
GDie Leistung eines Machine-Learning-Algorithmus steht in direktem Zusammenhang mit seiner Fähigkeit, ein Ergebnis vorherzusagen. Wenn man versucht, die Ergebnisse eines Algorithmus mit der Realität zu vergleichen, verwendet man eine Konfusionsmatrix. In diesem Artikel erfährst du, wie du diese Matrix lesen kannst, um die Ergebnisse eines Klassifikationsalgorithmus zu interpretieren.
Was genau ist eine Confusion matrix?
Beim Machine Learning wird ein Algorithmus mit Daten gefüttert, damit er selbstständig lernt, eine bestimmte Aufgabe zu erledigen. Bei Klassifikationsproblemen sagt er Ergebnisse voraus, die mit der Realität verglichen werden müssen, um seinen Leistungsgrad zu messen. Normalerweise wird die Konfusionsmatrix, auch Kontingenztabelle genannt, verwendet. Sie hebt nicht nur die richtigen und falschen Vorhersagen hervor, sondern gibt uns vor allem einen Hinweis auf die Art der Fehler, die gemacht wurden. Um eine Konfusionsmatrix zu berechnen, benötigt man einen Testdatensatz und einen Validierungsdatensatz, der die Werte der erzielten Ergebnisse enthält.
Jede Spalte der Tabelle enthält eine vom Algorithmus vorhergesagte Klasse und die Zeilen der tatsächlichen Klassen.
Wir teilen die Ergebnisse in vier Kategorien ein:
- True Positive (TP): Sowohl die Vorhersage als auch der tatsächliche Wert sind positiv.
Beispiel: Eine kranke und eine erwartete kranke Person.
- True Negative (TN): Die Vorhersage und der tatsächliche Wert sind negativ.
Beispiel: Eine gesunde Person und eine geplante gesunde Person.
- False Positive (FP): Die Vorhersage ist positiv, während der tatsächliche Wert negativ ist.
Beispiel: Eine gesunde Person und eine geplante kranke Person.
False Negative (FN): Die Vorhersage ist negativ, während der tatsächliche Wert negativ ist.
Beispiel: Eine kranke und eine geplante gesunde Person.

Natürlich kann man dieser Matrix in komplizierteren Fällen Zeilen und Spalten hinzufügen.
Beispiel: Nach der Anwendung eines Vorhersagemodells erhalten wir folgende Ergebnisse
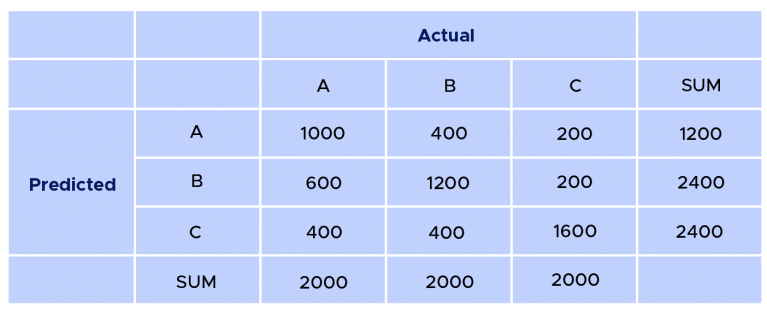
Generell gilt, dass die richtigen Vorhersagen immer auf der Diagonalen zu finden sind.
Wir haben hier also :
- 600 Individuen wurden als Klasse A eingestuft, von insgesamt 2000 Individuen, was ziemlich wenig ist.
- Bei den Individuen der Klasse B wurden 1.200 von 2.000 tatsächlich als zu dieser Klasse gehörig identifiziert.
- Bei den Individuen der Klasse C wurden 1.600 von 2.000 gut identifiziert.
- Die Zahl der True Positive (TP) liegt also bei 3.400.
Um die Zahl False Positive (FP),True Negative (TN),False Negative (FN) zu erhalten. Es ist in dieser Tabelle nicht möglich, sie direkt zu berechnen, daher müsste man sie in drei Fälle aufteilen:
- A und ( B und C)
- B und (A und C)
- C und (A und b)
So kann man alle Metriken berechnen, die man für die Analyse dieser Tabelle benötigt.
Hier findest du die gängigsten Methoden, um interessante Informationen aus einer solchen Tabelle zu ziehen:
- Accuracy
- Präzision
- Negative Predictive Value
- Spezifität
- Sensitivität
In der Praxis gibt es in Python eine sehr einfache Möglichkeit, über die Funktion classification_report der sklearn-Bibliothek auf alle diese Metriken zuzugreifen.
Beispiel:
Dies führt zu folgendem Ergebnis:
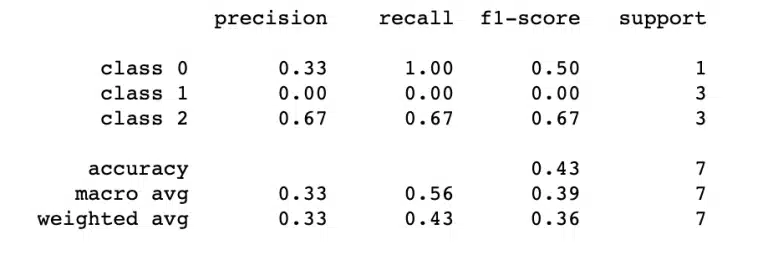
Welche Metriken verwenden wir, um unsere Vorhersagen zu bewerten?
In diesem Fall haben wir uns dafür entschieden, die verschiedenen Klassen nach den Werten von y_true zu benennen. Wir sehen dann verschiedene Metriken, die es uns ermöglichen, die Qualität unserer Vorhersagen zu beurteilen:
- Präzision
- Recall
- F1-Score
Deren Formeln lauten jeweils :


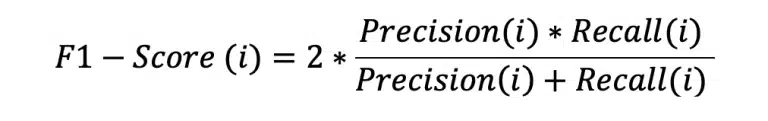
In unserem Fall kann man eine Genauigkeit von 0 für die Klasse 1 beobachten. Das liegt einfach daran, dass keine Person aus der tatsächlichen Klasse 1 als Mitglied dieser Klasse vorhergesagt wurde. Im Gegensatz dazu haben die Individuen der Klasse 2, bei denen 2 von 3 Individuen, die der Klasse 2 zugeordnet wurden, richtig zugeordnet wurden, eine Genauigkeit von 0,67.
Die Unterschiede zwischen Micro-Average und Macro-Average
Die Berechnung und Interpretation dieser Mittelwerte unterscheidet sich leicht.
Unabhängig von der verwendeten Metrik wird bei einem Makro-Mittelwert der Mittelwert aus der Berechnung der Metrik unabhängig von den Klassen gebildet. Im Gegensatz dazu berücksichtigt ein Mikro-Mittelwert die Beiträge jeder Klasse, um die durchschnittliche Metrik zu berechnen.
Bei einer Klassifizierung mit mehreren Klassen wird dieser Ansatz oft bevorzugt, wenn man ein Ungleichgewicht zwischen den Klassen vermutet (Anzahl, Bedeutung …).
Beispiel:
Dies führt zu folgendem Ergebnis:
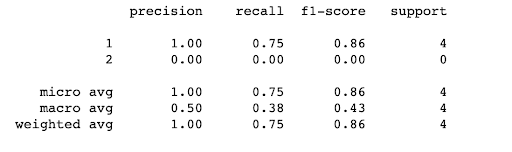
Du weißt jetzt, wie du die Ergebnisse eines Klassifikationsalgorithmus lesen und interpretieren kannst.
Wenn du mehr darüber erfahren möchtest, kannst du dir unsere Kurse Data Analyst, Data Scientist und Data Manager ansehen, in denen diese Konzepte anhand konkreterer Fälle wiederholt werden.







