
Apache Pig is the programming language for Hadoop and MapReduce. Find out all you need to know: presentation, use cases, benefits, training...
The MapReduce programming model of the Apache Hadoop framework makes it possible to process large volumes of Big Data. However, Data Analysts are not always familiar with this paradigm. This is why an abstraction called Pig has been added to Hadoop.
What is Apache Pig?
The Apache Pig high-level programming language is very useful for analyzing large datasets. It was originally developed internally by Yahoo! in 2006, with the aim of creating and executing MapReduce jobs on all datasets.
The name “Pig” was chosen, as this programming language is designed to work on any type of data, like a pig that devours anything and everything.
In 2007, Pig was made open source through the Apache Incubator. In 2008, the first version of Apache Pig was launched. It was a great success, and Pig became a top-level Apache project in 2010.
By using Apache Pig, data analysts can spend less time writing MapReduce programs. This means they can stay focused on analyzing datasets.
In this way, Apache Pig is an abstraction for MapReduce. This tool is used to analyze large datasets by representing them as data streams. All data manipulation operations on Hadoop can be performed using Apache Pig.
Apache Pig architecture
The Apache Pig architecture is based on two main components: the Pig Latin language and the runtime environment for executing PigLatin programs.
The Pig Latin language is used to write data analysis programs. It provides various operators that programmers can use to develop their own functions for reading, writing or processing data.
A Pig Latin program consists of a series of transformations or operations, applied to “input” data to produce an “output”. These operations describe a data flow translated into an executable representation by the Pig Hadoop runtime environment.
To analyze data using Apache Pig, programmers must write scripts using the Pig Latin language. All these scripts are internally converted into Map and Reduce tasks. The Pig Engine component takes care of converting the scripts into MapReduce jobs.
However, the programmer is not even aware of these jobs. In this way, Pig enables programmers to concentrate on the data rather than on the nature of the execution.
Pig has two different execution modes. Local mode runs on a single JVM and uses the local file system. This mode is suitable for analyzing small datasets.
In Map Reduce mode, queries written in Pig Latin are translated into MapReduce jobs and executed on a Hadoop cluster. The cluster can be partially or fully distributed. MapReduce mode combined with a fully distributed cluster is useful for running Pig on large datasets.
Why use Apache Pig?
In the past, non-Java programmers found it difficult to use Hadoop. It was particularly tricky for them to perform MapReduce tasks.
This problem has been solved thanks to Apache Pig. Using the Pig Latin language, programmers can easily perform MapReduce tasks without having to type complex code in Java.
What’s more, Apache Pig is based on a “multi-request” approach that reduces code length. An operation that would require 200 lines of code in Java can be reduced to just 10 with Pig. On average, Apache Pig divides development time by 16.
An advantage of the Pig Latin language is that it is relatively close to the SQL language. A person accustomed to SQL will easily master Pig.
Last but not least, numerous operators are provided natively. These support a wide range of data operations. The tool also offers data types such as tuples, bags and maps, which are missing from MapReduce.
Apache Pig applications
Typically, Apache Pig is used by data scientists for tasks involving Hadoop processing and rapid prototyping. In particular, it is used to process huge data sources such as web logs.
It can also be used to process data for research platforms. Finally, it can handle time-sensitive data loads.
Features and benefits of Apache Pig
Here are the main features and functions of Apache Pig. The Pïg Latin programming language, similar to SQL, makes Pig scripting easy.
An extensive set of operators enables a wide variety of data operations to be performed. Based on these operators, users can develop their own functions for reading, processing and writing data.
It is also possible to create UDFs (user-defined functions) in other programming languages such as Java. These can then be invoked or integrated into Pig scripts.
What’s more, Apache Pig tasks automatically optimize their execution. Programmers can therefore focus solely on the semantics of the language.
Apache Pig can analyze all types of data, structured or unstructured. Analysis results are stored in the Apache Hadoop HDFS.

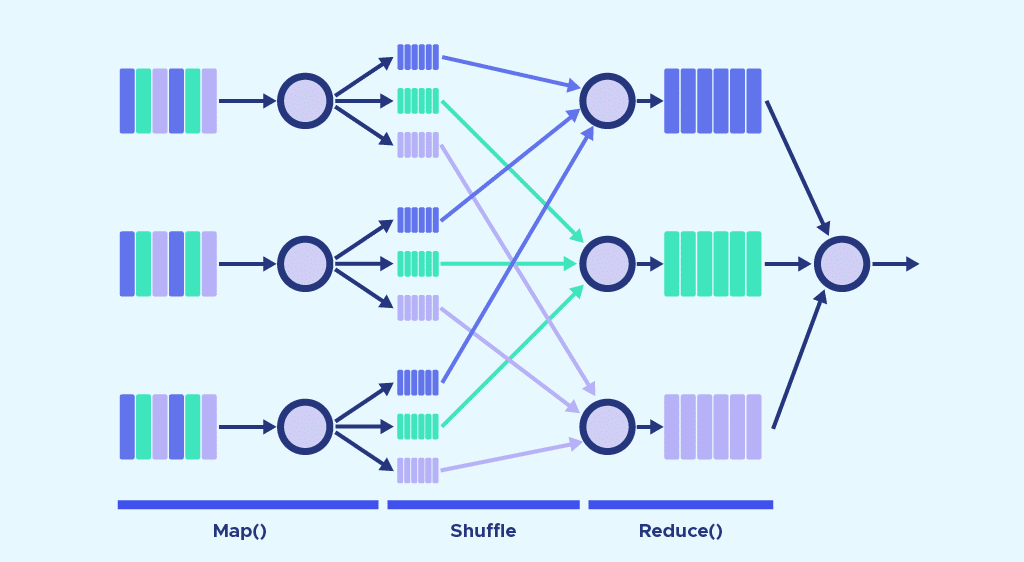
Apache Pig vs MapReduce
There are several major differences between Apache Pig and MapReduce. First of all, MapReduce is a data processing paradigm, whereas Pig is a data flow language.
It’s a high-level language, whereas MapReduce is low-level. It’s difficult to perform a Joint operation between datasets with MapReduce, whereas it’s an easy task with Pig.
Any programmer with notions of SQL can work with Apache Pig, whereas MapReduce requires mastery of Java.
Another difference concerns the length of the lines of code. Thanks to its multi-request approach, Apache Pig requires 20 times fewer lines than MapReduce to perform the same task.
Finally, Mapreduce tasks involve a lengthy compilation process. With Pig, there’s no need for compilation, as each operator is internally converted into a MapReduce job at runtime.
Apache Pig vs SQL
Apache Pig has some similarities with SQL, but also some differences. Whereas Pig Latin is a procedural language, SQL is a declarative language.
In addition, a schema is mandatory in SQL, whereas it is optional with Pig. It’s possible to store data without designing a schema.
There are more opportunities for query optimization with SQL, whereas they are more limited with Pig. On the other hand, Pig Latin lets you break down a pipeline, store data anywhere in the pipeline and perform ETL (Extract, Transform, Load) functions.
Apache Pig vs Hive

Apache Pig was created by Yahoo, and Hive by Facebook. The former uses the Pig Latin language, the latter the HiveQL language.
Pig Latin is a data flow and procedural language. HiveQL is a query processing and declarative language.
Finally, Hive mainly supports structured data. Pig, on the other hand, can handle structured, unstructured and semi-structured data.
How do I learn to use Apache Pig?
As more and more companies use Big Data, mastery of Apache Pig is a highly sought-after skill. It’s invaluable for easily processing and analyzing large datasets with Hadoop.
The Apache Hadoop framework, and its various components such as Pig, Hive, Spark and HBase are on the program of the Big Data Volume module of the Data Engineer training course.
The other modules in this course are programming, databases, automation and deployment. On completion of this course, you’ll have all the skills you need to work as a data engineer.
All our courses are available as continuing education courses or bootcamp courses. Our innovative “Blended Learning” approach combines face-to-face and online distance learning.
Learners receive a Sorbonne University-certified diploma, and 93% of alumni find immediate employment. Don’t wait any longer and discover our Data Engineer training.








