In einem Datensatz gibt es zwei Arten von Variablen: quantitative Variablen, die Mengen messen (z. B. Größe, Preis), und qualitative oder kategoriale Variablen, die eher Kategorien oder Modalitäten bestimmen (z. B. Geschlecht, Farbe). Da Machine Learning auf verschiedenen mathematischen Operationen beruht, ist es entscheidend, unsere kategorialen Variablen in numerische Werte umzuwandeln oder besser gesagt zu kodieren, damit sie von unseren Modellen verarbeitet werden können. Dies geschieht in der Phase der Datenvorverarbeitung, auch "Preprocessing" genannt.
Die Python-Bibliothek category encoders bietet, wie der Name schon sagt, eine Vielzahl von Kodierungstechniken für unsere Variablen. Wie jede andere Bibliothek wird sie mit dem Befehl pip install category_encoders installiert und mit import category_encoders as ce importiert.
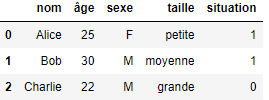
In diesem Artikel werden wir uns einige der vielen Kodierungstechniken ansehen, die diese Bibliothek anbietet. Wir betrachten auch das folgende DataFrame als Beispiel. Dieses DataFrame enthält fünf Spalten: drei kategoriale Variablen (Name, Geschlecht und Größe) und zwei quantitative Variablen (Alter und Status).
Die Zielvariable, die wir vorhersagen wollen, ist die berufliche Situation, die in der gleichnamigen Spalte eingetragen ist: Sie hat den Wert 1, wenn die Person beschäftigt ist, und 0, wenn sie arbeitslos ist.
One-Hot Encoding
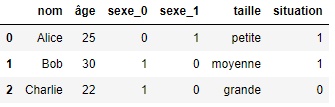
Beginnen wir mit der Kodierungsmethode, die wahrscheinlich am häufigsten verwendet wird. Bei jeder zu kodierenden Spalte wird sie durch One-Hot Encoding in X Spalten aufgeteilt, wobei X die Anzahl der unterschiedlichen Werte ist. Wenden wir One-Hot Encoding auf die Spalte „Geschlecht“ in unserem DataFrame an:

Wie wir feststellen können, wurde die Spalte „Geschlecht“ in die beiden Spalten „Frau“ und „Mann“ aufgeteilt. Ebenso sind die Werte in dieser Spalte nun binär: 1, wenn das Geschlecht in der Spalte mit der untersuchten Person übereinstimmt, 0 sonst.

Binäre Kodierung
Die binäre Kodierung funktioniert fast genauso wie die One-Hot-Kodierung: Sie teilt die zu kodierende Spalte in X verschiedene Spalten auf, deren Werte binär sind. Der Unterschied liegt hier in den Werten: Während die One-Hot-Kodierung die Werte ohne besondere Reihenfolge auf 0 oder 1 setzt, zählt die Binärkodierung die Werte zur Basis 2. Sehen wir uns das mit demselben DataFrame an:
Wenn wir wie oben zwei getrennte Spalten für das Geschlecht erhalten, haben die Werte nicht die gleiche Bedeutung. Die binäre Kodierung zählt den Wert „F“, der an erster Stelle steht, als die Zahl 1 (01 zur Basis 2) und den Wert „M“ als die Zahl 2 (10 zur Basis 2).
Tatsächlich können die One-Hot- und Binärcodierungen als Teilmenge einer anderen Codierungsart betrachtet werden, die von category_encoders unterstützt wird: die N-Base-Codierung. Diese Kodierung ermöglicht es, unsere kategorialen Variablen in Tabellenform in ihre N-Base-Äquivalente umzuwandeln. Wenn also die binäre Kodierung einer Base-2-Kodierung entspricht, kann der One-Hot als Base-1-Kodierung betrachtet werden.
Die Ordinalkodierung
Innerhalb der kategorialen Variablen gibt es eine Unterkategorisierung, die wir bisher noch nicht erwähnt haben. Im Allgemeinen werden kategoriale Variablen als „nominal“ bezeichnet, in dem Sinne, dass sie eine endliche Menge von Werten zulassen, die in keiner Beziehung zueinander stehen. In unserem DataFrame zum Beispiel sind die Variablen „Name“ und „Alter“ nominal, da sie 3 bzw. 2 Werte enthalten, die in keiner Beziehung zueinander stehen.
Wenn diese kategorialen Variablen jedoch eine Ordnungsbeziehung zwischen ihren Werten zulassen, werden sie als „ordinal“ bezeichnet. Das kann eine Erwähnung in einer Prüfung, eine Platzierung in einem Wettbewerb, eine Altersgruppe usw. sein. In unserem Beispiel ist die Variable „Körpergröße“ eine ordinale Variable, da ihre Werte in eine Rangfolge gebracht werden können: klein > mittel > groß.
Für die Verarbeitung von ordinalen Variablen ist daher die Ordinalkodierung besser geeignet, da sie die bei der Kodierung der Werte erstellte Rangfolge berücksichtigt und beibehält. Wenden wir eine ordinale Kodierung auf unseren DataFrame in der Spalte „Größe“ an:
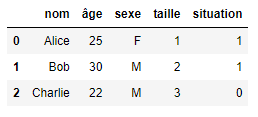
Wie wir sehen können, haben wir nicht nur die Spaltenwerte numerisch umgewandelt, sondern auch die Hierarchie unserer Größen gut beibehalten!

Die Zielkodierung
In jedem Machine-Learning-Modell gibt es eine Zielvariable, die wir über dieses Modell vorhersagen wollen. In unserem Beispiel ist dies die berufliche Situation. Daher kann es sinnvoll sein, eine Kodierung auf unsere kategorialen Variablen anzuwenden, die, anstatt ihnen einen bestimmten numerischen Wert zu geben, diesen auf der Grundlage der Zielvariablen berechnet. Hier kommt die Zielkodierung oder „target encoder“ zum Einsatz!
Die Zielkodierung übersetzt kategoriale Variablen, indem sie den Mittelwert der entsprechenden Zielvariablen für jede Kategorie berechnet, die sich von der kategorialen Variable unterscheidet, die wir kodieren wollen.
Wenden wir diese Kodierung auf die Spalten Geschlecht und Größe in unserem Beispiel-DataFrame an, wobei wir klarstellen, dass unsere Zielvariable die Spalte „Situation“ ist:
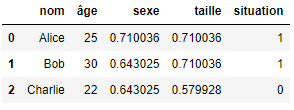
Hier nimmt jeder Wert in den Spalten Geschlecht und Größe gut einen numerischen Wert an, der als Mittelwert der Zielvariablen Situation berechnet wird. Die allgemeine Berechnung für jede einzelne Kategorie in den Kategorienspalten wird wie folgt durchgeführt:

Diese Berechnung ergibt eine numerische Darstellung jeder kategorialen Kategorie, die auf dem Mittelwert der mit dieser Kategorie verbundenen Zielvariablen basiert. Diese codierten Werte können dann als Merkmale in einem Machine-Learning-Modell verwendet werden.
Fazit
Die category_encoders-Bibliothek bietet eine große Auswahl an Werkzeugen, um kategoriale Variablen in numerische Werte zu kodieren.
Während wir hier vier Methoden vorgestellt haben, unterstützt category_encoders etwa 15 verschiedene Kodierungstechniken, die in verschiedenen Situationen eingesetzt werden können!

Um ein Experte in der Datenkodierung zu werden, solltest du unbedingt die von DataScientest angebotenen Data Scientist & Data Analyst-Trainings absolvieren!







