET is a neural network model dedicated to Computer Vision tasks and more particularly to Semantic Segmentation problems. Discover all you need to know: presentation, functioning, architecture, advantages, training…
Artificial intelligence is a broad technology with many branches. Computer Vision is one of these sub-categories.
It is an interdisciplinary scientific field that aims to enable computers to “understand” images and videos. The aim is to automate the tasks performed by the human visual system.
Thanks to Deep Learning, a lot of progress has been made in the field of computer vision in recent years. Machines are now able to compete with human vision in certain situations.
The different tasks of Computer Vision
There are various computer vision tasks. One of the most common applications is image classification. This involves letting the computer identify the main object in an image and assigning a label to classify the image.
It is also possible to let the computer locate the location of the object in the image. It does this by enclosing the object in a “Bounding Box” that can be identified by numerical parameters related to the edges of the image.
Object classification is limited to one object per image. Object detection is more complex and requires the computer to detect and locate all the different objects within an image.
Semantic segmentation involves labeling each pixel in an image with a class corresponding to what is being represented. This is also known as “dense prediction”, as each pixel must be predicted.
Unlike other computer vision tasks, semantic segmentation does not just produce labels and bounding boxes. It generates a high-resolution image, in which each pixel is classified.
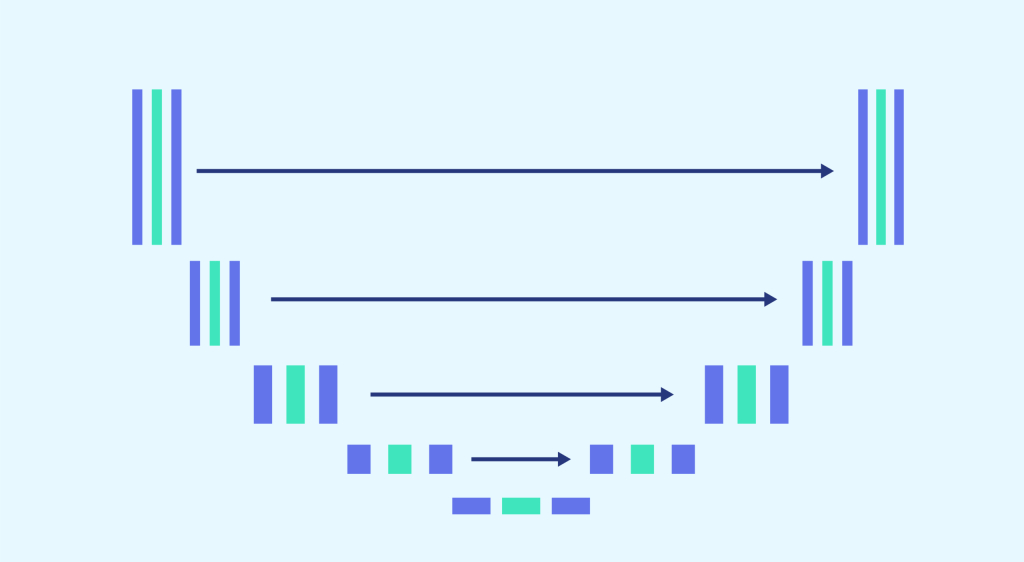
Instance segmentation goes even further, by classifying each instance of the same class separately. For example, if an image shows three dogs, each dog is an instance of the class “Dog”. Each will be classified separately, for example using different colours.
Through these different tasks, the computer “understands” the content of the images with an increasingly precise level of granularity. In this issue, we will focus on the semantic segmentation task.
Applications and use cases of Semantic Segmentation
Semantic segmentation is used for a wide variety of applications. Autonomous vehicles, for example, require perception, planning and execution in constantly changing environments.
They also require high accuracy, as safety must be foolproof on the road. Thanks to semantic segmentation, it is possible for unmanned cars to detect open spaces on lanes, road markings and traffic signs.
This AI technique is also used for medical diagnostics. The machines can support the analyses carried out by radiologists in order to reduce the time needed to make diagnoses.
Another use case is satellite mapping, which is very important for monitoring deforestation areas or for urbanisation. Semantic segmentation allows distinguishing different types of land in an automated way. The detection of buildings and roads is also very useful for traffic management or urban planning.
Finally, precision agriculture robots can use semantic segmentation to distinguish plantations from weeds. This allows them to automate weed control using less herbicide.
What is U-NET?
There are different methods to solve semantic segmentation problems. The traditional approaches are to detect points, lines or edges. It is also possible to rely on morphology, or to assemble clusters of pixels.
Deep learning convolutional neural networks are now widely used. They allow us to tackle more complex problems through image segmentation.
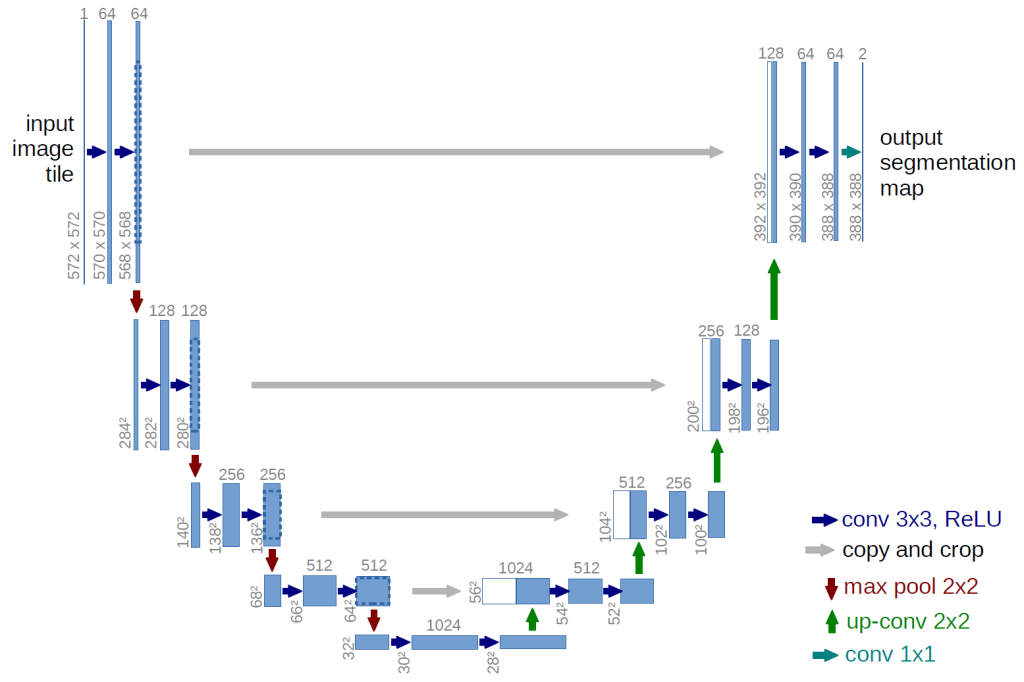
One of the most widely used neural networks for image segmentation is U-NET. It is a Fully Convolutional Neural Network Model. This model was originally developed by Olaf Ronneberger, Phillip Fischer, and Thomas Brox in 2015 for medical image segmentation.
The U-NET architecture is composed of two “paths”. The first is the contraction path, also called the encoder. It is used to capture the context of an image.
It is in fact an assembly of convolution layers and “max pooling” layers allowing the creation of a feature map of an image and the reduction of its size to reduce the number of network parameters.
The second path is the symmetric expansion path, also known as the decoder. It also allows for accurate localisation through transposed convolution.
The benefits of U-NET
In the field of Deep Learning, it is necessary to use large data sets to train models. It can be difficult to assemble such large volumes of data to solve an image classification problem, in terms of time, budget and hardware resources.
Data labelling also requires the expertise of several developers and engineers. This is particularly the case for highly specialised fields such as medical diagnostics.
U-NET addresses these problems, as it is effective even with a limited data set. It also offers higher accuracy than conventional models.
A conventional autoencoder architecture reduces the size of the input information and then the next layers. Decoding then begins, the linear feature representation is learned, and the frame size gradually increases. At the end of this architecture, the output size is equal to the input size.
Such an architecture is ideal for preserving the initial size. The problem is that it compresses the input in a linear way, which prevents the transmission of all the features.
This is where U-NET comes into its own with its U-shaped architecture. The deconvolution is done on the decoder side, which avoids the bottleneck problem encountered with an auto-encoder architecture and thus avoids the loss of features.
How to learn to use U-NET?
As AI and Computer Vision are increasingly exploited in all sectors, mastering Deep Learning and various models like U-NET is a valuable and coveted skill.
To acquire it, you can turn to DataScientest training courses. Machine Learning and Deep Learning are at the heart of our Data Scientist course.
Through this course you will also learn Python programming, DataViz, and the use of databases and Big Data tools. At the end of the course, you will have all the necessary skills to work as a data scientist in a fast-growing profession.
Our professional training courses are designed to meet the real needs of companies and organisations. They can be done as a BootCamp, or in continuous format.
We offer an innovative Blended Learning approach, combining. At the end of the programme, you will receive a diploma certified by the Sorbonne University.








