Dank der Fortschritte im Bereich des Machine Learning und insbesondere des Deep Learning mit tiefen neuronalen Netzen sind Fehler seit den 2010er Jahren immer seltener geworden. Heute sind sie sogar sehr außergewöhnlich. Dennoch machen diese Modelle manchmal immer noch Fehler, ohne dass es Forschern und Forscherinnen gelingt, wirksame Abwehrsysteme zu entwickeln.
Adversarial Examples (dt. feindliche Beispiele) gehören zu diesen Inputs, die vom Modell falsch einordnen wird. Deshalb wurde eine Verteidigungstechnik entwickelt, die Adversarial Training oder feindliches Training genannt wird. Aber wie funktioniert diese Abwehrtechnik? Ist sie wirklich effektiv?
Was ist ein Adversarial Example?
Adversarial Training ist eine Technik, die entwickelt wurde, um Machine-Learning-Modelle vor Adversarial Examples zu schützen. Aber was sind Adversarial Examples denn? Es handeln sich dabei um sehr leicht und klug gestörte Inputs (wie ein Bild, ein Text, ein Ton), die für den Menschen nicht wahrnehmbar sind, aber von einem Machine-Learning-Modell falsch klassifiziert werden.
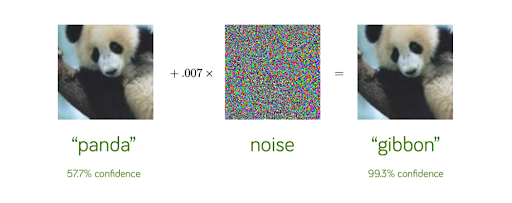
Das Verblüffende an diesen Angriffen ist die Sicherheit, die das Modell bei seiner falschen Vorhersage hat. Im obigen Beispiel ist es deutlich: Das Modell lässt für die richtige Vorhersage nur 57,7% Vertrauen zu, für die falsche Vorhersage hingegen ein sehr hohes Vertrauen von 99,3%. Wenn Du mehr über diese erstaunlichen Angriffe erfahren möchtest, kannst Du den entsprechenden Artikel lesen.
Diese Angriffe sind sehr problematisch. Beispielsweise zeigt ein 2019 in Science veröffentlichter Artikel von Forschenden der Harvard University und des MIT, wie medizinische KI-Systeme anfällig für feindliche Angriffe sein könnten. Aus diesem Grund ist es notwendig, sich zu verteidigen. An dieser Stelle kommt das Adversarial Training ins Spiel. Es ist neben der „Defensive Distillation“ die wichtigste Technik, um sich vor solchen Angriffen zu schützen.
Wie funktioniert das Adversarial Training?
Wie funktioniert diese Technik? Es geht darum, das Machine-Learning-Modell mit vielen Adversarial Examples neu zu trainieren. Wenn der Input vom Machine-Learning-Modell in der Trainingsphase eines Vorhersagemodells nämlich falsch klassifiziert wird, lernt der Algorithmus aus seinen Fehlern und passt seine Parameter neu an, mit dem Ziel, diese Fehler nicht mehr zu begehen.
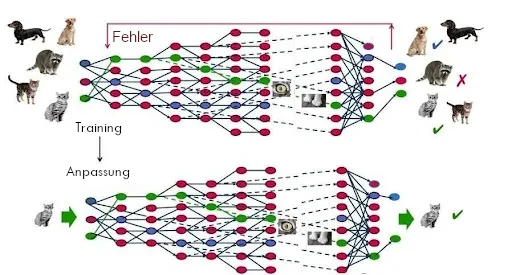
Nachdem das Modell also ein erstes Mal trainiert wurde, werden die Entwickler des Modells zahlreiche Adversarial Examples generieren. Sie werden ihr eigenes Modell mit diesen widersprüchlichen Beispielen konfrontieren, damit es diese Fehler nicht mehr macht.
Wenn diese Methode die Machine-Learning-Modelle gegen bestimmte Adversarial Examples verteidigt, kann sie dann die Robustheit des Modells auf alle Adversarial Examples verallgemeinern? Leider nicht. Dieser Ansatz reicht insgesamt nicht aus, um alle Angriffe zu stoppen, da das Spektrum der möglichen Angriffe zu weit ist und nicht im Voraus generiert werden kann. Daher handelt es sich oft um einen Wettlauf zwischen Hackern, die neue adversarial examples generieren, und Entwicklern, die sich so schnell wie möglich davor schützen.
Allgemeiner gesagt ist es sehr schwierig, Modelle vor Adversarial Examples zu schützen, da es nahezu unmöglich ist, ein theoretisches Modell der Entwicklung dieser Beispiele zu erstellen. Hierbei müssten besonders komplexe Optimierungsprobleme gelöst werden, und wir verfügen nicht über die notwendigen theoretischen Werkzeuge.
Alle bisher getesteten Strategien scheitern, weil sie nicht anpassungsfähig sind: Sie können eine Art von Angriff blockieren, lassen aber eine andere Schwachstelle für einen Angriff offen, der die verwendete Verteidigung kennt. Die Entwicklung einer Verteidigung, die vor einem starken, anpassungsfähigen Hacker schützen kann, ist ein wichtiges Forschungsgebiet.
Zusammenfassend lässt sich sagen, dass das Adversarial Training insgesamt beim Schutz von Machine-Learning-Modellen vor Adversarial Attacks versagt. Diese Technik bietet eine Verteidigung gegen eine Reihe von bestimmten Angriffen, ohne dass es ihr gelingt, eine allgemeine Methode herauszuarbeiten. Möchtest Du mehr über die Herausforderungen der künstlichen Intelligenz erfahren? Möchtest Du die in diesem Artikel erwähnten Techniken des Deep Learning beherrschen? Informiere Dich über unsere Weiterbildung







