Die zahlreichen Fortschritte in NLP ermöglichen es bis heute, es auf zahlreiche Aufgaben anzuwenden: Übersetzung, Texterzeugung, Zusammenfassung … In diesem Artikel wollen wir uns mit einem einfachen Aspekt der Zusammenfassung befassen: der extraktiven Zusammenfassung. Dabei handelt es sich nicht um eine zusammenfassende Zusammenfassung, sondern vielmehr um eine Extraktion der interessantesten, bedeutungstragenden Sätze.
Dazu werden wir den Begriff TF-IDF einführen, der im Mittelpunkt des Algorithmus zum Zusammenfassen steht, und dann Schritt für Schritt die Schritte untersuchen, die zum Zusammenfassen führen.
Was ist TF-IDF? Definition
Term Frequency – Inverse Document Frequency ist ein Maß, mit dem man aus einer Reihe von Texten die relative Bedeutung der einzelnen Wörter ablesen kann.
Eine schlechte Idee wäre es zu glauben, dass ein Wort umso wichtiger in einem Satz ist, je häufiger es vorkommt.
Dies würde jedoch dazu führen, dass man sich sehr schnell mit Schlüsselwörtern wie „der“, „du“, „a“… wiederfindet, die alles andere als nützlich sind! TF-IDF ermöglicht es, dies zu korrigieren.
Stelle dir vor, dass wir eine Reihe von Texten haben (z. B. alle Werke von Goethe). Und wir wollen die wichtigsten Wörter aus seinen Werken extrahieren.
TF dient dazu, die relative Bedeutung eines Wortes in einem Dokument zu messen. Sie ist definiert durch die Formel

wobei {i das Wort und j das Dokument Lj die Gesamtzahl der Wörter im Text j Freqi,j die Häufigkeit des Wortes i in Dok j
i das Wort und j das Dokument Lj die Gesamtzahl der Wörter im Text j Freqi,j die Häufigkeit des Wortes .
IDF misst die Bedeutung eines Begriffs nicht anhand seiner Häufigkeit in einem bestimmten Dokument, sondern anhand seiner Verteilung und Verwendung in der Gesamtheit der Dokumente. Je mehr Potenzial ein Begriff hat, desto höher ist die Inverse Document Frequency.
Im Idealfall kommt ein Begriff sehr häufig in nur wenigen Texten vor. Wörter, die in fast allen Dokumenten oder nur sehr selten vorkommen, sind von geringer Bedeutung. Die Punktzahl erhält man durch folgende Formel:

wobei {ND die Gesamtzahl der Dokumente im Korpus fi die Anzahl der Dokumente, in denen das Wort i vorkommt
Wir nehmen den Logarithmus, da bei einem großen Korpus der Wert dieses Terms explodieren kann.
Nachdem die beiden Terme berechnet wurden, berechnet man seinen Wert durch :

Löschen, löschen
Der arbeits- und zeitaufwändigste Teil des NLP ist das Preprocessing – die Aufgabe, unser Dataset so zu bearbeiten, dass es effizient ausgewertet werden kann. Wir müssen daran denken, den Text so weit wie möglich zu harmonisieren, um dem Algorithmus die Arbeit zu erleichtern. Die wichtigsten Schritte für unsere Fallstudie sind :
- Sonderzeichen durch Leerzeichen ersetzen
- Ersetzen von zusätzlichen Räumen durch einen klassischen Raum
Hierzu verwenden wir die NLTK-Buchhandlung und Re.
TF-IDF berechnen
Die Berechnung in der Idee ist einfach, aber man muss dem Code Aufmerksamkeit schenken. Wir müssen zunächst ein Vokabular aus unserem gesamten Korpus erstellen. Dann muss man eine sogenannte count matrix erstellen, die für jedes Dokument das Vorkommen jedes Wortes zählt.
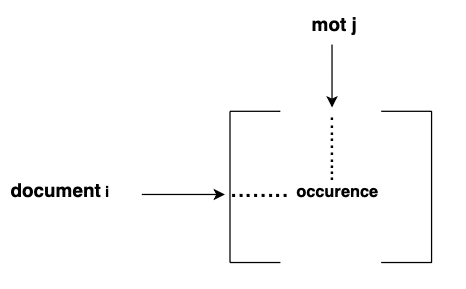
Nachdem diese Matrix erstellt wurde, kann man den TF-IDF-Score dieser Matrix berechnen.
Am Ende wird ein Wörterbuch erstellt, das jedem Wort den Wert TF-IDF zuordnet.
Die Zusammenfassung
Wir berechnen die Punktzahl für jeden Satz in den Dokumenten basierend auf dem TF-IDF-Wert jedes Wortes, aus dem der Satz besteht.
Wenn man die Punktzahl für jeden Satz erhalten hat, kann man eine Zusammenfassung eines Textes erstellen.
Hier ein Beispiel für das Ergebnis bei einem Text :

Die Zusammenfassung ist bereits von angemessener Qualität. Wie man sieht, brauchten wir nur ein paar Funktionen und durften uns nicht im Code verirren, um die Punktzahl für jedes Wort zu berechnen. Es ist alles eine Frage der Organisation.
Dennoch bleibt es eine recht klassische Zusammenfassung. Mit neuen Methoden wie Transformers oder klassischeren Methoden wie n-gram lassen sich echte Zusammenfassungen erstellen.
Allerdings wird es immer komplizierter und erfordert einen echten Hintergrund in Bezug auf Wissen und Anwendungen. Unser Kurs hat kürzlich Kurse zu diesen neuen Methoden eingeführt, damit die Teilnehmer ihre Projekte mit größerem Ehrgeiz umsetzen können.







