
Daniel is back, the iconic face of our training courses who guides our learners through to their diploma. Today he's going to introduce you to a model frequently used in Computer Vision: VGG.
We’ve previously had the opportunity, some time ago, to delve into the concept of Transfer Learning. If you missed our article on the topic, I encourage you to revisit it here. What’s important to keep in mind is that Transfer Learning corresponds to the ability to leverage existing knowledge, developed to address specific issues, to solve a new problem.
💡Also discover:
| Image Processing |
| Deep Learning – All you need to know |
| Mushroom Recognition |
| Tensor Flow – Google’s ML |
| Dive into ML |
| Data Poisoning |
A little history
VGG is a convolutional neural network developed by K. Simonyan and A. Zisserman from the University of Oxford. It gained prominence by winning the ILSVRC (ImageNet Large Scale Visual Recognition Challenge) competition in 2014. The model achieved an impressive accuracy of 92.7% on ImageNet, which is one of the highest scores achieved at the time.
It marked an advancement over previous models by introducing smaller convolutional kernels (3×3) in its convolutional layers, a departure from the norm. The training process for this model spanned several weeks and made use of cutting-edge graphics cards for computation.
ImageNet
ImageNet is an immense database containing over 14 million labeled images distributed across more than 1000 classes, as of 2014. In 2007, a researcher named Fei-Fei Li initiated the idea of creating such a dataset. While model design is undoubtedly crucial for achieving good performance, having high-quality data is equally essential for quality learning. The data was collected and labeled by humans from the web, making it open source and not owned by any particular company.
Since 2010, the ImageNet Large Scale Visual Recognition Challenge has been held annually. Its purpose is to challenge image processing models. The competition is conducted on a subset of ImageNet, consisting of 1.2 million training images, 50,000 validation images, and 150,000 images for testing the model’s performance.
The architecture
In practice, there are two available algorithms: VGG16 and VGG19. In this article, we will focus on the architecture of the first one, VGG16. While both architectures are very similar and follow the same principles, VGG19 has a larger number of convolutional layers.
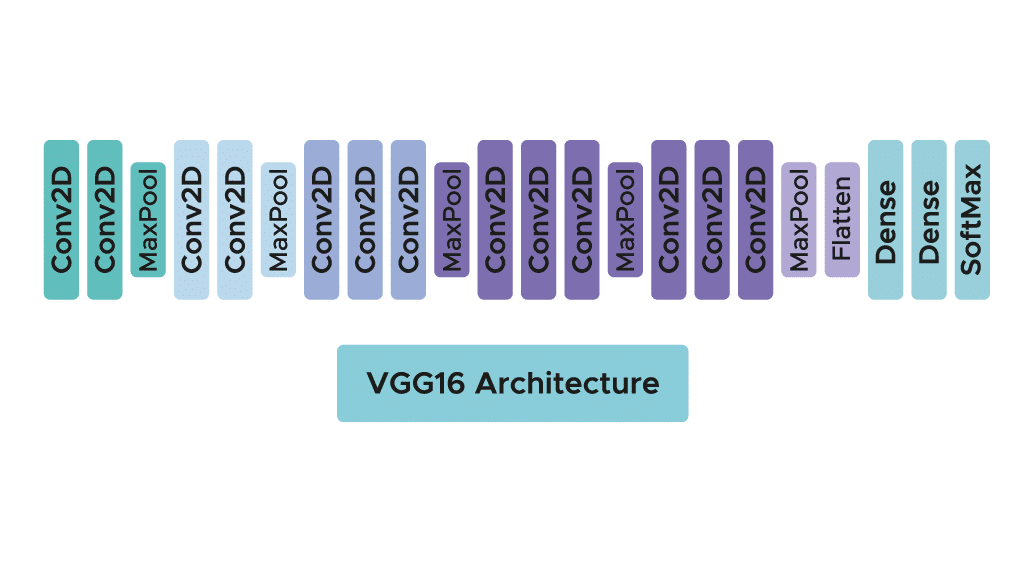
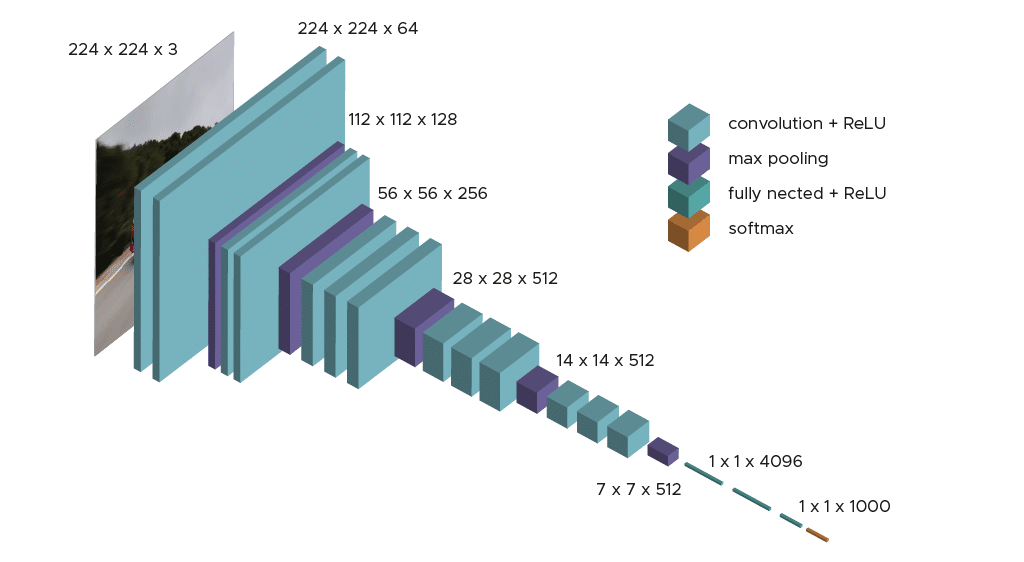
The model requires only one specific preprocessing step, which involves subtracting the mean RGB value calculated across the entire training set from each pixel.
During the training of the model, the input to the first convolutional layer is an RGB image of size 224 x 224. For all convolutional layers, the convolution kernel is of size 3×3 – the smallest dimension to capture concepts like top, bottom, left/right, and center.
This was a unique feature of the model at the time of its publication. Up until VGG16, many models leaned towards larger convolutional kernels (e.g., 11×11 or 5×5). It’s important to note that these convolutional layers aim to filter the image, retaining only discriminative information such as unusual geometric shapes.
These convolutional layers are accompanied by Max-Pooling layers, each of size 2×2, to reduce filter sizes during training.
Following the convolution and pooling layers, we have 3 Fully-Connected layers. The first two consist of 4096 neurons each, and the final layer consists of 1000 neurons with a softmax activation function to determine the image’s class.
As you’ve observed, the architecture is clear and straightforward to understand, which is one of the strengths of this model.
ImageNet results
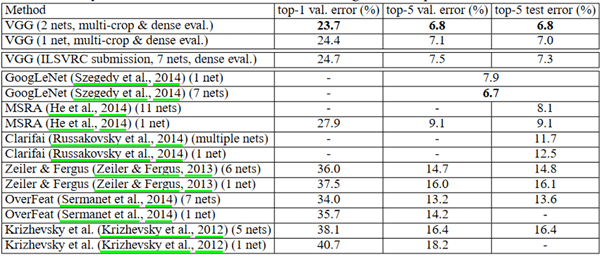
The figure above compares the results of various models from 2014 and previous years. We can observe that VGG achieves the best results on both the validation and test datasets. It’s worth noting that the model performs significantly better than in the 2012 and 2013 sessions.
And what about transfer learning?
As we’ve mentioned before, training a model like VGG can be very time-consuming, especially if you have limited resources. Furthermore, since it has been trained on ImageNet, it can be advantageous to retrieve the weights of the pre-trained model, particularly the filters in the convolutional layers learned from ImageNet. In practice, this is a common approach: we retrieve the weights from the convolutional layers, and we only need to train the 3 additional layers we add. The principle remains the same: using the knowledge gained from ImageNet to address a similar problem.
It’s notably possible to easily obtain the pre-trained model and apply the specific preprocessing requested by the model.
A little practice
In practice, there are two available algorithms: VGG16 and VGG19.
Thanks to the Keras library in TensorFlow, it’s straightforward to retrieve the pre-trained model, which by default, is trained on ImageNet.
First, we need to apply the same specific preprocessing as was done during the model’s training. Additionally, we incorporate data augmentation on the training data to prevent overfitting. It’s also crucial to ensure that the input images are RGB images with a size of 224×224.
We can then recover the optimized weights from the convolution layers and train the 3 Dense layers that we add and compile:
After training, if the results are not satisfactory, it’s possible to unfreeze the last convolutional layers and retrain them in an attempt to achieve better performance. However, this additional step can be time-consuming and resource-intensive, depending on the resources at your disposal. It’s a trade-off between potentially improving performance and the computational cost of retraining these layers.
Conclusion
VGG is a well-known algorithm in Computer Vision, often used for transfer learning to avoid the need for retraining and solve similar problems for which VGG has already been trained. There are many other algorithms of the same type as VGG, such as ResNet or even Xception, available in the Keras library.
If you’re interested in gaining expertise in Deep Learning and Computer Vision, consider joining us in a Bootcamp or continuous training program.








