
If you study data and want to derive information from it, you will often need to process the data, modify it and, above all, build models capable of learning patterns in your data for a chosen problem. There are a number of open source libraries available to do this, but the best-known of these is surely Scikit Learn.
What is Sckikit Learn ?
It’s a Python library that provides access to efficient implementations of many common algorithms. It also offers a clean and consistent API. Therefore, one of the big advantages of Scikit-Learn is that once you’ve understood the basic usage and syntax of Scikit-Learn for a type of model, transitioning to a new model or algorithm is very straightforward. The library not only enables modeling but can also handle preprocessing steps, as we will see in the rest of the article.
History and purpose
The project was initially launched in 2007 by David Cournapeau, and quickly, many members of the Python scientific community rallied around it. The project progressed rapidly as part of work on functional brain imaging conducted by Inria. In 2009, the first version of Scikit-Learn was released. Since then, no less than forty versions have been released, leading to the current version, 0.24.1. This number reflects the dedication and work put into the project by developers around the world, with each version improving or adding innovative new statistical methods.
From the beginning, the goal was ambitious: to make the library easy to use on multiple platforms and to provide comprehensive documentation with concrete examples for each tool developed. Today, Scikit-Learn is one of the most popular libraries on GitHub. Due to the project’s initial goals, one of Scikit-Learn’s strengths is its flexibility and the ease with which you can use it for a wide range of tasks, such as customer segmentation, product recommendations, fraud detection, and more.
Lastly, it’s important to note that Scikit-Learn is an open-source project available to everyone under the BSD license. On the library’s website, you will find very detailed documentation of the available statistical methods, along with examples for understanding them, as well as practical cases for comparing different methods and gaining a better understanding of them.
💡Related articles:
The Scikit learn API
It has been built based on certain principles to make it easily applicable to a wide range of domains:
- Consistency: All objects share a common interface derived from a limited set of methods, with consistent documentation.
- Inspection: All specified parameter values are exposed as public attributes.
- Limited object hierarchy: Only algorithms are represented by Python classes; datasets are represented in standard formats (NumPy arrays, Pandas DataFrames, SciPy sparse matrices), and parameter names use standard Python strings.
- Composition: Many machine learning tasks can be expressed as sequences of more fundamental algorithms, and Scikit-Learn makes use of this whenever possible.
- Reasonable default values: When models require user-specified parameters, the library defines appropriate default values. These principles are directly described in the paper outlining Scikit-Learn’s API principles.
In practice, these five principles make it easy and seamless to use the library, even for individuals without a strong mathematical background.
Scikit Learn Basics
Because the API is standardized, whatever model you plan to use, the modeling steps are often the same:
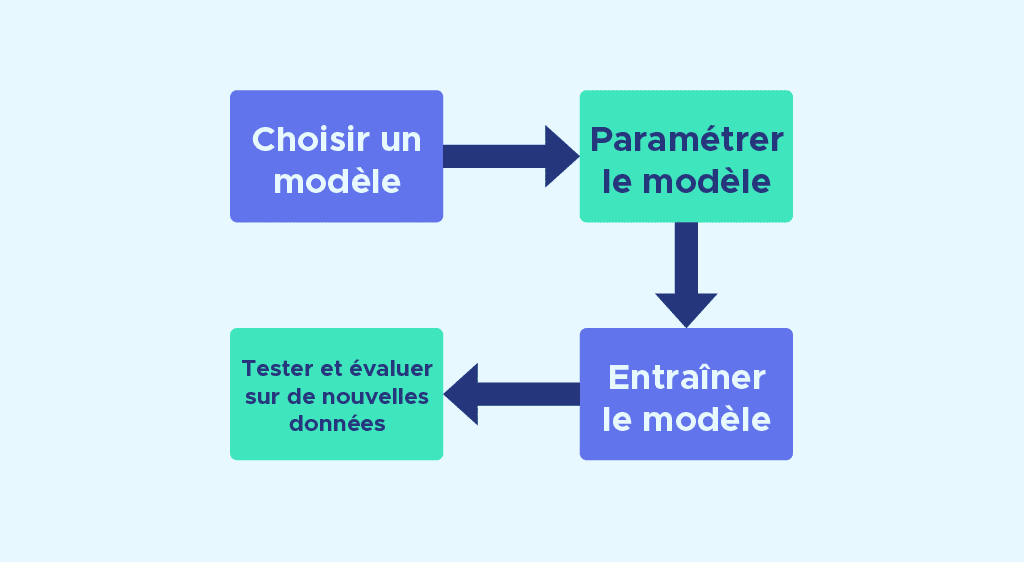
Choosing a model by importing the appropriate class from Scikit-Learn.
Configuring the model. If you are already sure about the parameters you want to use, you can manually set them. Otherwise, the library also offers techniques like GridSearchCV to find optimal parameters.
Training the model on the training dataset using the fit method.
Testing the model on new data:
– In supervised learning, we use the predict method on the test data.
– In unsupervised learning, we use the transform or predict methods.
These four steps are generally common to using a large number of models available in the library, which means that once you understand the logic of constructing a model, you can easily use other models.
Scikit-Learn: a wealth of possibilities
In a previous article, we discussed the 5 crucial steps of a data project:
1. Grasping the ins and outs.
2. Retrieving and exploring the data.
3. Preparing your working databases.
4. Selecting and training a model.
5. Evaluating your results.
In the last 3 steps, Scikit-Learn is a widely used library that provides you with all the necessary tools:
To prepare your data, the library offers an array of methods for:
- Splitting your data into training and testing sets using the `train_test_split` function.
- Encoding categorical variables with methods like `OneHotEncoder`.
- Normalizing the data before modeling using methods like `StandardScaler`.
- Handling missing values with simple imputation methods like `SimpleImputer` or more advanced methods like `IterativeImputer`.
- Conducting variable selection with methods like `SelectKBest`.
- Reducing dimensionality using methods like PCA or TSNE.
All these methods allow you to prepare the data effectively, a crucial step in a project, and Scikit-Learn provides all the necessary tools to succeed. We’ve mentioned just a small part of the available methods; you can find many more on the [Scikit-Learn website].
Supervised and unsupervised learning on Scikit-Learn
Scikit-Learn covers two major types of learning for selecting and training models:
1. Supervised Learning: Scikit-Learn provides a wide range of models such as logistic regression, linear regression, penalized linear regressions like Ridge, Lasso, or Elastic Net, decision trees, ensemble methods like random forests, and boosting methods. These models can be easily used for both classification and regression problems.
2. Unsupervised Learning: In this category, Scikit-Learn offers algorithms like k-means, hierarchical clustering, DBSCAN, Gaussian mixture models, and more, making it easy to work on unsupervised learning tasks.
For most of these models, especially in supervised learning, we don’t know in advance which parameters will yield the best performance. Therefore, Scikit Learn provides tools like GridSearchCV and RandomizedSearchCV, which use cross-validation to determine the best parameters for our models. These two functions are widely used in the data science community when modeling data.
The wide variety of models available in a single library makes Scikit Learn a must-have for the modeling phase of data projects.
When it comes to evaluating results, Scikit Learn excels as well. It offers no less than 40 readily available metrics for evaluating model results. Some, like RMSE, MAE, MSE, and r2_score, are used to assess and compare regression model results.
Others, like confusion_matrix, accuracy_score, classification_report, are used for classification models. Additionally, metrics like silhouette_score help evaluate the performance of partitioning algorithms such as hierarchical clustering.
It’s also important to mention that Scikit-Learn, thanks to a method called the pipeline, allows you to instantiate the last three stages of a data project in very few lines of code.
Of course, this tool is used after testing different models and determining the best one for your problem.
A little practice
Let’s look at a concrete example to understand Scikit-Learn’s ability to provide statistical tools for a data project with minimal lines of code.
In this example, we will use the Boston house-prices dataset provided by the library. This dataset does not contain missing values, and our goal will be to test three different models, find the optimal parameters for each, and compare the scores obtained to determine the best one.
Git code example :
The code can be broken down into 4 steps:
- Data import and scaling using the StandardScaler class.
- Variable selection using the SelectKBest class.
- Training of 3 different models and search for the best parameters using the GridSearchCV class.
- Compare and select the optimal model.
A final step consists of instantiating all these steps in a single line of code with the best model using the Pipeline class, and predicting and evaluating on the test set.
The Scikit Learn library today provides a very large number of algorithms with fields of application in many sectors such as industry, insurance, understanding customer data… At Datascientest we will teach you to use, understand, interpret and evaluate a large number of algorithms from the library on concrete problems. Find out more about our training courses.








