
Optical Character Recognition (OCR), also known as ocherecognition, encompasses all the methods used to generate text files from images containing handwritten text. With the advent of digital technology and automation, OCR has become an indispensable tool, as images containing text cannot be processed by a computer.
1. A little history
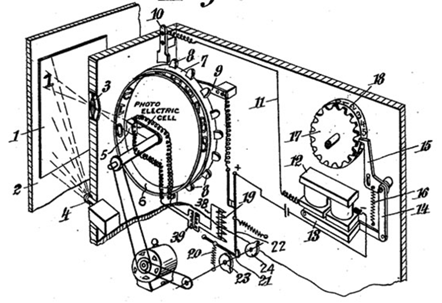
The first version of a machine capable of recognizing characters in a handwritten document was developed by German engineer Gustav Tauschek in 1929. The principle was as follows. A document containing handwritten text was placed in front of the machine’s window.
Then, to detect the correct character, a wheel with letter-shaped holes rotated until a photodetector ensured that the image of the character and the hole coincided perfectly. Once the character had been detected, it was written on a sheet of paper.
2. Using Deep Learning for OCR
It’s easy to see that scanning with mechanical machines, however powerful, can be very costly and time-consuming. Companies wishing to automate their digitization pipeline need a fast, efficient handwriting recognition tool. Thanks to the development of Deep Learning, particularly in the field of image processing, there are now algorithms capable of solving OCR problems. The OCR model can be broken down into 2 stages: text detection and recognition.
The first is the process of detecting text zones in a document, which can be a very complicated task, as documents can have very different structures. Text zones will not be in the same place between a novel and a newspaper, for example.
The second is to recognize text for a zone of the document containing it.
3. Text detection using Deep Learning
There are several methods for detecting text within a document. Some are inspired by object detection models (Single Shot Box Detection, Faster-RCNN) used to detect faces, cars, etc. in an image. This type of model returns a Bounding Box, which is simply a frame surrounding the object to be detected. To detect text, these models are modified and adapted.
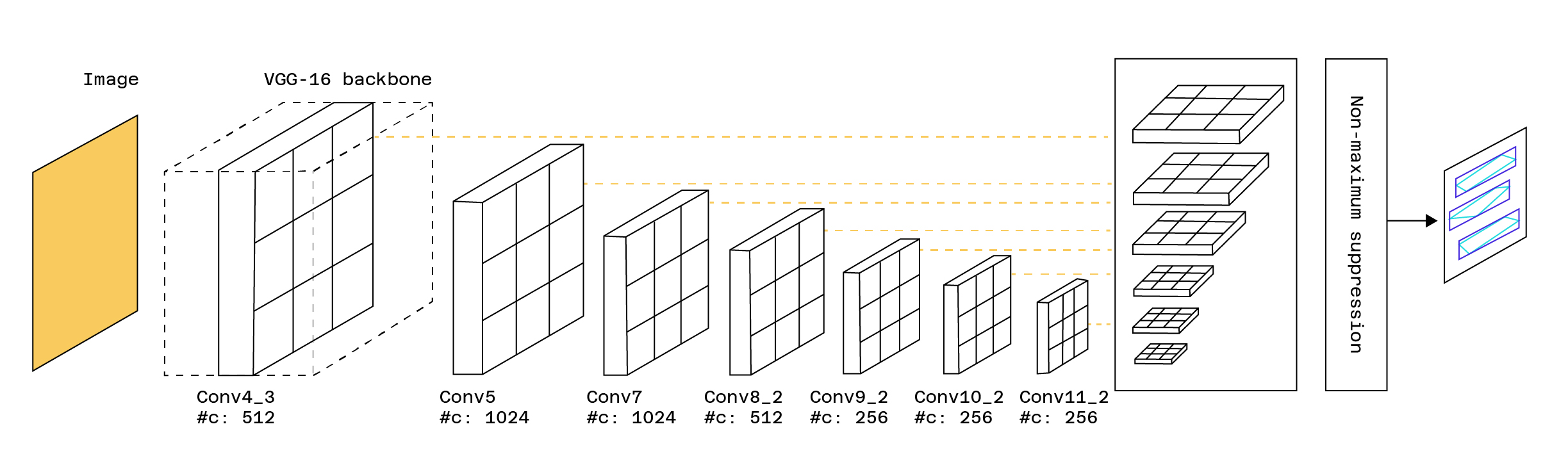
One example is the TextBoxes model, which is based on the SSD (Single Short Detector) model, but adds Bounding Boxes that are more specific to text detection. The template returns image areas containing text.
There are also other detection methods based on segmentation. Segmentation is a process that breaks down an image into a number of zones, called classes, containing similar elements. Here’s an example:

Convolutional neural networks (CNNs) and pyramidal neural networks (PNNs) are often used for text segmentation. Here’s the architecture of a high-performance model called TextSnake.
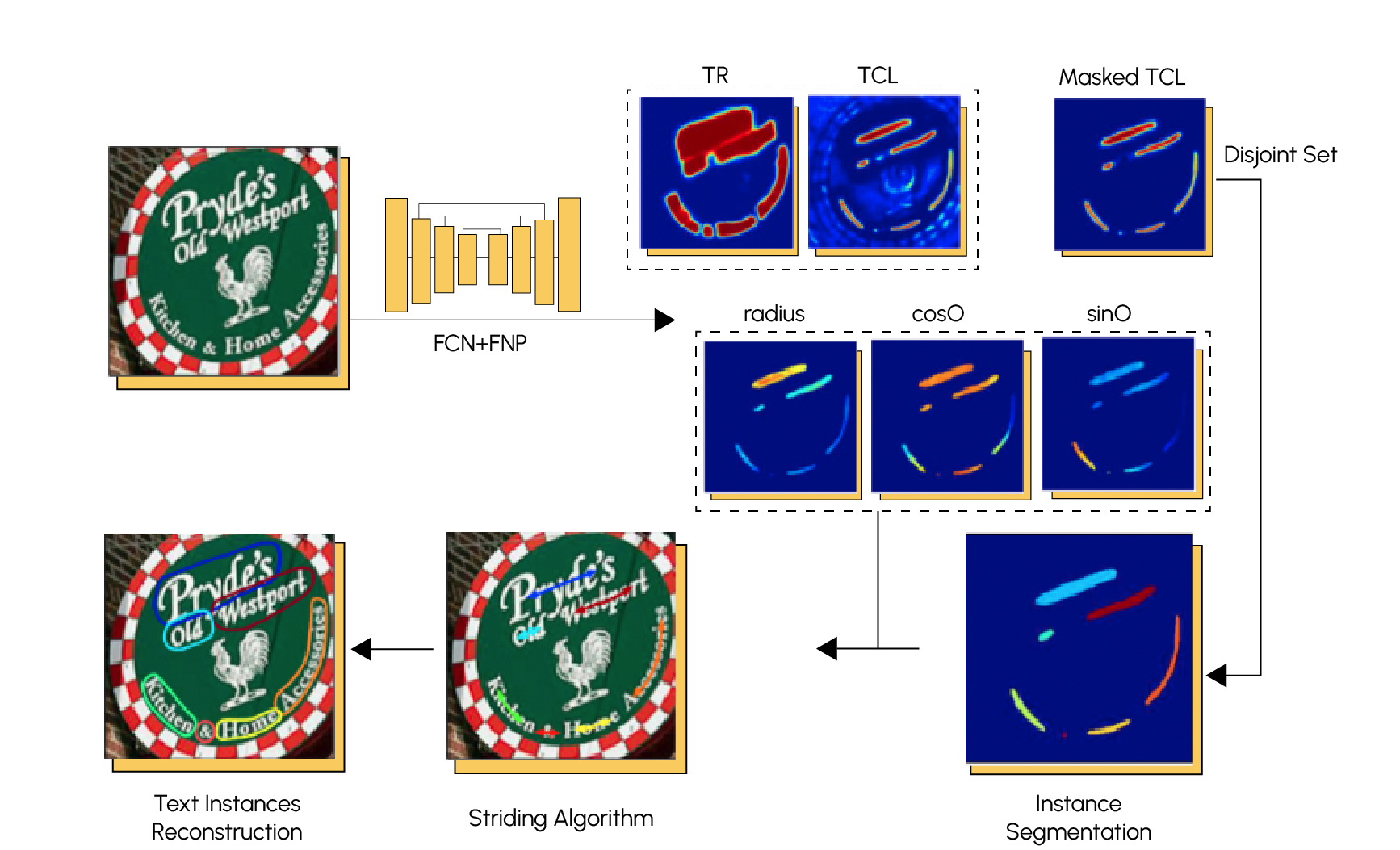
4. Text recognition using Deep Learning
We have just seen the first stage of an occlusion model, which is the detection of areas of the document containing text. Once this has been achieved, the next step is to recognize the characters that make up these areas, in order to deduce words and thus translate the handwritten document into a usable text format.
The Machine Learning models most commonly used to solve text recognition problems are recurrent neural networks. Their advantage is that the hidden layers that make them up share a common memory band, which means that prediction is influenced by previous predictions. If you’d like to find out more about how they work, a full article on recurrent neural networks is available on our blog.
The most commonly used layers for recurrent neural network models are LSTMs and GRUs. We add convolutional layers to these recurrent layers. Convolution is used to extract relevant, local features from images containing text, and recurrent layers are used to assign labels corresponding to the characters present in the image. For each feature created by convolution, a probability vector is associated with each label.
Text recognition can be summarized as follows:
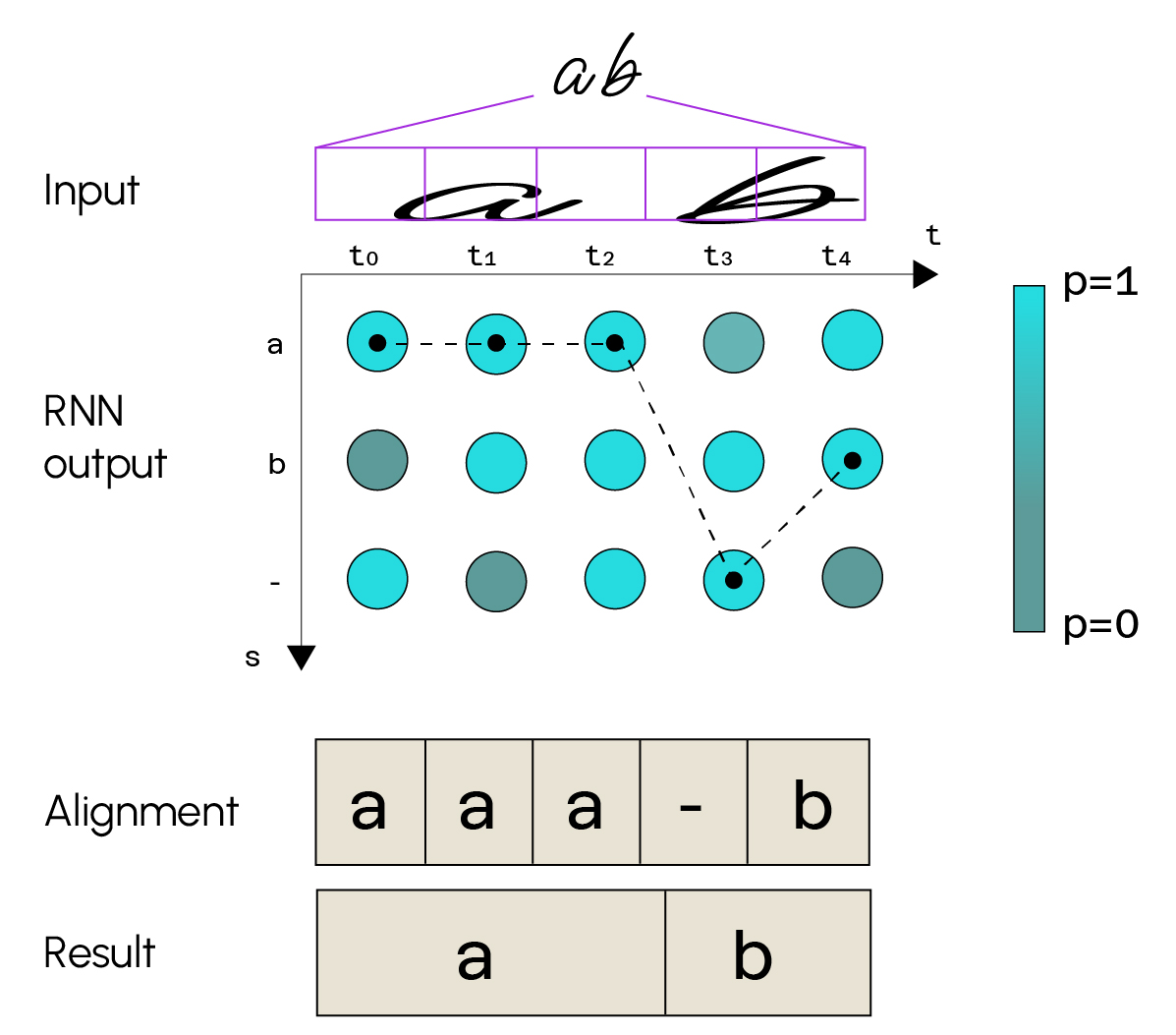
Don’t forget that there must be a text detection part upstream for the recognition part to work correctly.
In this example, we can see that the input image represents the text “a b”. The
convolution part will decompose the image into a feature map. Here we can see that the image has been split into 5 sequences. The recurrent layers then associate a class probability with each sequence. There are as many classes as possible characters (letters of the alphabet, special characters, etc.). For each sequence, we choose the class that maximizes the probability, obtain a sequence of characters and then deduce our final text.
However, this model does not allow us to check that the word or sentence returned in output is without spelling mistakes, as we predict character by character without worrying about this. There are other models that implement a spelling correction system. This approach is called a language model, and can improve the accuracy of our model.
5. Conclusion
We’ve just seen a Deep Learning model for solving the occlusion problem. Deep Learning has really revolutionized this field, offering highly accurate predictions in contrast to models that had been developed previously. We can see that the model uses techniques normally used in other fields, such as object detection in an image or Natural Language Processing, and that these techniques work very well for occlusion.
If you enjoyed this article and would like to discover other Deep Learning methods, you are welcome to join our Deep Learning expert course.








