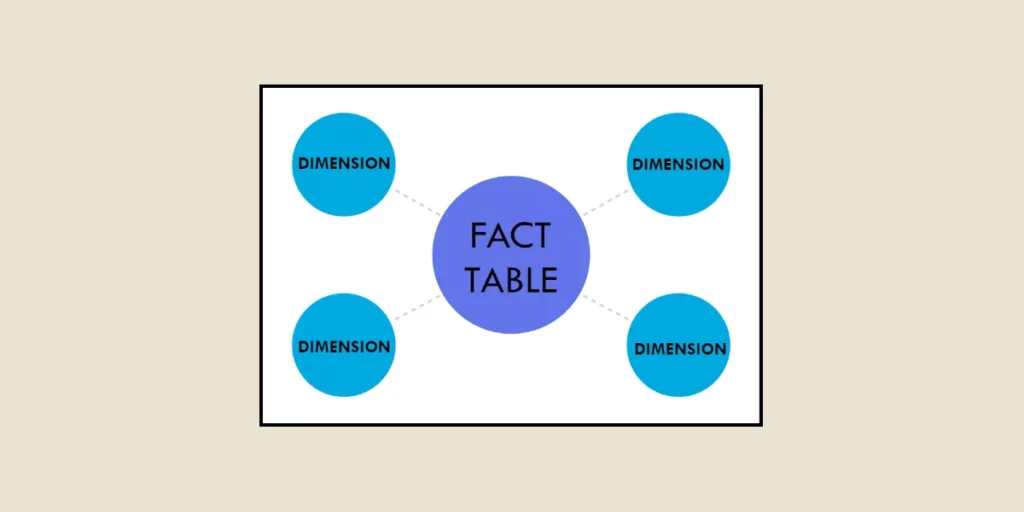
In der Datenwissenschaft und speziell in Data Warehouses sind die Begriffe Dimensionstabelle und Faktentabelle zentrale Konzepte in jedem Datenmodell, insbesondere für Analysezwecke.

Rückblick: Was ist ein Data Warehouse?
Was ist eine Dimensionstabelle?
Eine Dimension ist eine Tabelle, die qualitative Attribute eines wichtigen Elements des Unternehmensprozesses speichert. Diese Attribute werden verwendet, um die numerischen Fakten zu beschreiben, die in den Faktentabellen erfasst werden.
Dimensionen liefern somit Kontext für die quantitativen Messungen. Sie bieten Details zu Ereignissen, etwa wer, wann, wo oder welches Produkt verkauft wurde.
Diese Attribute können Elemente wie Produkt, Datum, Kunde oder sogar Ort umfassen. Diese Tabellen sind so organisiert, dass die Datenanalyse intuitiver wird, was das Verständnis der Faktentabellen, die ihrerseits die quantitativen Messungen enthalten, erleichtert.
Die verwendeten Schema-Typen
Es gibt mehrere Modelle zur Organisation von Fakten- und Dimensionstabellen, insbesondere das Sternschema (star schema) und das Schneeflockenschema (snowflake schema).
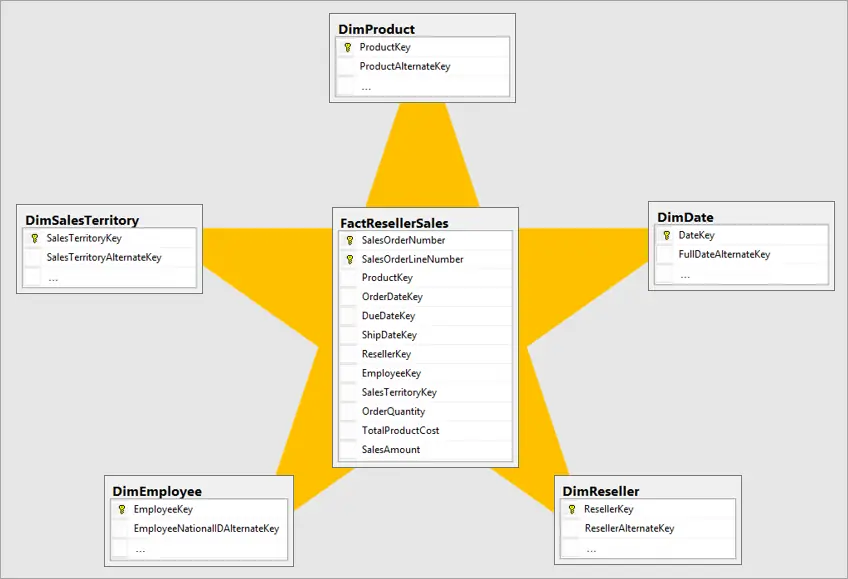
Sternschema (Star Schema)
Dieser Schema-Typ ist der einfachste und am häufigsten verwendete im Data Warehousing. Hier sind die Faktentabellen zentral platziert und mit den sie umgebenden Dimensionstabellen verbunden, wodurch eine sternförmige Struktur entsteht. Dies erleichtert die Datenanalyse, da die Beziehungen zwischen den Tabellen klar und nicht komplex sind. Es ist in der Regel die empfohlene Methode, wann immer möglich.
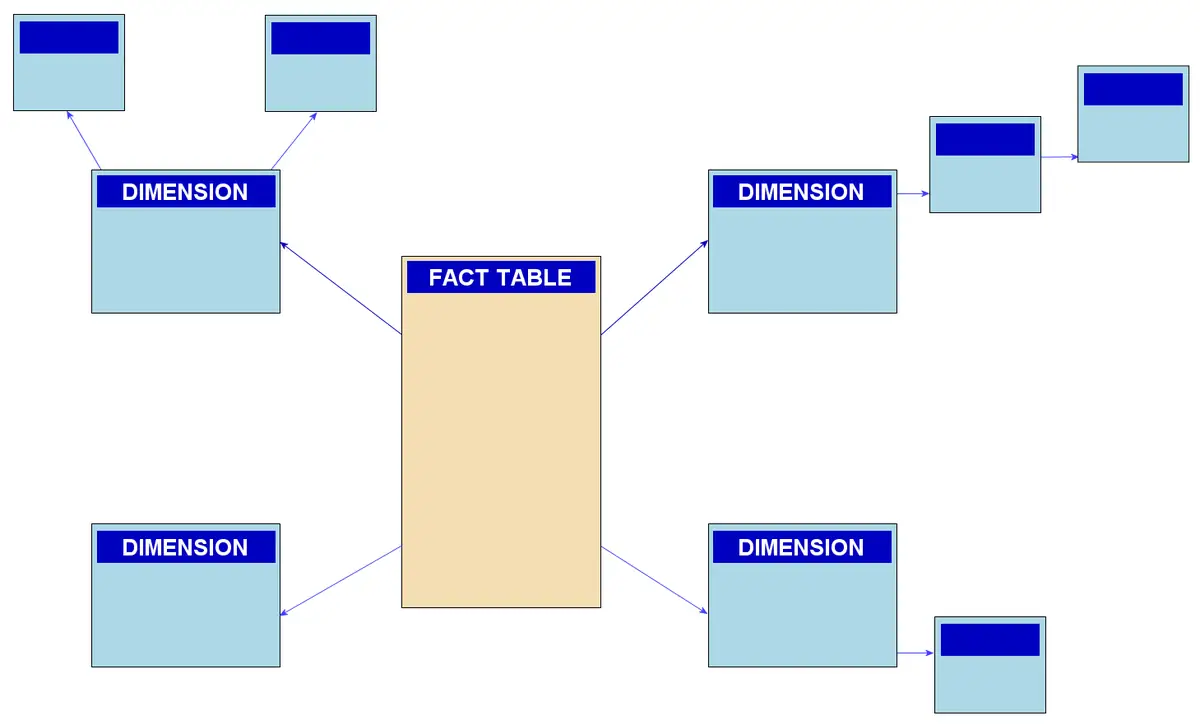
Schneeflockenschema (Snowflake Schema)
Das Schneeflockenschema ist eine Erweiterung des Sternschemas, bei dem die Dimensionstabellen über mehrere Ebenen normalisiert sind. Das bedeutet, dass die Attribute einer Dimension wiederum mit anderen Tabellen verbunden sind, was eine komplexere Struktur erzeugt, die einer Schneeflocke ähnelt. Dies reduziert die Datenredundanz, erhöht jedoch die Komplexität der Abfragen.
Primärschlüssel und Fremdschlüssel
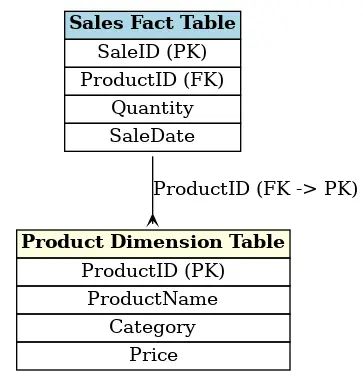
In einem dimensionalen Modell verfügen die Dimensionstabellen über einen Primärschlüssel (primary key), der jede Zeile eindeutig identifiziert. Dieser Primärschlüssel wird wiederum als Fremdschlüssel (foreign key) in der Faktentabelle verwendet, um eine Beziehung zwischen den Tabellen herzustellen.
Zum Beispiel kann eine Faktentabelle der Verkäufe (sales fact table) eine Spalte „ProductID“ haben, die als Fremdschlüssel auf den Primärschlüssel der Produkttabelle verweist. Diese Beziehungen ermöglichen es, Daten aus verschiedenen Tabellen zu kombinieren, um umfassende und detaillierte Analysen zu erhalten.
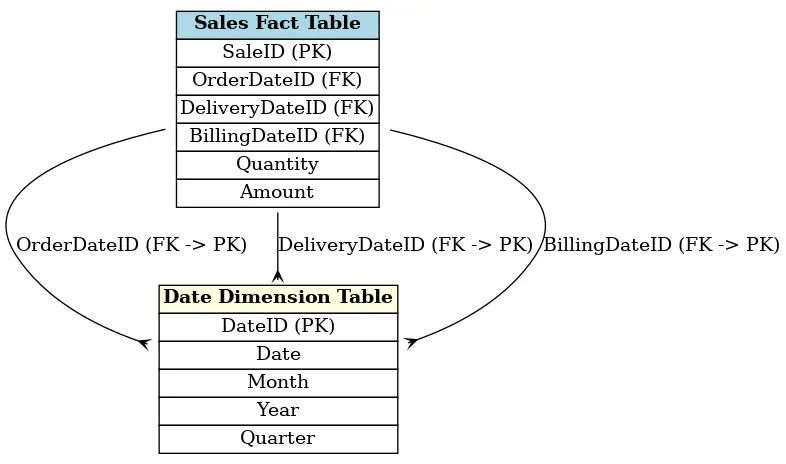
Role-Playing Dimensions
Manche Dimensionen können unterschiedliche Rollen im Datenmodell spielen. Zum Beispiel kann eine Datumsdimension verwendet werden, um das Bestelldatum, das Lieferdatum oder das Rechnungsdatum abzubilden. Man spricht dann von Role-Playing Dimensions. Dies ermöglicht es, Datenverdopplungen zu vermeiden, indem eine einzige Dimension für unterschiedliche Zwecke genutzt wird.
Langsam wechselnde Dimensionen (Slowly Changing Dimensions)
Dimensionen können sich im Laufe der Zeit ändern, und oft ist es notwendig, diese Änderungen im Data Warehouse zu verfolgen. Zum Beispiel kann ein Kunde seine Adresse ändern. Diese Änderungen müssen verwaltet werden, um nachvollziehen zu können, wann diese Modifikationen stattfanden und wie sie die Fakten beeinflussten.
Die Slowly Changing Dimensions (SCD) ermöglichen die Verwaltung dieser Art von Veränderungen. Es gibt mehrere Typen, insbesondere:
- Typ 1: Die Änderung ersetzt einfach den alten Wert.
- Typ 2: Eine neue Zeile wird für jede Änderung hinzugefügt, sodass die Historie beibehalten wird.
- Typ 3: Eine neue Spalte wird hinzugefügt, um den vorherigen Wert zu speichern.
Die Bedeutung der Dimensionen in der Datenanalyse
Die Dimensionen ermöglichen es, numerische Werte in verwertbare Informationen umzuwandeln. Sie helfen dabei, strategische Fragen im Kontext des Geschäftsprozesses zu beantworten, wie zum Beispiel:
- Welches Produkt verkauft sich am besten?
- Wer sind unsere besten Kunden?
- Welcher Zeitpunkt des Jahres ist der profitabelste?
Durch die Nutzung relevanter Dimensionen wie Produkt, Datum oder Kunde können Analysten Verkaufs- oder Produktionsdaten segmentieren und so eine genauere Sicht auf die Leistung des Unternehmens erhalten. Es ist diese Verbindung zwischen Fakten und Dimensionen, die eine fundierte Datenanalyse ermöglicht.
Schlussfolgerung
Dimensionen sind im Data Warehouse äußerst wichtig und sollten nicht unterschätzt werden, da sie helfen, den quantitativen Daten in den Faktentabellen eine Bedeutung zu verleihen. Durch die Organisation der Daten mit Stern- oder Schneeflockenschemata, die Nutzung von Primär- und Fremdschlüsseln und die Nutzung von Role-Playing Dimensions kann ein Data Warehouse eine solide Grundlage für eine tiefgehende Datenanalyse bieten.







