
The use of Deep Learning models is becoming increasingly necessary for businesses. However, its implementation represents a challenge in terms of creating a model that adapts well to needs, while remaining efficient and resource-saving. Hence the need to endow AI with deeper understanding and greater autonomy.
This article explains all about the emerging revolution freeing developers from the tedious tasks of manual design and optimization. The article highlights the challenges, how it works and the potential applications in various fields, pointing to a fascinating future for self-learning AI.
Where does LLM come from?
Automatic Neural Architecture Search (NAS) was born out of the need to optimize the creation and parameterization of Machine Learning models. NAS attempts to answer the question: is it possible to create an algorithm capable of creating neural networks that perform better than those created and parameterized by hand?
The first papers on this subject date back to 2016. First Barret Zoph and Quoc V in their article Neural Architecture Search with Reinforcement Learning. And soon after, Bozen Baken, Otkrist Gupta, Nikhil Naik and Ramesh Raskar in their article Designing Neural Network Architectures using Reinforcement Learning.
Indeed, neural networks are often difficult to create when the problems to be solved become more complex: creation not only takes a lot of time, but also effort, mastery of the subject and many parameter adjustments. So, to better optimize these resources, NAS automates the creation of neural networks.
Understanding automatic neural architecture search
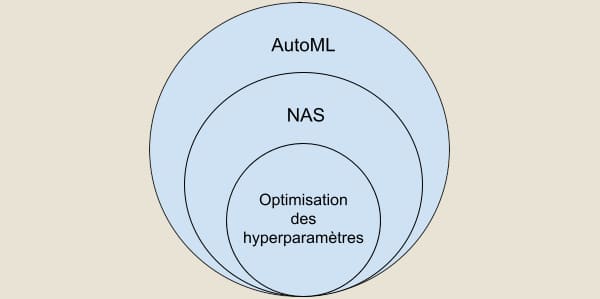
From the outset, automatic neural architecture search has been a sub-domain of AutoML or Automated Machine Learning; a field responsible for automating the tedious and iterative tasks involved in developing Machine Learning models. Hyperparameter optimization is a subfield of SIN.
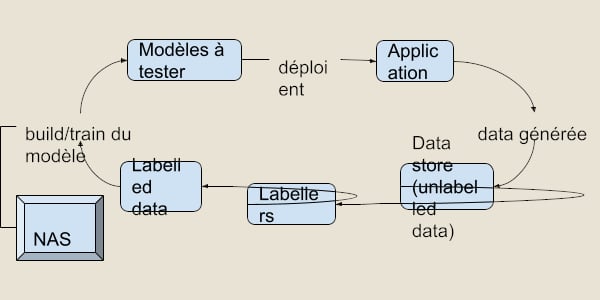
One question naturally arises after defining the role of SINs: where exactly are they involved in the model development process? Well, automatic neural architecture search takes place in the train part of the workflow: as the name suggests, we’re looking for the optimal neural network architecture.
AI that creates AI
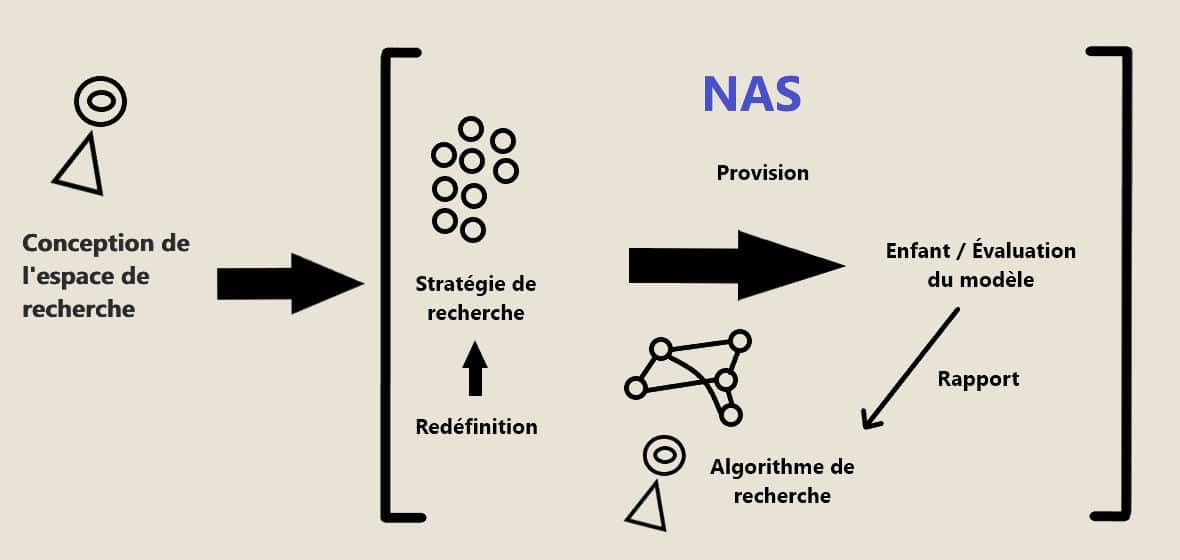
Automatic neural architecture search has four main axes or building blocks which it uses when creating a neural network:
- The search space: this is the set of candidate architectures from which to choose, together with the operators that make them up.
- The search strategy: guides the way the search is carried out. It samples from the proposed architectures without building or training the model, so that we can have an estimate of the model’s theoretical performance.
- The search algorithm: it receives the estimated performance and optimizes the parameters to obtain the best-performing candidates.
- Evaluation: models are created by NAS and evaluated and compared.
To better understand the interaction between these axes, consider the following diagram.
The different types of approach
Reinforcement learning
The very first approaches used reinforcement learning. In this type of approach, the search space is considered as an environment in which to evolve, and to which a reward is attributed, calculated according to the performance evaluation method of the architecture created.
However, this method has a number of disadvantages: in particular, the resources required to obtain a sufficiently high-performance architecture – thousands of GPU-hours are needed to do so.
💡Related articles:
| Image Processing |
| Deep Learning – All you need to know |
| Mushroom Recognition |
| Tensor Flow – Google’s ML |
| Dive into ML |
| Data Poisoning |
Gradient descent
Another way of searching for a differentiable neural architecture is to optimize a number of parameters via stochastic gradient descent.
In this case, the parameters, also known as weights (continuous variables denoted by 𝛼), represent the operations performed by the candidate architecture. Once the search is complete, the final model is built by sampling the operations making up the architecture taking into account the 𝛼 weights.
Sampling methods can vary, such as transforming 𝛼 into a probability distribution using a softmax function.
Additionally, computational resources and time can be further saved through the implementation of parameter sharing mechanisms so that the search space becomes partitioned into several cells that represent elementary components and from which a complete neural architecture can be built. The advantage of this mechanism is that it is no longer necessary to search for the entire architecture, if not just a few parts. As a result, differentiable methods take only a few tens of GPU-hours.
Genetic algorithms
In this case, we apply the Darwinist principle of genetic algorithms. Here, candidate architectures are considered as the set of individuals that can reproduce among themselves by mixing their operations (genes) in such a way as to produce new architectures. In this way, a starting population is progressively refined by allowing only the best individuals selected according to a given evaluation method to reproduce. Similar to reinforcement learning approaches, these methods are costly in terms of GPU-hours.

Applications
NAS is an expanding field, evolving at high speed and continuing to outpace hand-developed architectures. It’s also a field with a huge number of applications, to mention just a few:
- Image classification
- Object detection
- Natural language processing
- Time series processing
- Image, video and sound generation.
Advantages and limitations
An important limitation of SINs is the computational cost they can represent when trying to tackle complex topics with a large number of latent solutions. The larger the search space, the more options there will be to test, train and evaluate.
It’s also important to note that it’s difficult to predict the performance of a potential model when evaluating it in real data.
What’s more, the search space must always be defined by hand. On the other hand, mastery of the subject is no longer an impediment to efficient architecture.
However, these difficulties are disappearing with the advent of faster, more comprehensive methods for evaluating architectures. This means that automatic neural architecture search will soon be easily applicable to all companies, finding solutions according to their needs in a flexible and efficient way.
Conclusion
Automatic neural architecture search enables us to create new models from scratch that perform better than those created by hand, in a faster and more optimal way, while remaining flexible to possible modifications that we might wish to make by hand.








