Clustering ist eine spezielle Disziplin des Machine Learning, deren Ziel es ist, Ihre Daten in homogene Gruppen mit gemeinsamen Merkmalen aufzuteilen. Dies ist z. B. ein beliebter Bereich im Marketing, wo oft versucht wird, Kundenstämme zu segmentieren, um bestimmte Verhaltensweisen zu erkennen.
In einem früheren Artikel haben wir einen ersten Clustering-Algorithmus vorgestellt: den K-Mittelwert- oder K-Means-Algorithmus.
In diesem Artikel werden wir die Funktionsweise des CAH-Algorithmus im Detail erläutern. Die Hierarchische Aufsteigende Klassifikation : CAH ist ein sehr bekannter unüberwachter Algorithmus für das Clustering.
Die Anwendungsbereiche sind vielfältig: Kundensegmentierung, Datenanalyse, Segmentierung eines Bildes, semi-überwachtes Lernen….
Das Prinzip
Wenn Punkte und eine ganze Zahl k gegeben sind, zielt der Algorithmus darauf ab, die Punkte in k homogene und kompakte Gruppen, sogenannte Cluster, zu unterteilen.
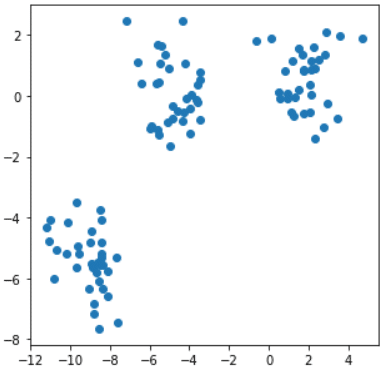
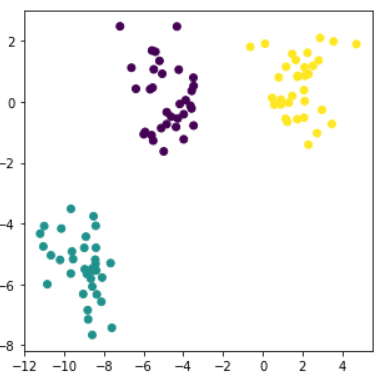
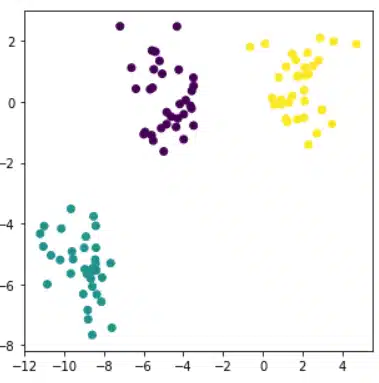
Sehen wir uns das folgende Beispiel an: clusters clusters Auf diesem 2D-Datensatz wird deutlich, dass er in drei Gruppen unterteilt werden kann. Wie geht man konkret vor?
- Die Grundidee ist, dass Sie jeden Punkt in Ihrem Datensatz als Zentroid betrachten. Das bedeutet, dass jedem Punkt eine eindeutige Bezeichnung (0,1,2,3, 4…) zugeordnet ist.
- Dann gruppieren wir jeden Zentroid mit seinem nächsten benachbarten Zentroid. Dieser nimmt das Etikett des Zentroiden an, der ihn „absorbiert“ hat.
- Dann werden die neuen Zentroiden berechnet, die die Schwerpunkte der neu geschaffenen Cluster sein werden.
- Dies wird so lange wiederholt, bis ein einzelner Cluster oder eine zuvor festgelegte Anzahl von Clustern vorliegt.
In unserem Beispiel ist die optimale Anzahl von Clustern 3 und das Endergebnis ist in der Abbildung rechts zu sehen.

Um den Mechanismus besser zu verstehen, kann man ihn mit einem einfachen Schema darstellen: 2D-Datensatz Zu Beginn wird jeder Buchstabe als Cluster betrachtet, dann werden sie nach und nach entsprechend ihrer Nähe gruppiert, um am Ende nur noch eine einzige Gruppe zu bilden: abcdef.
Der Begriff der Distanz und des Kriteriums
Wie Du vielleicht verstanden hast, sind in diesem Algorithmus drei Punkte entscheidend:
- Welche Metrik wird verwendet, um den Abstand zwischen Zentroiden zu bewerten? Welche Anzahl von Clustern ist zu wählen?
- Nach welchem Kriterium wird entschieden, ob die Zentroiden untereinander gruppiert werden?
Bei der hierarchischen aufsteigenden Klassifikation wird in der Regel die euklidische Distanz verwendet, d. h. p = (p1,….,pn) und q = (q1,….,qn) als euklidische Distan.
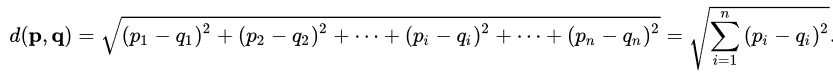
Sie ermöglicht es, die Entfernung zwischen den Zentroiden zu bewerten. Bei jedem Schritt der Gruppierung zwischen zwei Zentroiden erhält man ein neues Cluster und einen neuen Zentroiden, der nichts anderes ist als der Schwerpunkt der Punktwolke, wie oben erklärt.
Hier kommt der Begriff der klasseninternen Trägheit ins Spiel. Sie ist einfach die Summe der euklidischen Distanzen zwischen jedem Punkt, der mit dem Cluster verbunden ist, und dem neu berechneten Schwerpunkt. Wenn Du Cluster zusammenlegst, erhöht sich natürlich auch die Trägheit innerhalb der Klasse. Die Herausforderung besteht darin, diesen Anstieg so gering wie möglich zu halten. Wenn Du also die Wahl hast, ein Cluster mit vier oder fünf anderen Clustern zu gruppieren, wirst du das Cluster wählen, das den Zuwachs an Trägheit innerhalb der Klasse minimiert. Diese Methode ist das Prinzip des Ward-Kriteriums, das sehr oft für die hierarchische Klassifikation verwendet wird. Es gibt noch andere Kriterien, aber das Ward-Kriterium ist das standardmäßig verwendete Kriterium, wenn man eine HAC in Python mit Scikit Learn implementiert.
Im vorherigen Beispiel war es einfach, die ideale Anzahl von Clustern zu finden, indem man sie einfach grafisch darstellte. Normalerweise haben Datensätze mehr als zwei Dimensionen und es ist daher schwierig, die Punktwolke zu visualisieren und die optimale Anzahl von Clustern schnell zu identifizieren. Man kann die HAC entscheiden, indem man ihr vorher eine Anzahl von Clustern vorgibt.
Nehmen wir im vorherigen Beispiel an, dass wir die Daten vorher nicht visualisiert haben, und entscheiden uns, verschiedene Male mit einer unterschiedlichen Anzahl von Clustern zu testen. Hier sind die Ergebnisse, die wir erhalten haben:
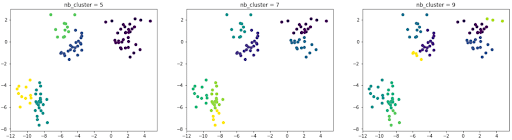
Die Partitionierung ist ungenau, denn die optimale Clusterzahl ist 3.
Eine bekannte Methode, um die optimale Clusterzahl zu finden, ist die Verwendung eines Dendrogramms wie das folgende:
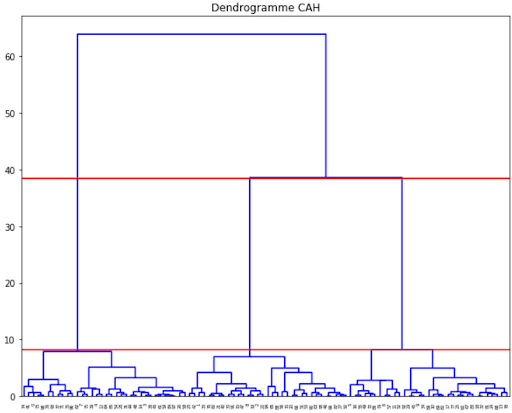
Er ermöglicht es, die aufeinanderfolgenden Clusterungen zu visualisieren, bis ein einziger Cluster entsteht.
Oft ist es sinnvoll, die Partitionierung zu wählen, die dem größten Sprung zwischen zwei aufeinanderfolgenden Clustern entspricht.
Die Anzahl der Cluster entspricht dann der Anzahl der vertikalen Linien, durch die der horizontale Schnitt des Dendrogramms verläuft.
In unserem Beispiel oben entspricht der horizontale Schnitt den beiden roten Linien.
Es gibt drei vertikale Linien, durch die der Schnitt verläuft. Daraus folgt, dass die optimale Anzahl von Clustern 3 ist.
Python in der Praxis
Das Trainieren einer Hierarchischen Aufsteigenden Klassifikation wird mit der Bibliothek Scikit-Learn erleichtert.
Ein Datensatz wie der, der als Beispiel diente, kann leicht mit der Funktion make_blobs von Scikit-Learn erstellt werden.
Sobald wir unseren Datensatz erzeugt haben, können wir mit der Implementierung einer HAC fortfahren. Wir werden die Bibliothek Scikit-Learn verwenden.
Hier ist, wie sie in Code implementiert wird :
Mit dem Attribut n_clusters wird die gewünschte Anzahl an Clustern für die Klassifizierung angegeben. Standardmäßig wird die euklidische Distanz verwendet. Auch das „Clusterkriterium“, das als Linkage bezeichnet wird, ist standardmäßig das Ward-Kriterium.
Die Grenzen der Hierarchischen Aufsteigenden Klassifizierung
Wie wir gesehen haben, muss der Algorithmus zunächst die Anzahl der Partitionen festlegen.
Das erfordert eine genaue Vorstellung davon, und auch wenn wir eine Methode gesehen haben, um für bestimmte Datensätze zu optimieren, ist sie nicht unfehlbar. Datenmengen mit elliptischen Formen zum Beispiel werden Probleme bereiten.
Im folgenden Beispiel sehen wir deutlich zwei Gruppen, die zwei Ellipsen ähneln. Die Abbildung rechts zeigt das Ergebnis nach der Verwendung einer HAK. Es ist klar, dass diese es nicht geschafft hat, unsere beiden Ellipsen zu identifizieren.
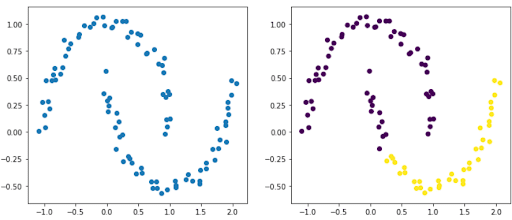
Auch die hierarchische Bottom-up-Klassifizierung kann schnell sehr zeit- und ressourcenintensiv werden. Eine Möglichkeit, dieses Problem zu umgehen, ist das Ausfüllen einer Konnektivitätsmatrix. Die Konnektivitätsmatrix ist eine hohle Matrix, die angibt, welche Beobachtungspaare benachbart sind.
Die Verwendung eines Clustering-Algorithmus wie der Hierarchischen Aufsteigenden Klassifikation ist je nach den dir zur Verfügung stehenden Daten nicht einfach. Oftmals musst du deine Daten überarbeiten. Bei Datascientest bringen wir dir bei, die wichtigsten Clustering-Algorithmen zu beherrschen und sie anhand von Datensätzen zu interpretieren.
Schulung in CAH-Algorithmen
Entdeck unsere Schulungsangebote zu besuchen, um zu lernen, wie man Clustering-Algorithmen beherrscht, aber auch in vielen anderen Bereichen des Machine Learning.







