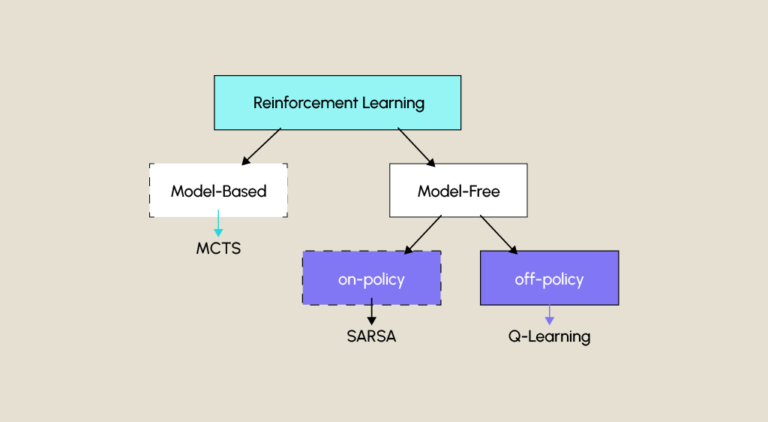
Reinforcement Learning ist neben dem überwachten und dem unüberwachten Lernen eine der drei großen Techniken des maschinellen Lernens. Eine Unterkategorie ist SARSA.
Diese Algorithmus-Familie hat in den letzten Jahren viel Aufmerksamkeit erregt, z. B. durch die innovativen Produkte der Firma OpenAI, wie OpenAI Five, eine KI, die es geschafft hat, ein Team von professionellen Spielern im Videospiel Dota 2 zu besiegen, oder das berühmte ChatGPT, das diese Technik zur Anpassung seiner Einstellungen verwendet.
Was ist Reinforcement Learning?
Das Lernen durch Verstärkung bzw. Reinforcement Learning ist ein Bereich des maschinellen Lernens, in dem ein Agent (virtuelle Entität: Roboter, Programm…) in eine interaktive Umgebung gesetzt wird, in der er lernen muss, Handlungen auszuführen, die quantitative Belohnungen maximieren.
Was ist der SARSA-Algorithmus?
SARSA ist ein Lernalgorithmus, dessen Name vom englischen State-Action-Reward-State-Action abgeleitet ist, was Staat-Aktion-Reward-Staat-Aktion bedeutet und die Folge von Elementen bezeichnet, aus denen dieser Algorithmus besteht. Es handelt sich um einen Algorithmus, der auf einer Aktionswerttabelle (oder Q-Tabelle, wobei Q das Maß für die Qualität einer ausgeführten Aktion darstellt) basiert, die jedem Zustand-Aktions-Paar einen Wert zuweist, der die erwartete Belohnung darstellt.
Ablauf des Algorithmus
Die verschiedenen Schritte, die diesen Algorithmus ausmachen, kannst du am Beispiel eines Zustellers veranschaulichen, der ein Paket von A nach B bringen muss.

Zunächst wird die Q-Tabelle mit Null-Werten initialisiert. Danach können die verschiedenen Schritte von SARSA beginnen:
- Der Algorithmus befindet sich in einem S-Zustand (Der Lieferant kennt seine Entfernung zu Punkt B).
- Du wählst eine Aktion A aus, die du ausführen möchtest, indem du entweder dein Wissen nutzt oder neue Möglichkeiten erkundest (Der Lieferant kommt von Norden her an eine Kreuzung und kennt die Straße nach Süden, also folgt er dieser Straße).
- Du erhältst eine R-Belohnung (der Zusteller gewinnt 1 Minute, wenn seine Wahl ihn näher an Punkt B bringt, verliert aber 5 Minuten, wenn er sich davon entfernt).
- Zu diesem Zeitpunkt wird die Q-Tabelle mithilfe der Formel Q[état_1, action_1] = (1-α) * Q[état_1, action_1] + α * (r + γ * Q[état_2, action_2]) mit aktualisiert.
- Die Alpha- oder α-Lernrate, die das Ausmaß der Aktualisierung steuert. Wenn α = 0 ist, lernt man nichts, wenn α = 1 ist, lernt man, indem man vergisst, was zuvor gelernt wurde.
- Die Belohnung, die r erhält, nachdem du eine Handlung zu einem bestimmten Zeitpunkt ausgeführt hast.
- Der Aktualisierungsfaktor gamma oder γ, der zukünftige Belohnungen gewichtet.
- Der Algorithmus befindet sich in einem neuen Zustand S (der Zusteller kennt seine neue Entfernung von Punkt B).
- Du entscheidest dich, eine neue Aktion A durchzuführen
Diese Schritte werden so lange wiederholt, bis der Algorithmus konvergiert (bis der Lieferant bei Punkt B ankommt).
Dieser Algorithmus wird „on-policy“ genannt, was bedeutet, dass die Politik, die zur Bestimmung der Aktionen verwendet wird, die gleiche ist, die auch die Werte in der Q-Tabelle aktualisiert. SARSA verwendet normalerweise eine ε-greedy-Politik, wobei ε ein Parameter ist, der die Wahrscheinlichkeit von Exploration (zufällige Auswahl von Aktionen) im Vergleich zu Exploitation (Auswahl der besten Aktion gemäß der Q-Tabelle) bestimmt. Diese Eigenschaft unterscheidet ihn von „Off-Policy“-Algorithmen wie Q-Learning.
Fazit
Zusammenfassend lässt sich sagen, dass SARSA ein verstärkender Lernalgorithmus ist, der darauf abzielt, einem Agenten anhand einer iterativ aktualisierten Q-Tabelle beizubringen, welche Entscheidungen er in einer Umgebung zu treffen hat. Er verfolgt eine Politik der Erkundung und Ausbeutung, während er mit der Umgebung interagiert, und wird in verschiedenen Bereichen wie Videospielen, der Entscheidungsfindung in der Robotik oder der Lösung von Problemen bei der Routenplanung eingesetzt.

Wenn du dich in diesem Bereich weiterbilden möchtest, dann schau dir unsere Weiterbildung zum Data Scientist an.







