
Spark Streaming ist eine innovative Lösung für die Verarbeitung von Daten in Echtzeit. Es ist eine Komponente des Apache Spark Frameworks und bietet außergewöhnliche Leistung, Skalierbarkeit und Zuverlässigkeit.
Dieses verteilte Echtzeitverarbeitungssystem wurde entwickelt, um die komplexesten Anforderungen an die Verarbeitung von Echtzeitdaten zu erfüllen. Es ermöglicht komplexe Analysen und Transformationsaufgaben für Daten aus verschiedenen Quellen (wie soziale Netzwerke, angeschlossene Geräte oder Sensoren).
Dank seiner fortschrittlichen Funktionen, wie der Verwaltung sehr großer Datenströme, der Integration verschiedener Datenquellen und der Unterstützung von Fehlertoleranz, hat sich Spark Streaming als erste Wahl für Unternehmen etabliert, die eine effiziente Verarbeitung von Echtzeitdaten anstreben.
Die Anwendungsbereiche für eine solche Technologie sind sehr vielfältig. Sie reichen von der Betrugserkennung über die Überwachung von Finanzmärkten bis hin zu personalisierten Empfehlungen für Online-Einkäufe und natürlich Analysen in sozialen Netzwerken.
Wie funktioniert das Streaming von Daten mit Spark Streaming ?
Daten-Streaming ist ein Echtzeitprozess, bei dem Daten, die kontinuierlich anfallen, verarbeitet und in Echtzeit analysiert werden.
Spark Streaming verwendet eine sogenannte „Micro-Batch“-Architektur, was bedeutet, dass die Daten in kleine Stapel, sogenannte „Batches“, aufgeteilt und sequentiell verarbeitet werden. Jeder Batch wird in Spark als RDD (Resilient Distributed Dataset) behandelt, wodurch die parallele Verarbeitungsleistung von Spark genutzt werden kann. Zur Erinnerung: Ein RDD ist die Datenbankeinheit in Apache Spark, die eine unveränderliche Sammlung von Daten ist, die parallel über mehrere Knoten in einem Cluster geteilt werden.
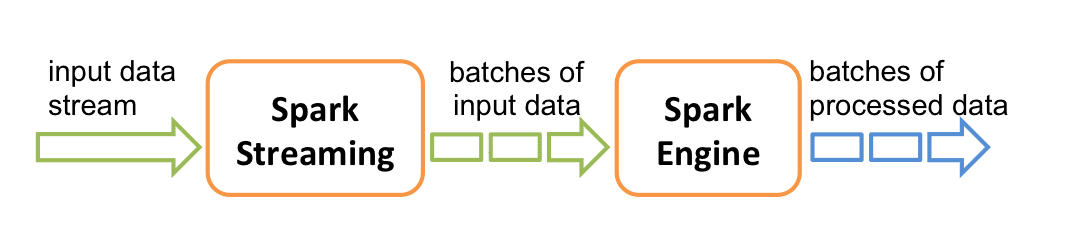
Was sind DStreams in Spark Streaming ?
Spark Streaming bietet eine High-Level-Abstraktion namens „diskretisierter Stream“ (Discretized Stream) oder DStream, die einen kontinuierlichen Datenstrom darstellen. Sie können als kontinuierliche RDDs betrachtet werden, wobei jeder RDD die in einem definierten Intervall erzeugten Daten darstellt.
DStreams können aus Eingabeströmen von Quellen wie Kafka, Twitter oder Flume oder durch Anwendung von High-Level-Operationen auf andere DStreams erstellt werden und können verwendet werden, um verschiedene Operationen wie Filtern, Aggregieren, Joinen usw. auszuführen, um die resultierenden Daten in Echtzeit zu produzieren

Nehmen wir ein Beispiel:
Angenommen, du arbeitest für ein öffentliches Verkehrsunternehmen, das in Echtzeit überwachen möchte, welche Fahrgäste in die Busse ein- und aussteigen. Zu diesem Zweck sind die Busse mit Sensoren ausgestattet, die kontinuierlich Informationen an die Server des Unternehmens senden.
Spark Streaming wird es uns ermöglichen, einen DStream zu verwenden, um diese Echtzeitdaten zu verarbeiten, wobei jeder DStream die Daten repräsentiert, die von den Sensoren der Busse in vordefinierten Zeitintervallen gesendet werden. Wir werden Operationen auf diesen DStreams verwenden, um unsere Analysen in Echtzeit durchzuführen. Mithilfe von Aggregationen können wir die Gesamtzahl der Fahrgäste in den Bussen zu jedem Zeitpunkt erhalten. Wir können auch Filter verwenden, um Busse zu identifizieren, die ihre maximale Kapazität erreicht haben, und so Warnungen für die Sicherheit der Fahrgäste aussenden.
Alles in allem können wir mit Spark Streaming Echtzeitanalysen der von den Sensoren gesendeten Daten durchführen und die Ergebnisse nutzen, um die Sicherheit und Effizienz des öffentlichen Nahverkehrssystems zu verbessern.
Was ist mit Fehlertoleranz und Replikation?
Spark Streaming gewährleistet Fehlertoleranz durch Techniken zur Datenreplikation und zur Übernahme von Aufgaben.
- Bei der Datenreplikation werden die Daten auf mehreren Knoten dupliziert, um ihre Verfügbarkeit zu gewährleisten, wenn ein Knoten ausfällt. Diese Maßnahme sorgt auch für die Robustheit des Systems, indem sichergestellt wird, dass die Daten nicht verloren gehen.
- Task Recovery hingegen ist ein Mechanismus, bei dem Tasks bei einem Ausfall auf anderen Knoten neu gestartet werden, damit die Daten auch bei Problemen weiter verarbeitet werden können.

Fazit
Spark Streaming ermöglicht es, Big-Data-Probleme in Echtzeit zu lösen. Die Tatsache, dass Spark Streaming verschiedene Datenquellen unterstützt und es ermöglicht, nur ein Framework für so unterschiedliche Anforderungen zu verwenden, ist ein großer Vorteil.







