AWS Glue is a fully managed, scalable data processing service that enables users to run serverless ETL (Extract, Transform, Load) workflows, freeing them from the need to manage the underlying infrastructure.
A reminder about ETL processes
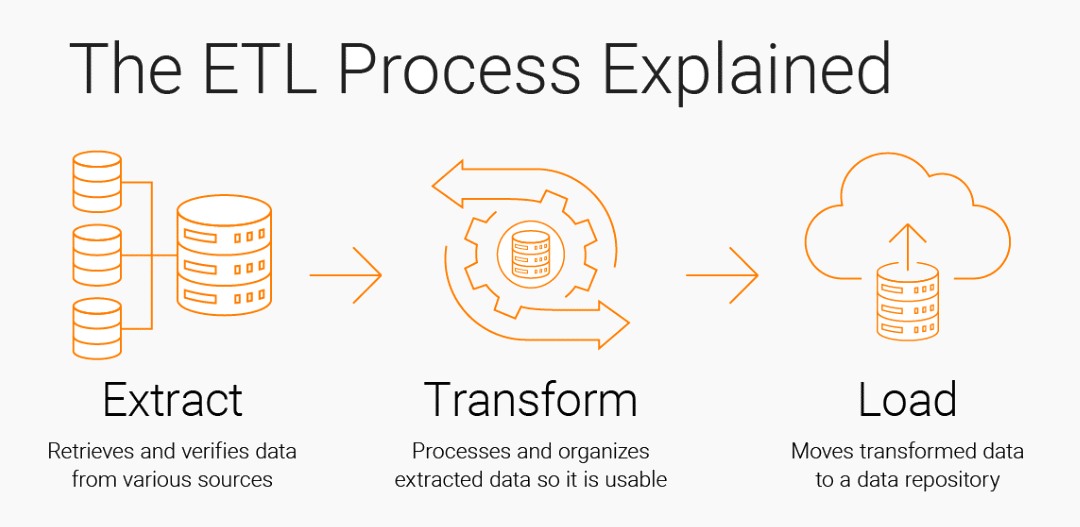
ETL is a process designed to guarantee data quality and availability. It is divided into 3 phases:
Loading: loading transformed data into a final environment, such as a database or data warehouse.
Source : Informatica.com
How is AWS Glue structured?
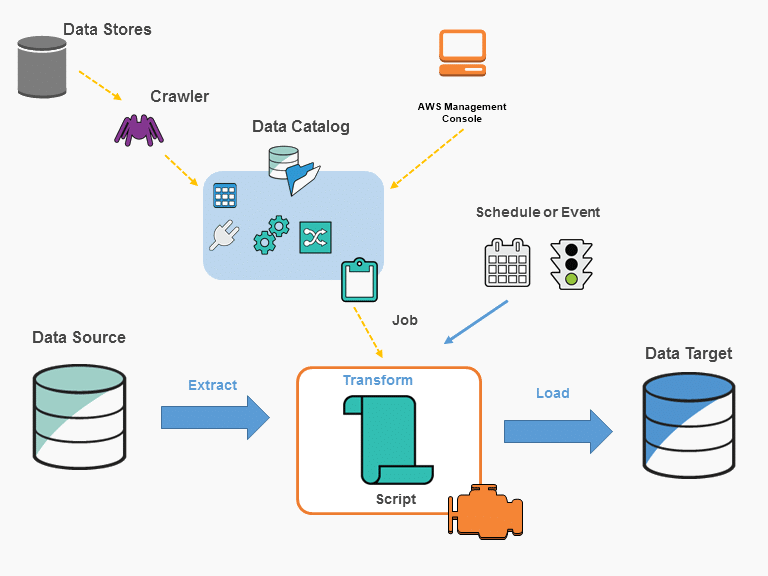
AWS Glue jobs perform the necessary extraction, transformation and loading of data from a source to a destination. The following diagram shows the architecture of AWS Glue, and then we describe the various elements:
Data Catalog: this is the permanent metadata storage in AWS Glue. It contains table definitions, job definitions, etc.
Database: a set of table definitions for associated data catalogs.
Crawler: a program that connects to a data source to extract its data and determine its structure. It then uses this information to create table definitions in the data catalog.
Connection: this AWS Glue connection is the data catalog that contains the information needed to connect to a certain data store.
Classifier: determines the data schema. AWS Glue provides classifiers for the most common file types, such as CSV, Json, etc.
Data store: repository for persistent data storage.
Data source: this is the entry point used for the transformation process.
Data target: the target to which the transformed data will be written.
Job: the business logic required for ETL jobs, made up of the various elements required.
AWS Glue allows you to fully manage your ETL processes through a variety of features, the most important of which are listed below:
Data Collection and Integration
AWS Glue allows for the collection and integration of data from various sources, including databases, flat files, streaming data, etc.
Data Transformation
Provides a set of tools for transforming data, including data processing functions, filtering, sorting, joining, and more.
Data Catalog
Allows for the creation and management of a metadata catalog that facilitates data discovery, search, and analysis.
ETL Task Execution and Scheduling
AWS Glue enables the scheduling and execution of ETL tasks to process data at scale.
Workflow Automation
Offers workflow automation features to orchestrate complex tasks involving multiple steps.
Custom Jobs
Enables the creation of custom jobs to address specific use cases. Custom jobs can be created using common programming languages such as Python and Scala.
Error Handling
Allows for the management of errors encountered during data processing, such as syntax errors or connectivity issues.
Monitoring
AWS Glue provides monitoring features to track ETL job performance, detect errors and performance issues, and optimize resource utilization.
Advantages and disadvantages of AWS Glue
Before embarking on using and learning AWS Glue, it’s important to consider both its advantages and disadvantages:
Advantages
Disadvantages
Large-scale data management
High costs for small businesses or small-scale projects, despite being a fully managed service
Fast data processing
Steep learning curve
Integration with other AWS services
Limited workflow customizations
Support for multiple programming languages
Requires expertise in data engineering
Fully managed platform
Built-in metadata catalog
Conclusion
As you’ve probably gathered by now, AWS Glue is a fully managed Amazon AWS ETL workflow service. Its great power and flexibility nevertheless require a steep learning curve and a very substantial investment in order to set it up to meet the required needs.