Defining the right model is essential for making relevant predictions in Machine Learning. But poorly fitting training data can affect the performance of predictive analyses. This is precisely what happens with underfitting. So what is underfitting? And how can it be avoided? The answers are here.
What is underfitting?
Underfitting is a key concept in Machine Learning, since it can be responsible for poor performance in supervised learning from data. So before looking at this concept in more detail, it’s worth recalling a few essential elements of how Machine Learning works.
A reminder of how Machine Learning works
The aim of Machine Learning is to predict a pattern using learning models based on as yet unknown data.
To achieve this, supervised learning is based on two key ideas. These are
- Approximation: this involves training the training data (or training set) to obtain a model with the lowest possible error rate.
- Generalisation: following this training, data scientists use validation data to test the different models. This enables them to design a model that can be generalised to new, never-before-seen data.
The overall idea is to obtain similar levels of error in training and validation.

Underfitting or underlearning
Underfitting can be translated as underadjustment or underlearning. In this case, we also say that the model suffers from a large Bias.
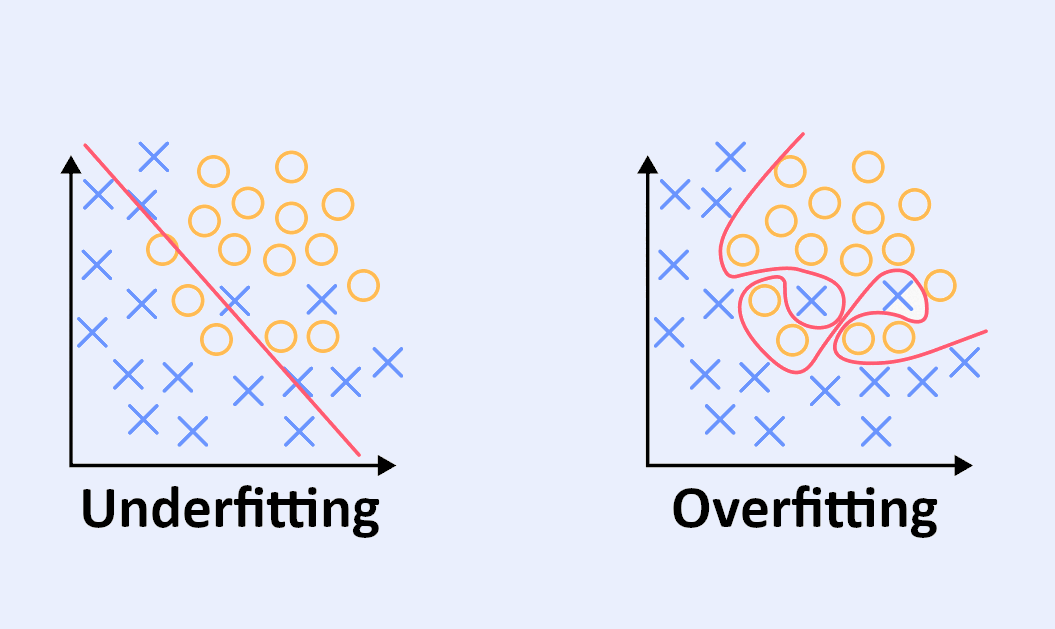
This occurs when only relevant variables are named in relation to the problem, or when the model is forced to stop learning prematurely. As a result, the model created is too simplistic and risks missing the general trend.
In fact, an under-tuned model adapts poorly to the training set. It will make biased predictions due to a lack of sufficient training, and will reveal a large number of errors during the learning phase.
In other words, it is a learning model that is too generalist and fails to provide accurate predictive analyses.
It is therefore vital to master this concept in Machine Learning before designing appropriate models. But before we look at how to avoid underfitting, we’ll also look at its opposite.
Overfitting, the opposite of underfitting
In contrast to underfitting, overfitting means over-adjusting or over-learning.
Here, we use as many variables as possible to be prepared for all hypotheses. But beware, there is a risk of using too many variables that are irrelevant to the study in hand.
While this method makes it possible to obtain similar levels of error in learning and validation, it makes the model much more complex. This implies an increase in the number of parameters to be estimated. As a result, the model will detect more spurious correlations.
The over-fitted model focuses on memorising the very specific characteristics of the data. It is said to adjust to the noise in the data.
Eventually, it will find causal links between unrelated data. It can then perform very well on training data, but to the detriment of the general trend.
How can I avoid underfitting?
The challenge for Data Scientists is to design the right model, neither too simple nor too complex. In other words, avoiding underfitting, without falling into overfitting.
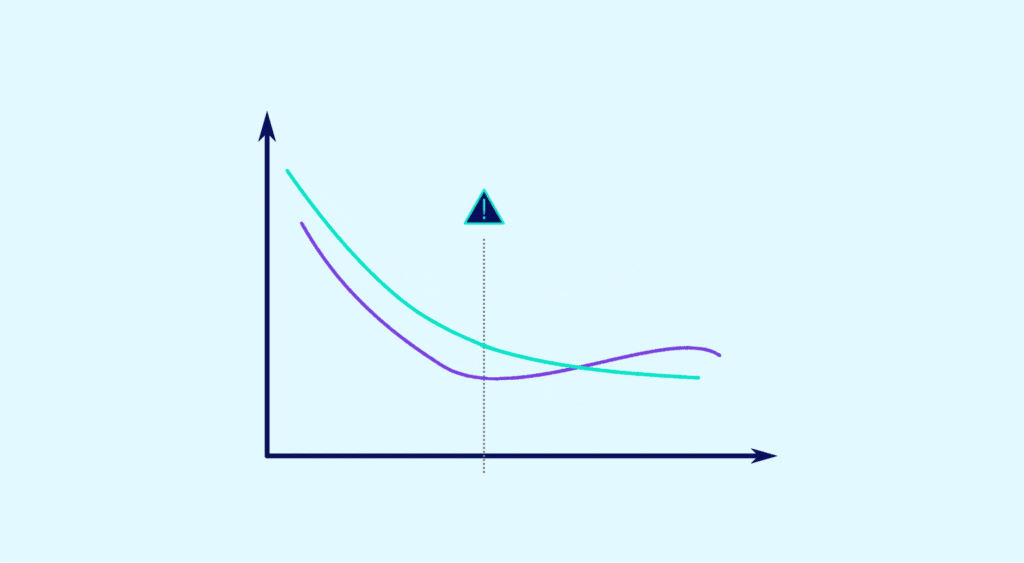
To do this, you need to identify the sweet spot that will enable you to strike the right balance. But first you need to learn how to detect underfitting and overfitting.
If the test data has a low error rate, but the training data has a high error rate, there is probably underfitting.
In this case, be careful not to make the model too complex. Here, the opposite situation will occur: training data with a low error rate and test data with a high error rate. Overfitting is typical.
Once you are able to identify one or the other, you can refine the predictive model during the learning phase. This gradually reduces the errors in the training set.
The data scientists must continue to refine the model until the errors increase in the validation phase. The equilibrium lies just before these errors increase at this stage.
By applying this method, you can detect the dominant trend and apply it widely to new data sets.
DataScientest for mastering Machine Learning models
Finding the right balance between underfitting and overfitting requires practice and increased knowledge of data analysis.
That’s precisely why DataScientest offers a range of Machine Learning training courses. Take a look at our programmes.








