
The final part of our dossier dedicated to Deep Learning, this article will give you an in-depth look at how Transfer Learning is defined and how it works. If you'd like to come back to the first articles, here's the list:
Andrew Ng, Chief Scientist at Baidu and professor at Stanford, stated during his highly popular NIPS 2016 tutorial that transfer learning would be the next driver of commercial success in Machine Learning. And he’s not the only one praising the potential of Transfer Learning…
In this article, we will tell you everything about this concept that is gaining more and more attention. DataScientest will help you answer 3 fundamental questions:
1. What is Transfer Learning?
2. What strategies do Transfer Learning techniques rely on?
3. How are they concretely implemented to solve Deep Learning problems?
If you have any further questions or need more information, please don’t hesitate to ask.
Transfer Learning : Definition
Let’s start by defining this term that is increasingly used in Data Science.
Transfer Learning, or “apprentissage par transfert” in French, refers to the set of methods that allow transferring knowledge gained from solving specific problems to address another problem.
Transfer Learning has seen significant success with the rise of Deep Learning.
Often, models used in this field require high computational time and significant resources. However, by using pre-trained models as a starting point, Transfer Learning enables the rapid development of high-performing models and the effective resolution of complex problems in Computer Vision or Natural Language Processing (NLP).

Let’s start by defining this term that is increasingly used in Data Science.
Transfer Learning refers to the set of methods that allow transferring knowledge gained from solving specific problems to address another problem.
Transfer Learning has seen significant success with the rise of Deep Learning. Often, models used in this field require high computational time and significant resources. However, by using pre-trained models as a starting point, Transfer Learning enables the rapid development of high-performing models and the effective resolution of complex problems in Computer Vision or Natural Language Processing (NLP).
What strategies do Transfer Learning techniques rely on?
Transfer Learning is based on a simple idea: reusing knowledge gained in other settings (sources) to solve a specific problem (target). In this context, several approaches can be distinguished based on what one wants to transfer, when to perform the transfer, and how to do it. Overall, we can distinguish three types of Transfer Learning:
1. Inductive Transfer Learning
In this configuration, the source and target domains are the same (same data), but the source and target tasks are different but close. The idea then is to use existing models to advantageously reduce the scope of possible models (model bias), as illustrated in the figure below.

For example, it is possible to use a model trained to detect animals in images to build a model capable of identifying dogs.
2. Unsupervised Transfer Learning
As with inductive transfer learning, the source and target domains are similar, but the tasks are different. However, the data from both domains are not labeled.
It is often easier to obtain large quantities of unlabeled data, from databases and web sources for example, than labeled data.
This is why the idea of using unsupervised learning in combination with Transfer Learning is attracting a great deal of interest.
Self-taught clustering, for example, is an approach that enables the clustering of small collections of unlabeled target data, with the help of a large quantity of unlabeled source data. This approach outperforms traditional state-of-the-art approaches when the target data is irrelevantly labeled.
3. Transductive Transfer Learning
In this configuration, the source and target tasks are similar, but the corresponding domains are different either in terms of data or marginal probability distributions.
For example, NLP models such as those used for morpho-syntactic word tagging, Part-Of-Speech Tagger (POS Tagger), are generally trained and tested on news data such as the Wall Street Journal. They can be adapted to data from social networks, whose content is different but similar to that of newspapers.
How is Transfer Learning used in practice to solve Deep Learning problems?
Now that we’ve defined Transfer Learning, let’s look at its application to Deep Learning problems, a field in which it is currently enjoying great success.
The use of Transfer Learning methods in Deep Learning mainly consists in exploiting pre-trained neural networks.
In general, these models correspond to high-performance algorithms that have been developed and trained on large databases, and are now freely available.
In this context, we can distinguish 2 types of strategy:
1. Use of pre-trained models as feature extractors
The architecture of Deep Learning models often takes the form of a stack of layers of neurons. These layers learn different features depending on the level at which they are located. The last layer (usually a fully connected layer, in the case of supervised learning) is used to obtain the final output. The figure below illustrates the architecture of a Deep Learning model used for cat/dog detection. The deeper the layer, the more specific features can be extracted.

The idea is to reuse a pre-trained network without its final layer. This new network then functions as a fixed feature extractor for performing other tasks.
To illustrate this strategy, let’s consider a case where we want to create a model capable of identifying the species of a flower from its image. It is then possible to use the first layers of the AlexNet convolutional neural network model, initially trained on the ImageNet dataset for image classification.
While the idea may seem simple, one might wonder about the performance of such an approach. In practice, it works very well, as shown in the figure below.

2. Adjustment of pre-trained models
This is a more complex technique, in which not only the last layer is replaced to perform classification or regression, but other layers are also selectively re-trained. Indeed, deep neural networks are highly configurable architectures with various hyperparameters. What’s more, while the first layers capture generic features, the last layers focus more on the specific task at hand, as shown in the figure below.

The idea is to freeze (i.e., fix the weights of) certain layers during training and fine-tune the rest to address the specific problem.
This strategy allows for the reuse of knowledge in terms of the overall network architecture and leverages its weights as a starting point for training. It enables better performance with shorter training times.
The figure below summarizes the main Transfer Learning approaches commonly used in Deep Learning.
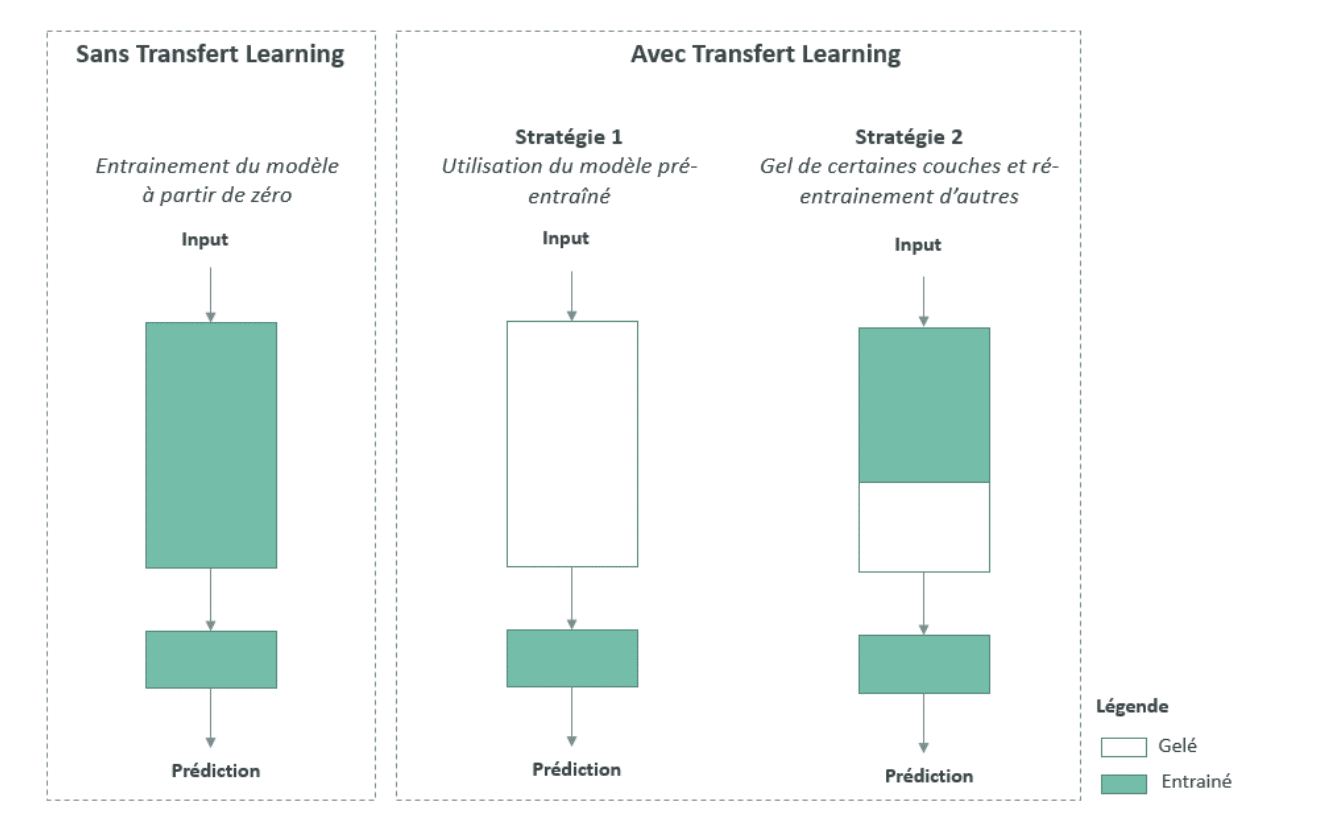
One of the fundamental requirements for Transfer Learning is the availability of models that perform well on source tasks. Fortunately, many state-of-the-art Deep Learning architectures are now freely shared by their respective teams. These models span various domains such as Computer Vision and Natural Language Processing (NLP), which are two very popular areas in Deep Learning.
Some frequently used models include:
Computer Vision: VGG-16, VGG-19, ResNet-50
NLP: Word2Vec, GloVe
Key points to remember
Transfer Learning is the ability to use existing knowledge developed to solve specific problems to address a new problem.
We’ve discussed several approaches to Transfer Learning. To choose the most suitable strategy, it’s important to consider the following three questions:
1. What do we want to transfer? This is the first and most crucial question. It aims to define which part of the knowledge should be transferred from the source to the target in order to address the target task’s problem.
2. When do we want to transfer? There can be scenarios where applying Transfer Learning methods may lead to a degradation of results. In reality, these performances depend on the similarity between the source and target domains and tasks.
3. How are we going to perform the transfer? Once we’ve answered the “what” and “when” questions, we can begin to identify the most appropriate Transfer Learning technique for the problem we want to solve.
Congratulations! You’ve completed our Deep Learning dossier! You now know the essentials about its successful applications, how neural networks work, CNNs and now Transfer Learning. Want to learn more about Deep Learning? Discover (and start soon) one of our specialized training courses.








